fastdfs的入门到精通(引言和单机安装)
引言:
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。【百度百科】
介绍:
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。跟踪器主要做调度工作,在访问上起负载均衡的作用。
存储节点存储文件,完成文件管理的所有功能:就是这样的存储、同步和提供存取接口,FastDFS同时对文件的metadata进行管理。所谓文件的meta data就是文件的相关属性,以键值对(key value)方式表示,如:width=1024,其中的key为width,value为1024。文件metadata是文件属性列表,可以包含多个键值对。
跟踪器和存储节点都可以由一台或多台服务器构成。跟踪器和存储节点中的服务器均可以随时增加或下线而不会影响线上服务。其中跟踪器中的所有服务器都是对等的,可以根据服务器的压力情况随时增加或减少。
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
FastDFS中的文件标识分为两个部分:卷名和文件名,二者缺一不可。
注意:fastdfs不适应大文件的管理(建议存储 4KB< file_size <500MB),如果超大文件的存储要借助hadoop来实现。上面重点理解tracker和storage两个角色。
原理:
网络拓扑图如下(这是网上比较经典的一张网络拓扑图,仅供参考)

功能描述:主要解决了海量数据存储问题,特别适合以中小文件(建议范围:4KB< file_size <500MB)为载体的在线服务
安装:(以单机版安装为例)
安装前注意:fastdfs暂时没有在window安装版本,下面我安装步骤如下:
官网:https://sourceforge.net/projects/fastdfs/
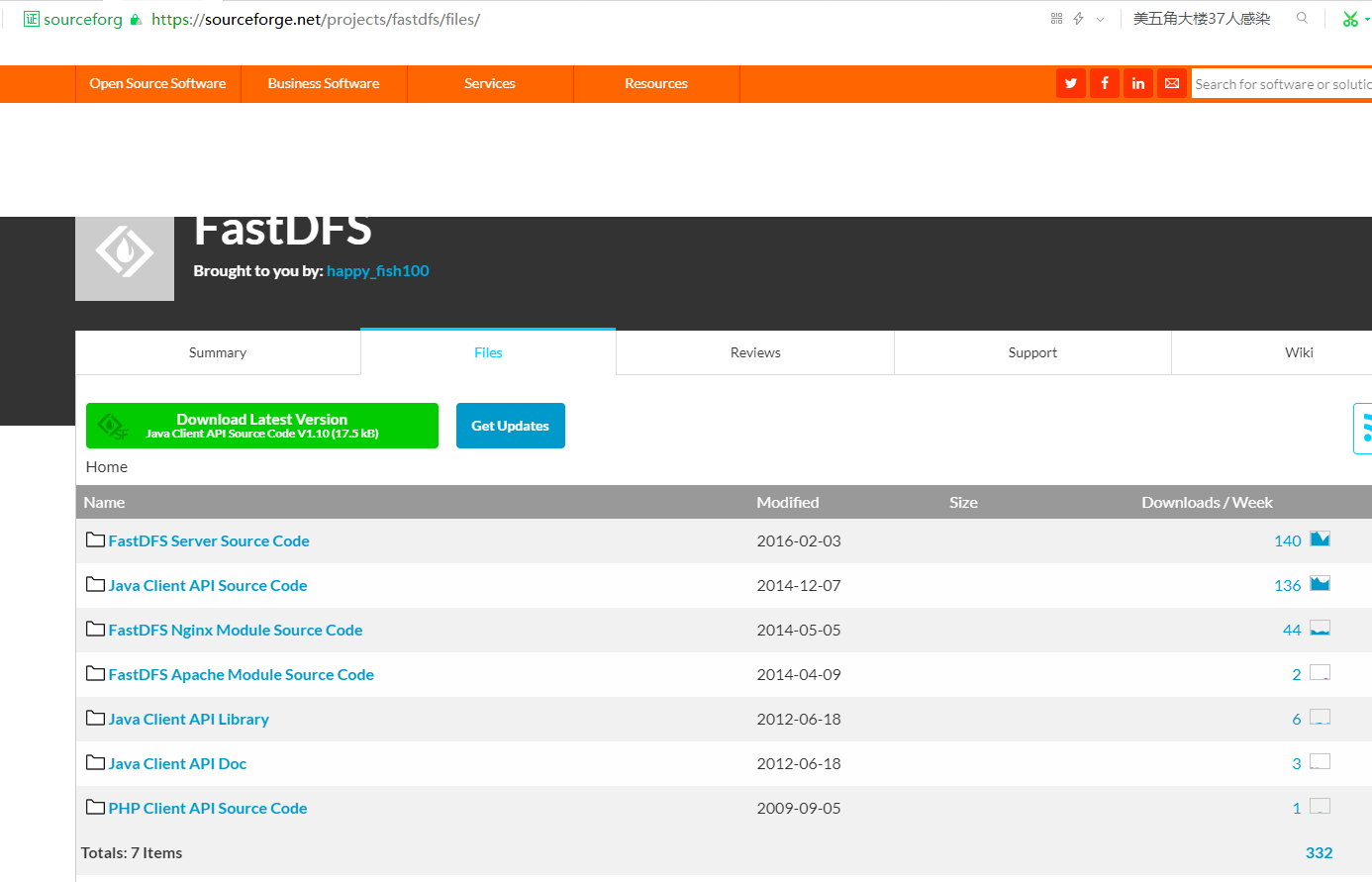
点击file后如下:
第一步: 准备一台主机,修改主机名为fastdfs
vi /etc/hostname | hostnamectl set-hostname 主机名
