从当当客户端api抓取书评到词云生成
看了好几本大冰的书,感觉对自己的思维有不少的影响。想看看其他读者的评论。便想从当当下手抓取他们评论做个词云。
想着网页版说不定有麻烦的反爬,干脆从手机客户端下手好了。
果其不然,找到一个书评的api。发送请求就有详情的json返回,简直不要太方便...
要是对手机客户端做信息爬取,建议安装一个手机模拟器。
思路:
在安装好的手机模拟器设置好用来抓包的代理,我用的charles。记得安装证书,不然抓不了https的数据包。
然后安装当当客户端,打开进到书评页面。
KZRBSKE.png)
然后成功在charles找到了这个接口。发送get请求就会返回书评...

然后这个接口只有page参数需要注意下,代表请求的第几页。然后其他参数我照抄过来了。
当当边好像没有对这些参数做检验,用很久之前抓的的链接的参数还是能请求到数据...
之后就是请求链接在脚本里解析返回的json就好了,我只需要评论,十几行代码就行。
如果要抓其他书的书评应该修改参数product_id就好。
爬虫代码:
import requests
import json
import random
import time url='http://api.dangdang.com/community/mobile/get_product_comment_list?access-token=&product_id=25288851&time_code=ae4074539cd0bf4ad526785a9439d756&tc=0cdfe66abc1ef55674c1ca8f815414b0&client_version=8.10.0&source_page=&action=get_product_comment_list&ct=android&union_id=537-100893×tamp=1540121525&permanent_id=20181021192526739954846678302543739&custSize=b&global_province_id=111&cv=8.10.0&sort_type=1&product_medium=0&page_size=15&filter_type=1&udid=c3b0e748134cbd9612e3e8b6a7e52952&main_product_id=&user_client=android&label_id=&page='
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
def getComments(url, page):
url = url+str(page) #url拼接,为了获取指定页的评论
html = requests.get(url=url,headers=headers)
res = json.loads(html.text)
result = res.get('review_list') #从字典中获取key为review_list的值,这与当当返回的数据结构有关
comments = []
for comment in result:
comments.append(comment['content']) #评论正文
try:
with open('comments.txt','a',encoding='utf-8') as f:
f.write(comment['content']+'\n') #写入文本中,免不了编码错误,加个try算了
except:
print('第'+str(page)+'页出错')
continue
for i in range(1,100): #爬100页的评论
time.sleep(random.choice([1,2,3])) #每次循环强制停1~3秒,控制下频率...
getComments(url,i)
词云生成,先使用jieba分词对爬到的评论进行分词。
记得分词后要用停用词表将一些没有什么意义的字符删去,比如标点符号,各种人称代词等等...
最后用pyecharts生成词云。
词云生成代码:
import jieba
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
from pyecharts.globals import SymbolType #添加自定义的分词
jieba.add_word('你坏')
jieba.add_word('大冰')
jieba.add_word('江湖') #文本的名称
text_path='comments.txt'
#一些词要去除,停用词表
stopwords_path='stopwords.txt' #读取要分析的文本
words_file = open(text_path,'r',encoding='utf-8')
text = words_file.read() def jiebaClearText(text): #分词,返回迭代器
seg_iter = jieba.cut(text,cut_all=False)
listStr = list(seg_iter) res = {}
#这个循环用来记录词频
for i in listStr:
if i in res:
res[i] += 1
else:
res[i.strip()] = 1
try:
#读取停用表
f_stop = open(stopwords_path,encoding='utf-8')
f_stop_text = f_stop.read()
finally:
f_stop.close()
#以换行符分开文本,因为每个停用词占一行。返回停用词列表
f_stop_seg_list = f_stop_text.split('\n')
#这个循环用来删除评论出现在停用词表的词
for i in f_stop_seg_list:
if i in res:
del res[i] words = []
for k,v in res.items():
words.append((k,v))
#words的元素是(词,词出现的次数)
#下面是以出现的次数将words排序
words.sort(key=lambda x:x[1],reverse=True)
return words words = jiebaClearText(text)
words_file.close() # 关闭一开始打开的文件
print(words)
#词云生成,用到pyecharts,各参数的含义请到官方文档查看...
worldcloud=(
WordCloud().add("", words[:60], word_size_range=[10, 100],rotate_step=0, shape='triangle' ).set_global_opts(title_opts=opts.TitleOpts(title="《你坏》"))
)
worldcloud.render('result.html') #保存成html文件
结果:
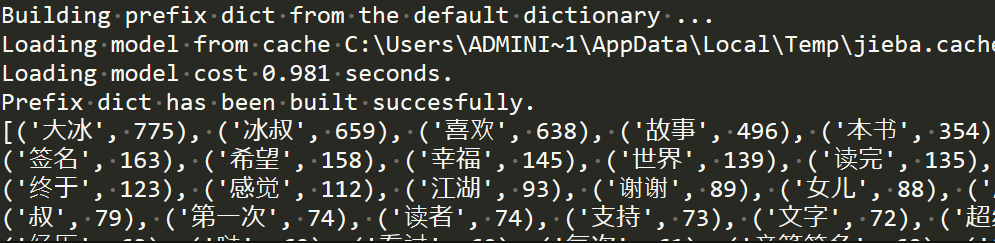
词云:
1V%7DC[JKFBM6.png)
最后,可以看到,其实书评里有很多带正向感情色彩的评论。
内容还是很正能量的哈哈,每天看一遍,赶走抑郁~
所以,容我也向您安利一下大冰的书哈哈。
The End~
从当当客户端api抓取书评到词云生成的更多相关文章
- python抓取数据构建词云
1.词云图 词云图,也叫文字云,是对文本中出现频率较高的"关键词"予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨. 先看几个词 ...
