RNN,GRU,LSTM
2019-08-29 17:17:15
问题描述:比较RNN,GRU,LSTM。
问题求解:
- 循环神经网络 RNN
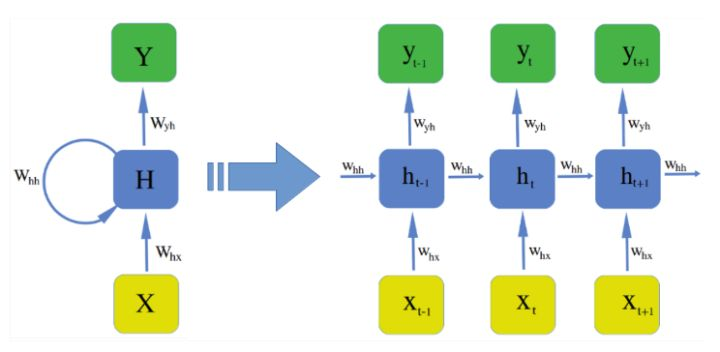
传统的RNN是维护了一个隐变量 ht 用来保存序列信息,ht 基于 xt 和 ht-1 来计算 ht 。
ht = g( Wi xt + Ui ht-1 + bi )
yt = g( Wo ht + bo )
- 门控循环神经网络 GRU
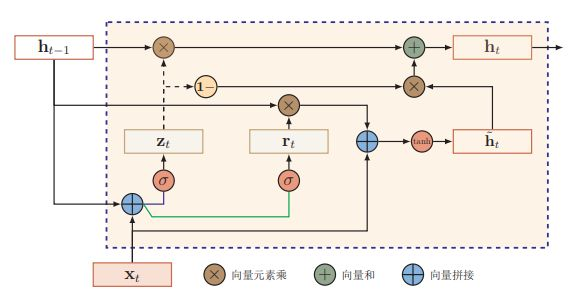
门控循环神经网络(Gated Recurrent Unit,GRU)中引入了门控机制。
Update:Γu = g( Wu xt + Uu ht-1 + bu )
ht~ = g( Wc xt + Uc ht-1 + bc ) -Candidate
ht = Γu * ht~ + Γf * ht-1
【注】实际使用中还会加入重置门,可以看成计算了 ht-1 和 xt 之间的相关性
Γr = g( Wr xt + Ur ht-1 + br )
ht~ = g( Wc xt + Γr Uc ht-1 + bc )
- 长短期记忆网络 LSTM
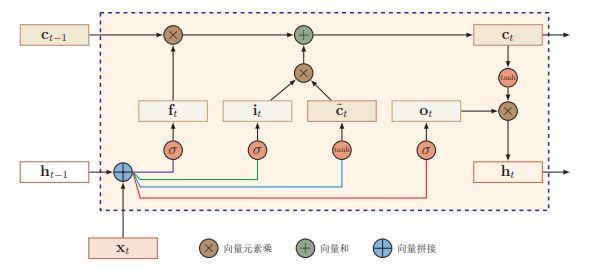
长短期记忆网络(Long Short Term Memory,LSTM)是循环神经网络的最知名和成功的扩展。由于循环神经网络有梯度消失和梯度爆炸的问题,学习能力有限,在实际的任务中往往不达预期。LSTM可以对有价值的信息进行长期记忆,从而减小循环神经网络的学习难度,因此在语音识别,NER,语言建模等问题中有着广泛的应用。
与传统的循环神经网络对比,LSTM仍然是基于xt 和 ht-1 来计算 ht ,只不过对计算的内部流程进行更加精心的设计。
LSTM中引入了cell memory称为 ct ,ht 由 cell memory生成。
LSTM在前向传播的时候不仅传递 ht ,而且还传递 cell memory,cell memory实际形成了一个信息的流通的highway。
LSTM中加入了三个门更新门(也有称为输入门) Γu,遗忘门 Γf,输出门 Γo。这里的门的概念可以理解为相关性,本质是三个权重。
Update:Γu = g( Wu xt + Uu ht-1 + bu )
Forget:Γf = g( Wf xt + Uf ht-1 + bf )
Output:Γo= g( Wo xt + Uo ht-1 + bo )
这三个门都是作用在cell memory上的,那么cell memory怎么计算呢?
ct~ = g( Wc xt + Uc ht-1 + bc )
ct = Γu * ct~ + Γf * ct-1
计算完成 ct 后,就可以根据输出门来求 ht 了。
ht = Γo * ct
RNN,GRU,LSTM的更多相关文章
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM
yi作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORK ...
