Redis 主从复制技术原理
基于前面介绍的 Redis 内容,Redis 只能作为一个单机内存数据库,一旦服务器宕机即不能提供服务,即便能通过持久化策略重启恢复数据,往往也做不到百分之百还原。再一个就是,单机的 Redis 需要处理所有的客户端请求,包括读和写操作,压力很大。
说了这么多,Redis 当然也提供了解决方案,主从复制技术是实现 Redis 集群的最基本架构,集群中有一台或多台主节点服务器(master),多台从节点服务器(slave),slave 持续不断的同步 master 上的数据。一旦 master 宕机,我们可以切换 salve 成为新的 master 稳定提供服务,也不用担心 master 宕机导致的数据丢失。
下面我们就一起来看看主从复制技术的设计与应用,先看理论再看源码实现。
一、理论上的主从复制技术设计
主从复制技术有两个版本,2.8 以前的版本,设计上有缺陷,在 slave 断线后重连依然需要 master 重新发送 RDB 重新进行数据更新,效率非常低。2.8 版本以后做了重新设计,通过引入偏移量同步,相对而言非常的高效,我们这里不去讨论旧版本的设计了,直接看新版本的主从复制技术设计。
每一个 Redis 启动后,都会认为自己是一个 master 节点,你可以通过以下命令通知它成为 slave 并向 master 同步数据:
slaveof [masterip] [masterport]
另一种方式就是在 Redis 启动配置文件中直接指明让它作为一个 slave 节点启动,并在启动后同步 master 节点数据。配置项和命令是一样的。
如果 master 配置了密码连接,那么还需要在 slave 的配置文件中指明 master 的连接密码:
masterauth <password>
除此之外,salve 节点默认是只读的,不允许写入数据,因为如果支持写入数据,那么与 master 就无法保持数据一致性,所以我们一般会把 slave 节点作为读写分离中读服务提供者。当然,你也可以修改是否允许 slave 写入数据:
slave-read-only yes/no
当然如果你的 master 宕机了,你需要把某个 slave 上线成 master,你可以通过命令取消 slave 的数据同步,成为单独的一个 master:
slaveof no one
slave 同步 master 的数据主要分为两个大步骤,全量复制和部分复制。当我们执行 slaveof 命令的时候,我们的 slave 会作为一个客户端连接上 master 并向 master 发送 PSYNC 命令。
master 收到命令后,会调用 bgsave fork 一个后台子进程生产 RDB 文件,待合适的时候,在 serverCron 循环的时候发送给 slave节点。
slave 收到 RDB 文件后,丢弃目前内存中所有的数据并阻塞自己,专心做 RDB 读取,数据恢复。
以上就是主从复制的一个全量复制的大概流程,但是一次全量复制并不能永远的保持主从节点数据一致,master 还需要将实时的修改命令同步到从节点才行,这就是部分复制。
在介绍部分复制之前,这里先介绍几个概念。第一个是复制缓冲区(repl_backlog),这是一个 FIFO 的队列,里面存的是最近的一些写命令,大小默认在 1M,复制偏移量(offset),这个偏移量其实是对应复制缓冲区中的字符偏移。复制缓冲区的结构大致是这样的:
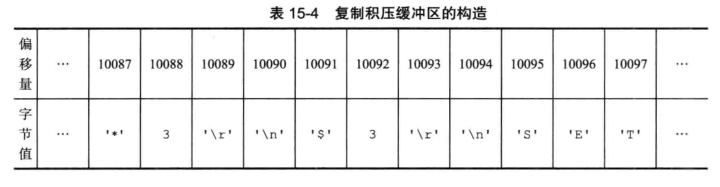
在主从节点完成第一轮全量复制以后,主从节点之间已经初步实现了数据同步,往后的 master,会将收到的每一条写命令发送给 slave 并 添加到复制缓冲区并根据字节数计算更新自己的偏移量,slave 收到传输过来的命令后也一样更新自己的偏移量。
这样,只要主从节点的偏移量相同就说明主从节点之间的数据是同步的。复制缓冲区大小是固定的,新的写命令进来以后,旧的数据就会出队列。如果某个 slave 断线重连之后,依然向 master 发送 PSYNC 命令并携带自己的偏移量,master 判断该偏移量是否还在缓冲区区间内,如果在则直接将该偏移量往后的所有偏移量对应的命令发送给 slave,无需重新进行全量复制。
这是新版同步复制的一个优化的设计,如果该断线重连的 slave 的偏移量已经不在缓冲区区间内,那么说明 master 可能已经无法找到自上次断线后的完整更新记录了,于是进行全量复制并将最新的偏移量发到 slave,算是完成了新的数据同步。
这就是主从复制的一个完整的设计逻辑,设计思路非常的优秀,很值得我们借鉴,下面我们看源码的一些实现情况。
二、看看源码实现
serverCron 定时函数中有这么一段代码:
run_with_period(1000) replicationCron();
按照默认的 server.hz 配置,每秒就需要执行一次 replicationCron。我们就来看看这个方法究竟做了什么。
void replicationCron(void) {
static long long replication_cron_loops = 0;
//slave 连接 master 超时,取消连接
if (server.masterhost &&
(server.repl_state == REPL_STATE_CONNECTING ||
slaveIsInHandshakeState()) &&
(time(NULL)-server.repl_transfer_lastio) > server.repl_timeout)
{
serverLog(LL_WARNING,"Timeout connecting to the MASTER...");
cancelReplicationHandshake();
}
//.rdb 文件响应超时,取消连接
if (server.masterhost && server.repl_state == REPL_STATE_TRANSFER &&
(time(NULL)-server.repl_transfer_lastio) > server.repl_timeout)
{
serverLog(LL_WARNING,"Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value.");
cancelReplicationHandshake();
}
//已经建立连接的情况下,某个操作超时,断开连接
if (server.masterhost && server.repl_state == REPL_STATE_CONNECTED &&
(time(NULL)-server.master->lastinteraction) > server.repl_timeout)
