透过源码分析ArrayList运作原理
List接口的主要实现类ArrayList,是线程不安全的,执行效率高;底层基于Object[] elementData 实现,是一个动态数组,它的容量能动态增加和减少。可以通过元素下标访问对象,使用于快速检索场景时使用。
基于JDK1.8,通过ArrayList几个常用的方法,分析ArrayList原理。
属性及继承关系
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
}
ArrayList继承AbstractList类,并实现List接口;
RandomAccess:是一个标记接口,继承了RandomAccess接口的集合支持随机快速访问
Cloneable:继承Cloneable接口,重写clone()方法,能实现拷贝功能
Serializable:支持序列化,可存储和传输
空构造函数及带参构造函数
ArrayList()
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
当我们new ArrayList()时会初始化elementData属性为空数组{},此时底层的数组并没有被实例化,所以操作ArrayList其实就是围绕elementData这个数组而进行。
ArrayList(int initialCapacity)
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
当使用带参构造函数 initialCapacity ;可以从源码看出如果 initialCapacity 大于 0 ,会实例化一个指定长度的Object数组赋值给elementData ;如果 initialCapacity 等于 0 则依然赋值为空;否则抛出异常信息。
通过以上两个构造函数,可以很明确ArrayList底层其实是一个Object[] 数组,而调用ArrayList提供的方法,其实就是操作数组。
add(E e)
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
add(E e) 方法的作用是添加一个元素到列表末尾,方法第一行调用ensureCapacityInternal(size + 1); 代码如下:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
判断elementData为空数组时则返回DEFAULT_CAPACITY, minCapacity这两个中的最大值,接着调用ensureExplicitCapacity(minCapacity);代码如下:
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
可以看出这里其实就是判断是否需要进行扩容,条件是当我们所需要的数组长度减去数组的长度大于0时,会调用grow(minCapacity)进行扩容;代码如下:
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
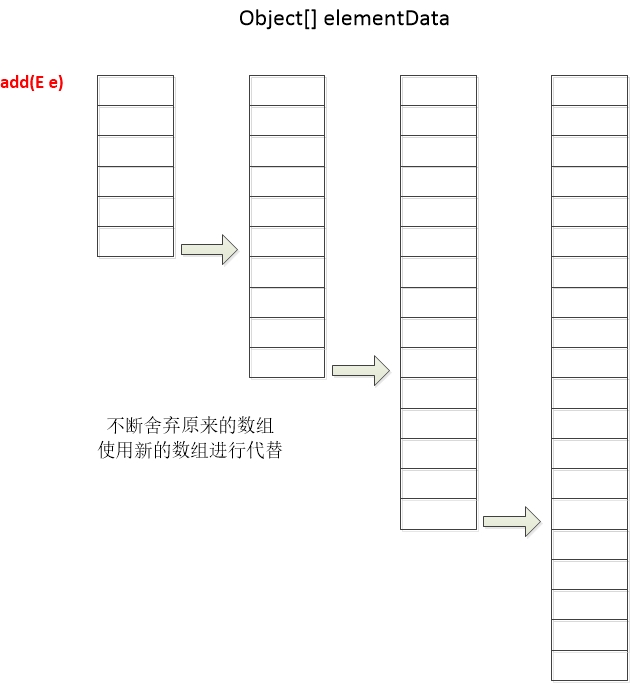
声明一个newCapacity属性,值为原数组长度的1.5倍且进行判断,如果扩容后的长度减去我们需要的数组长度小于0则使用扩容后的长度,如果扩容后的长度减去MAX_ARRAY_SIZE大于0则使用Integer的最大值(Integer.MAX_VALUE) ,这里的MAX_ARRAY_SIZE 实则是Integer.MAX_VALUE - 8,接下来就是拷贝一个新的数组
通过add(E e)方法的源代码,又可以很明确知道当我们在对ArrayList集合添加元素的时候,其实会对底层elementData数组的长度进行判断并动态调整且产生一个新的数组回来
remove(int index)
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
return oldValue;
}
remove(int index)方法的作用是按照索引位置删除并返回元素;第一行代码rangeCheck(index);检查索引是否越界,代码如下:
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
E oldValue = elementData(index);获取指定下标的数据,计算出需要移动的位置,调用native方法进行数组移动,改变size长度,且将--size位置置空等待GC回收,最终返回之前的值
get(int index)
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
get(int index)方法的作用是获取指定下标的元素;第一步检查索引是否合法,根据下标获取elementData数组中的数据并返回
set(int index, E element)
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
set(int index, E element)方法的作用是设置指定下标的元素值;第一步检查索引是否合法,然后获取之前的值,并将之前下标的值更改为当前数据,返回老数据
透过源码分析ArrayList运作原理的更多相关文章
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- 从定时器的选型,到透过源码看XXL-Job(下)
透过源码看xxl-job (注:本文基于xxl-job最新版v2.0.2, quartz版本为 v2.3.1. 以下提到的调度中心均指xxl-job-admin项目) 上回说到,xxl-job是一个中 ...