- 【pytorch】关于Embedding和GRU、LSTM的使用详解
1. Embedding的使用 pytorch中实现了Embedding,下面是关于Embedding的使用. torch.nn包下的Embedding,作为训练的一层,随模型训练得到适合的词向量. ...
- 太深了,梯度传不下去,于是有了highway。 干脆连highway的参数都不要,直接变残差,于是有了ResNet。 强行稳定参数的均值和方差,于是有了BatchNorm。RNN梯度不稳定,于是加几个通路和门控,于是有了LSTM。 LSTM简化一下,有了GRU。
请简述神经网络的发展史sigmoid会饱和,造成梯度消失.于是有了ReLU.ReLU负半轴是死区,造成梯度变0.于是有了LeakyReLU,PReLU.强调梯度和权值分布的稳定性,由此有了ELU,以及 ...
- LSTM梳理,理解,和keras实现 (一)
注:本文主要是在http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 这篇文章的基础上理解写成,姑且也可以称作 The understan ...
- 自己动手实现深度学习框架-7 RNN层--GRU, LSTM
目标 这个阶段会给cute-dl添加循环层,使之能够支持RNN--循环神经网络. 具体目标包括: 添加激活函数sigmoid, tanh. 添加GRU(Gate Recurrent U ...
- 简易机器学习代码(LR,Kmeans,NN,RNN)
Logistic Regression 特别需要注意的是 exp 和 log 的使用. sigmoid 原始表达式为 1 / (1+exp(-z)),但如果直接使用 z=-710,会显示 overfl ...
- 使用LSTM做电影评论负面检测——使用朴素贝叶斯才51%,但是使用LSTM可以达到99%准确度
基本思路: 每个评论取前200个单词.然后生成词汇表,利用词汇index标注评论(对 每条评论的前200个单词编号而已),然后使用LSTM做正负评论检测. 代码解读见[[[评论]]]!embeddin ...
- 三步理解--门控循环单元(GRU),TensorFlow实现
1. 什么是GRU 在循环神经⽹络中的梯度计算⽅法中,我们发现,当时间步数较⼤或者时间步较小时,循环神经⽹络的梯度较容易出现衰减或爆炸.虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题.通常由于 ...
随机推荐
- 关于PHPExcel的一些资料
下面是总结的几个使用方法 include 'PHPExcel.php'; include 'PHPExcel/Writer/Excel2007.php'; //或者include 'PHPExcel/ ...
- Go基础学习(二)
数组[array] 数组定义[定义后长度不可变] 12 symbol := [...]string{USD: "$", EUR: "€", GBP: " ...
- USB小白学习之路(8)FX2LP cy7c68013A——Slave FIFO 与FPGA通信(转)
此博客转自CSDN:http://blog.csdn.net/xx116213/article/details/50535682 这个博客只对自己理解CY7C68013的配置有一定的帮助,对于配置CY ...
- python爬虫之字体反爬
一.什么是字体反爬? 字体反爬就是将关键性数据对应于其他Unicode编码,浏览器使用该页面自带的字体文件加载关键性数据,正常显示,而当我们将数据进行复制粘贴.爬取操作时,使用的还是标准的Unicod ...
- XXE学习(一)——XML基础
XXE学习(一)——xml基础 一.XML简介 XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据 ...
- 阿里云ECS开放批量创建实例接口,实现弹性资源的创建
摘要: 为了更方便的实现弹性的资源创建,方便用户一次运行多台ECS按量实例来完成应用的开发和部署,阿里云开放了ECS的批量创建实例接口RunInstances,可以单次最多创建100台实例,避免重复调 ...
- JZOJ 5235. 【NOIP2017模拟8.7A组】好的排列
5235. [NOIP2017模拟8.7A组]好的排列 (File IO): input:permutation.in output:permutation.out Time Limits: 1000 ...
- PySide2的This application failed to start because no Qt platform plugin could be initialized解决方式
解决PySide2的This application failed to start because no Qt platform plugin could be initialized问题 今天在装 ...
- mac 工具推荐
传送门: https://github.com/jaywcjlove/awesome-mac/blob/master/README-zh.md
- VUE二 生命周期详解
vue官网对vue生命周期的介绍 Vue实例有一个完整的生命周期,也就是从开始创建.初始化数据.编译模板.挂载Dom.渲染→更新→渲染.销毁等一系列过程,我们称这是Vue的生命周期.通俗说就是Vue实 ...