{
serverLog(LL_WARNING,"MASTER timeout: no data nor PING received...");
freeClient(server.master);
}
//检查配置项,是否需要向 master 发起连接
if (server.repl_state == REPL_STATE_CONNECT) {
serverLog(LL_NOTICE,"Connecting to MASTER %s:%d",
server.masterhost, server.masterport);
if (connectWithMaster() == C_OK) {
serverLog(LL_NOTICE,"MASTER <-> SLAVE sync started");
}
}
//向 master 发送自己的偏移量
//master 判断是否需要进行命令传播给 slave
if (server.masterhost && server.master &&
!(server.master->flags & CLIENT_PRE_PSYNC))
replicationSendAck();
。。。。。。。
}
因为不管 master 还是 slave,都是一个服务端的 Redis 程序,他们既可以成为主节点,又可以成为从节点。以上的代码段是当前 redis 作为一个 slave 时需要做的操作,replicationCron 后面的代码是当前 redis 作为一个主节点需要做的处理逻辑。
void replicationCron(void) {
。。。。。
listIter li;
listNode *ln;
robj *ping_argv[1];
//给所有的 slave 发送 ping
if ((replication_cron_loops % server.repl_ping_slave_period) == 0 &&
listLength(server.slaves))
{
ping_argv[0] = createStringObject("PING",4);
replicationFeedSlaves(server.slaves, server.slaveseldb,
ping_argv, 1);
decrRefCount(ping_argv[0]);
}
//发送 '\n' 给所有正在等待 rdb 文件的 slave,防止他们判定 master 超时
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
int is_presync =
(slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START ||
(slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END &&
server.rdb_child_type != RDB_CHILD_TYPE_SOCKET));
if (is_presync) {
if (write(slave->fd, "\n", 1) == -1) {
/* Don't worry about socket errors, it's just a ping. */
}
}
}
//所有的 slave 并断开所有超时的 slave
if (listLength(server.slaves)) {
listIter li;
listNode *ln;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
if (slave->replstate != SLAVE_STATE_ONLINE) continue;
if (slave->flags & CLIENT_PRE_PSYNC) continue;
if ((server.unixtime - slave->repl_ack_time) > server.repl_timeout)
{
serverLog(LL_WARNING, "Disconnecting timedout slave: %s",
replicationGetSlaveName(slave));
freeClient(slave);
}
}
}
//在没有 slave 节点连接后的 N 秒,释放复制缓冲区
if (listLength(server.slaves) == 0 && server.repl_backlog_time_limit &&
server.repl_backlog && server.masterhost == NULL)
{
time_t idle = server.unixtime - server.repl_no_slaves_since;
if (idle > server.repl_backlog_time_limit) {
changeReplicationId();
clearReplicationId2();
freeReplicationBacklog();
serverLog(LL_NOTICE,
"Replication backlog freed after %d seconds "
"without connected slaves.",
(int) server.repl_backlog_time_limit);
}
}
。。。。。。
}
总结一下,replicationCron 默认每一秒调用一次,分为两个部分,自己如果是 slave 节点的话,那么会判断与 master 之间的连接情况,如果等待 rdb 超时或其他连接超时,那么 slave 会断开与 master 的连接,如果发现配置文件中配置了 slaveof ,则会主动连接 master 发送 PSYNC 命令并且会发送自己的偏移量,期待 master 向自己传播命令。
如果自己是一个 master 的话,它会首先向所有的 slave 发送 ping,以免 slave 因为超时断开与自己的连接,并且还会主动断开一些超时连接的 slave。
除此之外我们需要补充一点的就是 redis 中非常重要的函数调用 call 函数,这个函数是所有命令对应的实现函数的前置调用。这个函数的具体逻辑我这里暂时不去详细介绍,但是其中有两个重要的步骤你需要明确,一是会调用执行命令的实现函数,二是会将修改命令添加到 AOF 文件并传播给所有的 slave 节点。
这样,我们关于主从复制的完整逻辑就基本解释通了,以上还只是一个基本的雏形,后面我们还将基于此介绍高可用的主从复制,借助哨兵(Sentinel)完成主从节点的高可用切换,故障转移等等,敬请期待~
关注公众不迷路,一个爱分享的程序员。
公众号回复「1024」加作者微信一起探讨学习!
