[ICRA 2019]Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images
简介
创新点

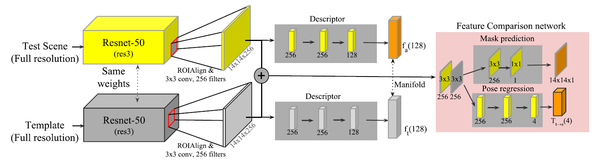
方法
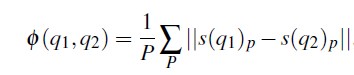
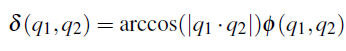
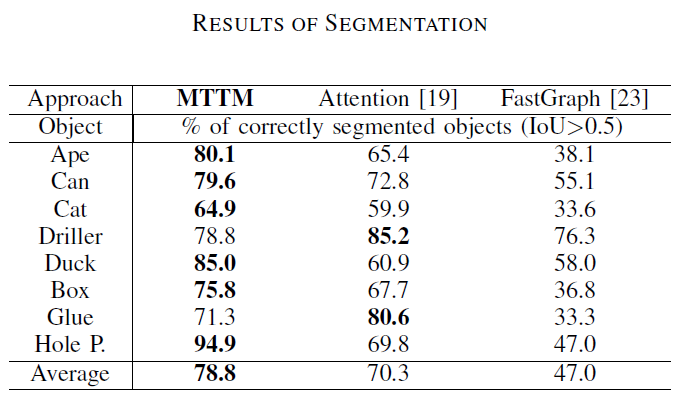
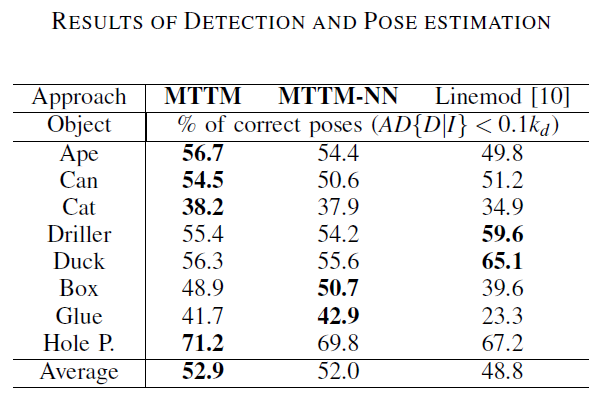
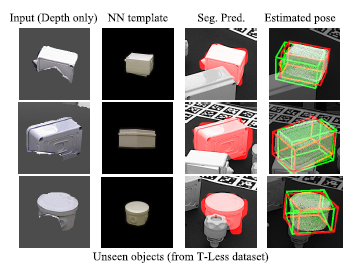
实验和结果


[ICRA 2019]Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images的更多相关文章
- OpenCV Template Matching Subpixel Accuracy
OpenCV has function matchTemplate to easily do the template matching. But its accuracy can only reac ...
- [ICCV 2019] Weakly Supervised Object Detection With Segmentation Collaboration
新在ICCV上发的弱监督物体检测文章,偷偷高兴一下,贴出我的poster,最近有点忙,话不多说,欢迎交流- https://arxiv.org/pdf/1904.00551.pdf http://op ...
- ICRA 2019最佳论文公布 李飞飞组的研究《Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks》获得了最佳论文
机器人领域顶级会议 ICRA 2019 正在加拿大蒙特利尔举行(当地时间 5 月 20 日-24 日),刚刚大会公布了最佳论文奖项,来自斯坦福大学李飞飞组的研究<Making Sense of ...
- 读论文系列:Object Detection NIPS2015 Faster RCNN
转载请注明作者:梦里茶 Faster RCNN在Fast RCNN上更进一步,将Region Proposal也用神经网络来做,如果说Fast RCNN的最大贡献是ROI pooling layer和 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- 读论文系列:Object Detection ICCV2015 Fast RCNN
Fast RCNN是对RCNN的性能优化版本,在VGG16上,Fast R-CNN训练速度是RCNN的9倍, 测试速度是RCNN213倍:训练速度是SPP-net的3倍,测试速度是SPP-net的3倍 ...
- Viola–Jones object detection framework--Rapid Object Detection using a Boosted Cascade of Simple Features中文翻译 及 matlab实现(见文末链接)
ACCEPTED CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION 2001 Rapid Object Detection using a B ...
- object detection 总结
1.基础 自己对于YOLOV1,2,3都比较熟悉. RCNN也比较熟悉.这个是自己目前掌握的基础2.第一步 看一下2019年的井喷的anchor free的网络3.第二步 看一下以往,引用多的网路4. ...
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
随机推荐
- 爬虫入门(四):urllib2
主要使用python自带的urllib2进行爬虫实验. 写在前面的蠢事:本来新建了一个urllib2.py便于好认识这是urllib2的实验,结果始终编译不通过,错误错误.不能用Python的关键字( ...
- flume install
flume install flume 安装 123456 [root@10 app][root@10 app]# mv apache-flume-1.7.0-bin /mnt/app/flume[r ...
- C++走向远洋——58(项目二3、动物这样叫、改进版)
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- Ubuntu 18.04 国内的 apt 源
一.Ubuntu 18.04 国内的 apt 源 1. 阿里源 deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted univers ...
- 什么是HDFS?算了,告诉你也不懂。
前言 只有光头才能变强. 文本已收录至我的GitHub精选文章,欢迎Star:https://github.com/ZhongFuCheng3y/3y 上一篇已经讲解了「大数据入门」的相关基础概念和知 ...
- YA157C交叉编译环境搭建
目录 1.开发板简介 3.主机搭建交叉编译环境 4.编译第一个ARM Linux程序--Hello World 5.在开发板上运行Hello World程序 6.ssh登录开发板 7.注意 8.she ...
- Angular 1 深度解析:脏数据检查与 angular 性能优化
TL;DR 脏检查是一种模型到视图的数据映射机制,由 $apply 或 $digest 触发. 脏检查的范围是整个页面,不受区域或组件划分影响 使用尽量简单的绑定表达式提升脏检查执行速度 尽量减少页面 ...
- fsLayuiPlugin多数据表格使用
fsLayuiPlugin 是一个基于layui的快速开发插件,支持数据表格增删改查操作,提供通用的组件,通过配置html实现数据请求,减少前端js重复开发的工作. GitHub下载 码云下载 测试环 ...
- vue之initComputed模块源码说明
要想理解原理就得看源码,最近网上也找了好多vue初始化方法(8个init恶魔...) 因为也是循序渐进的理解,对initComputed计算属性的初始化有几处看得不是很明白,网上也都是含糊其辞的(要想 ...
- EventEmitter:从命令式 JavaScript class 到声明函数式的华丽转身
新书终于截稿,今天稍有空闲,为大家奉献一篇关于 JavaScript 语言风格的文章,主角是函数声明式. 灵活的 JavaScript 及其 multiparadigm 相信"函数式&quo ...