然后重启:reboot 使其生效:
第二步: 安装相关依赖包和下载相关安装包:
安装相关依赖包
yum install gcc-c++ perl-devel pcre-devel openssl-devel zlib-devel wget
下载libfastcommon
wget https://github.com/happyfish100/libfastcommon/releases/tag/V1.0.36
下载fastdfs
wget https://github.com/happyfish100/fastdfs/releases/tag/V5.11
注意,下载安装包后上传到root家目录下的fastdfs下
安装gcc等依赖:

第三步:解压并编译安装:
tar -zxvf libfastcommon-1.0.36.tar.gz || tar -zxvf fastdfs-5.11.tar.gz

编译:分两步,先编译libfastcommon 然后再编译fastdfs
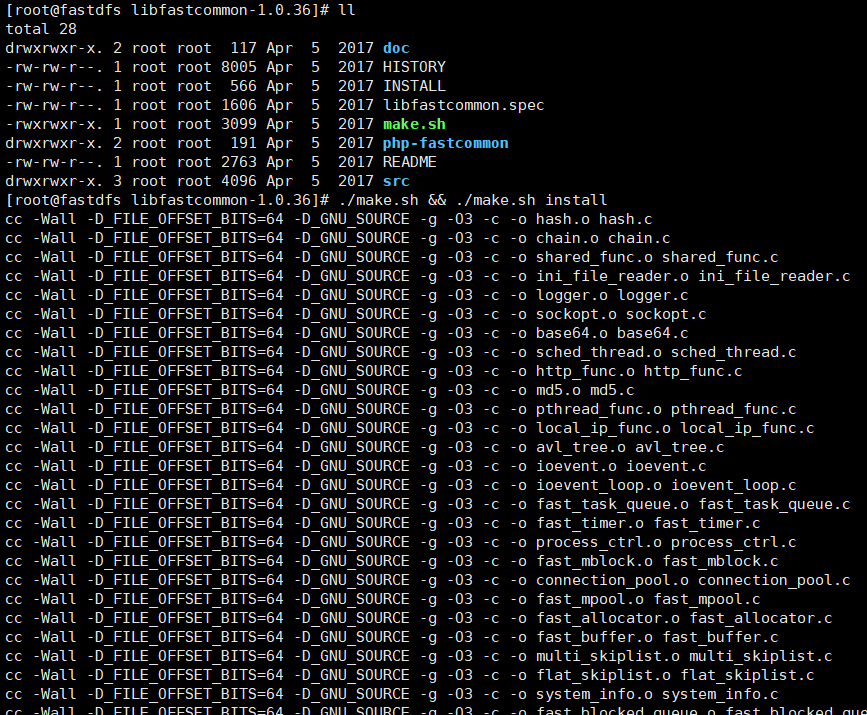
1> 进去libfastcommon 中: 执行 ./make.sh && ./make.sh install
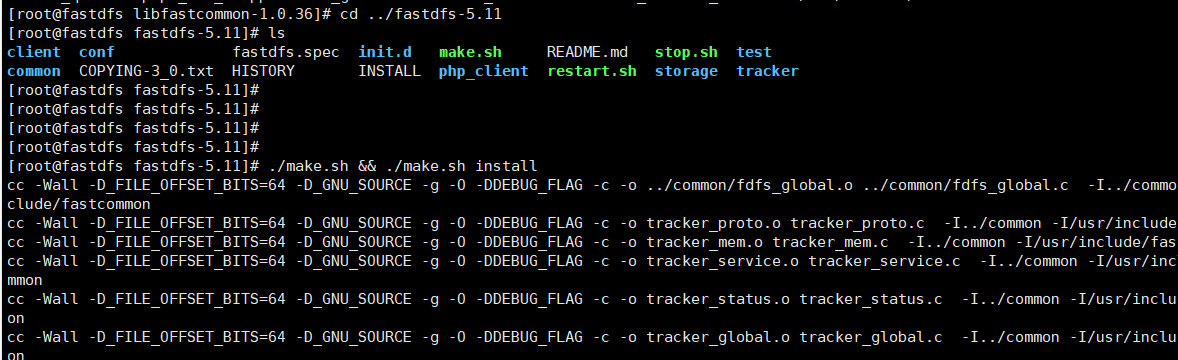
2. 进入到fastdfs目录,执行 ./make.sh && ./make.sh install 同上
第四步:启动tracker和storage
配置tracker
1> cd /etc/fdfs/
2> cp tracker.conf.sample tracker.conf
3> mkdir -p /data/tracker
4> vi tracker.conf
base_path=/data/tracker -- tracker配置目录
5> 启动tracker
fdfs_trackerd /etc/fdfs/tracker.conf start
6> ps aux | grep fdfs
配置storage
1> cd /etc/fdfs/