- 百度音乐API抓取
百度音乐API抓取 前段时间做了一个本地音乐的播放器 github地址,想实现在线播放的功能,于是到处寻找API,很遗憾,不是歌曲不全就是质量不高.在网上发现这么一个APIMRASONG博客,有“获取 ...
- python抓取电影<海王>影评词云生成
海王是前段时间大热的影片,个人对这种动漫题材的电影并不是很感兴趣.然鹅,最近这部电影实在太热了,正好最近看自然语言处理的时候,无意间发现了word cloud这个生成词云的库,还蛮好玩的,那就抓抓这部 ...
- Google Map API抓取地图坐标信息小程序
因为实验室需要全国城市乡镇的地理坐标,有Execl的地名信息,需要一一查找地方的经纬度.Google Map地图实验室提供自带的查找经纬度的方法,不过需要一个点一个点的手输入,过于繁琐,所以自己利用G ...
- python抓取百度热词
#baidu_hotword.py #get baidu hotword in news.baidu.com import urllib2 import os import re def getHtm ...
- WireShark系列: 使用WireShark过滤条件抓取特定数据流(zz)
应用抓包过滤,选择Capture | Options,扩展窗口查看到Capture Filter栏.双击选定的接口,如下图所示,弹出Edit Interface Settints窗口. 下图显示了Ed ...
- Twitter数据抓取
说明:这里分三个系列介绍Twitter数据的非API抓取方法.有兴趣的QQ群交流: BitCrawler网络爬虫QQ群 322937592 1.Twitter数据抓取(一) 2.Twitter数据抓取 ...
- 一站式学习Wireshark(八):应用Wireshark过滤条件抓取特定数据流
应用抓包过滤,选择Capture | Options,扩展窗口查看到Capture Filter栏.双击选定的接口,如下图所示,弹出Edit Interface Settints窗口. 下图显示了Ed ...
- Python开发笔记:网络数据抓取
网络数据获取(爬取)分为两部分: 1.抓取(抓取网页) · urlib内建模块,特别是urlib.request · Requests第三方库(中小型网络爬虫的开发) · Scrapy框架(大型网络爬 ...
随机推荐
- 把本地的jar包导入到本地的maven仓库,Eclipse可以使用
mvn install:install-file -Dfile=F:/SprintDirectory/ToolsDirectory/libary/fastdfs_client_v1.20.jar -D ...
- python后端面试第六部分:git版本控制--长期维护
################## git版本控制 ####################### 1,git常见命令作用 2,某个文件夹中的内容进行版本管理:进入文件夹,右键git bash 3, ...
- python后端面试第三部分:数据储存与缓存相关--长期维护
1. 列举常见的关系型数据库和非关系型都有哪些?2. MySQL常见数据库引擎及比较?3. 简述数据三大范式?4. 什么是事务?MySQL如何支持事务?5. 简述数据库设计中一对多和多对多的应用场景? ...
- 安装rpm包时遇到error: Failed dependencies:错误
在linux下安装rpm包时经常会遇到下面这个问题: error: Failed dependencies: ............................................. ...
- mysql索引的面试题
相信很多人对于MySQL的索引都不陌生,索引(Index)是帮助MySQL高效获取数据的数据结构. 因为索引是MySQL中比较重点的知识,相信很多人都有一定的了解,尤其是在面试中出现的频率特别高.楼主 ...
- 年轻的心与渐行渐近的梦——记微软-斯坦福产品设计创新课程ME310
作者:中国科学技术大学 王牧 Stanford D. School 2014年6月,沐浴着加州的阳光,在斯坦福大学(下文简称Stanford)完成汇报后,历时一年的创新设计课程ME310的项目结束 ...
- 第十六届“二十一世纪的计算”学术研讨会 密西根州立大学教授Anil K. Jain主题演讲
Biometrics---How Do I Know Who You Are? 密西根州立大学教授Anil K. Jain主题演讲" title="第十六届"二十一世纪的 ...
- 关于php自学
自己本人现在正在自学php有一段时间了,不知道现在的学习状态咋样,在我看来应该属于不算很糟糕,但有点糟糕的状态. 如果算学习自学php的话,现在断断续续应该是有5个月了,按理说是差不多可以做出独立项目 ...
- 吴裕雄--天生自然python学习笔记:Python CGI编程
什么是CGI CGI 目前由NCSA维护,NCSA定义CGI如下: CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户 ...
- 吴裕雄--天生自然HTML学习笔记:HTML <head>
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...