每篇文章用到的所有案例代码素材都会上传我个人 github
https://github.com/SingleYam/overview_java
欢迎来踩!

Redis 主从复制技术原理的更多相关文章
- Redis主从同步原理-SYNC【转】
和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,下图为级 ...
- Redis——主从同步原理
刚接触到Redis,首先对Redis有一个初步的了解. 开源,免费,遵守BSD协议,key-value数据库. 可以将内存中的数据保存在磁盘中,重启的时候可以再次加载使用. 多种key-value类型 ...
- Redis主从同步原理-PSYNC【转】
Reids复制数据主要有2种场景: 1. 从服务器从来第一次和当前主服务器连接,即初次复制 2. 从服务器断线后重新和之前连接的主服务器恢复连接,即断线后重复制 对于初次复制来说使用SYNC命令进 ...
- Redis主从实现原理分析 [转]
原文地址:http://blog.sina.com.cn/s/blog_7530db6f0100vegl.html 一, 实现原理图 (1)Slave服务器连接到Master服务器. (2)Slave ...
- Redis主从环境配置
1.Redis主从同步原理 redis主服务器会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,然后将数据文件同步给从服务器,从服务器加载记录文件,在内存库中更新新数据. 2.VMWar ...
- Redis主从数据库同步
Redis主从同步原理-SYNC和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采 ...
- Redis主从同步分析(转)
一.Redis主从同步原理 1.1 Redis主从同步的过程 配置好slave服务器连接的master后,slave会建立和master的连接,然后发送sync命令.无论是第一次同步建立的连接还是连接 ...
- 15.6,redis主从同步
redis主从同步 原理:1. 从服务器向主服务器发送 SYNC 命令.2. 接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令.3 ...
- Redis主从同步分析
一.Redis主从同步原理1.1 Redis主从同步的过程配置好slave服务器连接的master后,slave会建立和master的连接,然后发送sync命令.无论是第一次同步建立的连接还是连接断开 ...
随机推荐
- 详解服务器性能测试的全生命周期?——从测试、结果分析到优化策略(转载)
服务器性能测试是一项非常重要而且必要的工作,本文是作者Micheal在对服务器进行性能测试的过程中不断摸索出来的一些实用策略,通过定位问题,分析原因以及解决问题,实现对服务器进行更有针对性的优化,提升 ...
- Coding and Paper Letter(十五)
资源整理. 1.Nature Climate Change论文"Higher temperatures increase suicide rates in the United States ...
- MySQL show命令的用法
show tables或show tables from database_name; // 显示当前数据库中所有表的名称 show databases; // 显示mysql中所有数据库的名称 sh ...
- 5——PHP逻辑运算符&&唯一的三元运算符
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- JavaScript逻辑分支switch 练习题
1.输入月份,显示当月的天数, 利用case穿透简化代码 var month = prompt("请输入月份"); var year = prompt("请输入年份&q ...
- ZYNQ自定义AXI总线IP应用——PWM实现呼吸灯效果
一.前言 在实时性要求较高的场合中,CPU软件执行的方式显然不能满足需求,这时需要硬件逻辑实现部分功能.要想使自定义IP核被CPU访问,就必须带有总线接口.ZYNQ采用AXI BUS实现PS和PL之间 ...
- 痞子衡嵌入式:恩智浦i.MX RT1xxx系列MCU启动那些事(11.3)- FlexSPI NOR连接方式大全(RT1010)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是恩智浦i.MX RT1010的FlexSPI NOR启动的连接方式. 在写完 <FlexSPI NOR启动连接方式(RT1015/ ...
- 94-datetmie模块
目录 datetmie模块 1 返回当前时间 2 当前时间+3天 3 当前时间-3天 4 当前时间-3小时 5 当前时间+30分钟 6 时间替换 datetmie模块 datetime模块可以看成是时 ...
- CSS 图像拼合技术(雪碧图)
1.css 图像拼合 图像拼合就是单个图像的集合. 有许多图像的网页可能需要很长的时间来加载和生成多个服务器的请求. 使用图像拼合会降低服务器的请求数量,并节省带宽. 代码如下: <!docty ...
- Python 3:ImportError “No Module named Setuptools”的解决方法
sudo apt-get install python-setuptools python3-setuptools