2> cp storage.conf.sample storage.conf
3> mkdir -p /data/storage
4> vi storage.conf
base_path=/data/storage -- storage 配置目录
store_path0=/data/storage -- 同上
tracker_server=192.168.236.130:22122 -- tracker服务器地址
5> 启动storage服务
fdfs_storaged /etc/fdfs/storage.conf start
6> 查看服务启动情况 ps aux| grep fdfs
配置client:
1> cd /etc/fdfs/
2> cp client.conf.sample client.conf
3> vi client.conf
base_path=/data/tracker -- 与tracker.conf 配置路径相同
tracker_server=192.168.236.130:22122 -- tracker服务器地址
相关操作截图如下:
1.修改配置文件名称:
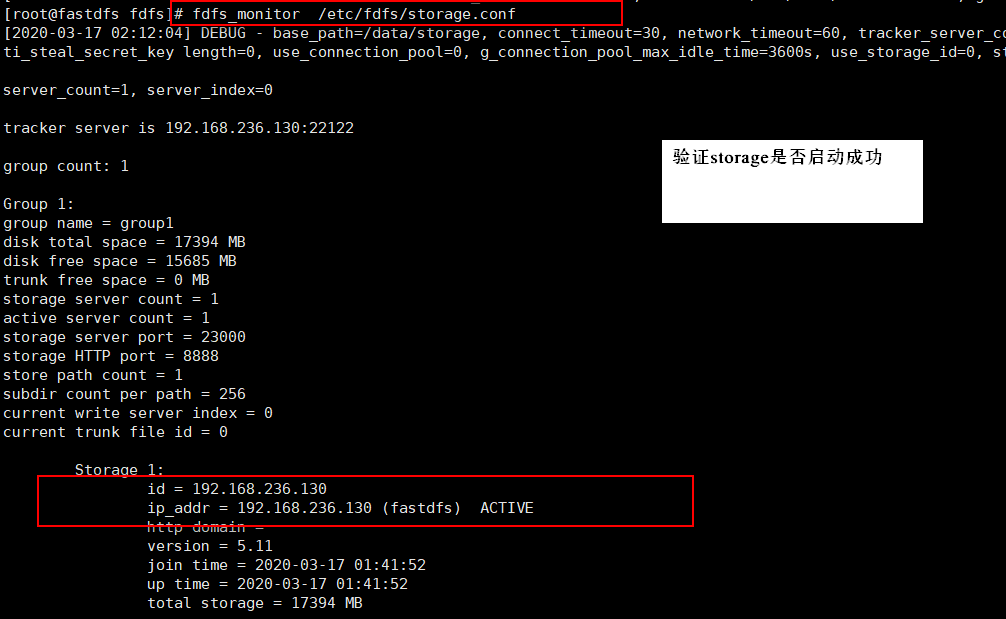
验证storage是否启动完成:
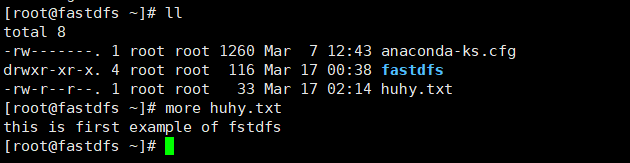
第五步: 测试文件上传:
在根目录下准备一个 文件 huhy.txt
执行: fdfs_upload_file /etc/fdfs/client.conf huhy.txt

到这就上传成功了。
补充:
根据上传成功文件返回的标识查询一下文件路径和内容。

到这大家基本上对fastdfs应该有个简单的认识了。以上是真实搭建案例,仅供参考
fastdfs的入门到精通(引言和单机安装)的更多相关文章
- SaltStack入门到精通第一篇:安装SaltStack
SaltStack入门到精通第一篇:安装SaltStack 作者:纳米龙 发布日期:2014-06-09 17:50:36 实际环境的设定: 系统环境: centos6 或centos5 实验机 ...