- 【转】MaBatis学习---源码分析MyBatis缓存原理
[原文]https://www.toutiao.com/i6594029178964673027/ 源码分析MyBatis缓存原理 1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 ...
- Kafka源码分析及图解原理之Producer端
一.前言 任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer).消息消费者(Consumer)和服务载体(在Kafka中用Broker指代).那么本篇主要讲解Producer端,会有 ...
- Guava 源码分析(Cache 原理 对象引用、事件回调)
前言 在上文「Guava 源码分析(Cache 原理)」中分析了 Guava Cache 的相关原理. 文末提到了回收机制.移除时间通知等内容,许多朋友也挺感兴趣,这次就这两个内容再来分析分析. 在开 ...
- 深入源码分析SpringMVC底层原理(二)
原文链接:深入源码分析SpringMVC底层原理(二) 文章目录 深入分析SpringMVC请求处理过程 1. DispatcherServlet处理请求 1.1 寻找Handler 1.2 没有找到 ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
- 通过源码分析Java开源任务调度框架Quartz的主要流程
通过源码分析Java开源任务调度框架Quartz的主要流程 从使用效果.调用链路跟踪.E-R图.循环调度逻辑几个方面分析Quartz. github项目地址: https://github.com/t ...
- Robotium源码分析之运行原理
从上一章<Robotium源码分析之Instrumentation进阶>中我们了解到了Robotium所基于的Instrumentation的一些进阶基础,比如它注入事件的原理等,但Rob ...
随机推荐
- WSGI-mini-web框架服务器
前期准备: 安装python环境安装pycharm安装MySQL数据库安装pymsql创建一个学生表,存入数据我们只是实现一个非常简单的web服务,前端页面不会专门做页面文件,会在代码中以具体命令的形 ...
- MongoDB复制集概念架构浅析
一.复制集的作用 (1) 高可用 防止设备(服务器.网络)故障. 提供自动failover 功能. 技术来保证数 (2) 灾难恢复 当发生故障时,可以从其他节点恢复. (3) 功能隔离 用于分析.报表 ...
- Scrapy 入门教程
Scrapy 是用 Python 实现的一个为了爬取网站数据.提取结构性数据而编写的应用框架. Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通常我们可以很简单的通过 ...
- Hadoop集群搭建(三)~centos6.8网络配置
安装完centos之后,进入系统,进行网络配置.主要分为五个部分: 修改虚拟机网络编辑器:配置Winodws访问虚拟机:配置centos网卡:通过网络名访问虚拟机配置网络服务. (一)虚拟机网络编辑器 ...
- turtle学习笔记
1.turtle的绘图窗体 turtle.setup(width, height, startx,starty) - setup()设置窗体大小及位置- 4个参数中后两个可选(后两个省略时默认窗口在屏 ...
- 【Python】2.12学习笔记 变量
变量 关于变量我有一个不能理解的,关于全局变量作用域与地址的问题,学函数的时候我可能会搞懂它并且写下来 另外,其实昨天说的是有些不准确的,\(Python\)里的变量不是不用声明类型,只是声明方式特殊 ...
- 解决vue在控制台的 NavigationDuplicated 报错
解决问题: 点击相同的链接,会有一个重复key的报错 const originalPush = Router.prototype.push Router.prototype.push = functi ...
- 150多个Flutter组件详细介绍送给你
迷茫是什么,迷茫就是大事干不了,小事不想干,能力配不上欲望,才华配不上梦想. 150+Flutter组件详细介绍地址:http://laomengit.com/ 前言 我在Flutter未正式发布之前 ...
- 搭建XSS测试平台
XSS测试平台是测试XSS漏洞获取cookie并接收web页面的平台,XSS可以做js能做的所有事情,包括但不限于窃取cookie,后台增删文章.钓鱼.利用xss漏洞进行传播.修改网页代码.网站重定向 ...
- [组件封装]微信小程序-图片批量上传照片墙
描述 批量上传图片, 可设置最大上传个数, 可删除, 可设置默认值. 效果 源码 pictures-wall.wxml <view class="picturesWall"& ...