- Atom编辑器入门到精通(二) 插件的安装和管理
在本节中我们会学习如果安装和使用插件插件是Atom中一个非常重要的组成部分,很多功能都是以插件形式存在的.比如上篇文章中提到的目录树和设置等窗口都是通过默认安装的插件来实现的. 查看已安装的插件 打开 ...
- kubernetes入门(10)kubernetes单机安装后 - helloworld
前言 查看端口是否被监听了 ::netstat -tlp |grep 31002 我是用的yum install etcd kubernetes docker vim, 这样装的是1.5.2,不是最新 ...
- Docker从入门到精通(二)——安装Docker
通过上面文章,我们大概知道了什么是Docker,但那都是文字功夫,具体想要理解,还得实操,于是这篇文章带着大家来手动安装Docker. 1.官方教程 https://docs.docker.com/e ...
- HR问了一句DB是啥?SQL是啥?DB是Database数据库,SQL是数据库语言! 然后呢? 数据库从入门到精通--入门必看!
写在前面 本文的写作知识体系来源于我的数据库老师SDAU张承明,部分知识来自于网络,我呢对知识进行了细化和添加了自己的一些看法,并且加入了一些实例帮助理解,本文不是面向SQL高手写的,可以看作是数据库 ...
- 从入门到精通(分布式文件系统架构)-FastDFS,FastDFS-Nginx整合,合并存储,存储缩略图,图片压缩,Java客户端
导读 互联网环境中的文件如何存储? 不能存本地应用服务器 NFS(采用mount挂载) HDFS(适合大文件) FastDFS(强力推荐
- 大数据应用之:MongoDB从入门到精通你不得不知的21个为什么?
一.引言: 互联网的发展和电子商务平台的崛起,催生了大数据时代的来临,作为大数据典型开发框架的MongoDB成为了No-sql数据库的典型代表.MongoDB从入门到精通你不得不知的21个为什么专为大 ...
- Redis从入门到精通:初级篇
原文链接:http://www.cnblogs.com/xrq730/p/8890896.html,转载请注明出处,谢谢 Redis从入门到精通:初级篇 平时陆陆续续看了不少Redis的文章了,工作中 ...
- Redis从入门到精通:初级篇(转)
原文链接:http://www.cnblogs.com/xrq730/p/8890896.html,转载请注明出处,谢谢 Redis从入门到精通:初级篇 平时陆陆续续看了不少Redis的文章了,工作中 ...
随机推荐
- 3dmax2014卸载/安装失败/如何彻底卸载清除干净3dmax2014注册表和文件的方法
3dmax2014提示安装未完成,某些产品无法安装该怎样解决呢?一些朋友在win7或者win10系统下安装3dmax2014失败提示3dmax2014安装未完成,某些产品无法安装,也有时候想重新安装3 ...
- GBDT的理解和总结
2015/11/21 16:29:29 by guhaohit 导语: GBDT是非常有用的机器学习的其中一个算法,目前广泛应用于各个领域中(regression,classification,ran ...
- [LC] 71. Simplify Path
Given an absolute path for a file (Unix-style), simplify it. Or in other words, convert it to the ca ...
- Python 模块之间的引用
项目结构: Dog.Cat模块引用Animal模块 Animal模块代码: # -*- coding:UTF-8 -*- # 定义一个动物类 class Animal(object): def run ...
- JavaScript 中事件对象参数:clientX、clientY、offsetX、offsetY、screenX、screenY
JavaScript 中一些概念理解 :clientX.clientY.offsetX.offsetY.screenX.screenY clientX 设置或获取鼠标指针位置相对于窗口客户区域的 x ...
- zookeeper ACL(access control lists)权限控制
基本作用: 针对节点可以设置 相关读写等权限,目的为了保障数据安全性 权限permissions可以制定不同的权限范围以及角色 一:ACL构成 zk的acl ...
- javaWeb简单登录实现验证数据库
用户登录案例需求: 1.编写login.html登录页面 username & password 两个输入框 2.使用Druid数据库连接池技术,操作mysql,day14数据库中user表 ...
- JAVA9中文API百度网盘免费下载
JAVA9中文API百度网盘免费下载: https://pan.baidu.com/s/1tvHYQA8yyAS4xUFxwWrx_Q 提取码: 6e5h
- 高效能Windows人士的N个习惯之一:启动篇
接触电脑十多年,经历了各种折腾阶段,这几年开始沉静下来,不再追求花哨的界面与应用,只注重工作的效率,逐渐养成了一套自己的操作习惯,感觉不错,特撰文分享.标题借用了一下<高效能人士的七个习惯> ...
- 杂记:Linux下gcc升级
公司要求,需要在CentOS6.5系统下进行一些测试.因为编写的测试程序中使用了一些C++11之后新增的特性,而CentOS6.5中安装的gcc版本为4.4.7,并不支持C++11,所以需要对gcc进 ...