HBase完全分布式集群搭建
HBase完全分布式集群搭建
hbase和hadoop一样也分为单机版,伪分布式版和完全分布式集群版,此文介绍如何搭建完全分布式集群环境搭建。hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop的完全集群环境。本文中采用独立的zookeeper,不使用hbase自带的zookeeper。
一.环境准备
*HBase软件包hbase-1.2.0-cdh5.12.0.tar.gz
*完成hadoop集群环境搭建
二.安装HBase
1.首先在hdp-node-01安装配置好之后,再复制分发到其他从节点
#解压
| $ tar -xzvf hbase-1.2.0-cdh5.12.0.tar.gz -C /opt/modules/cdh5.12.0 |
2.配置环境变量vim /etc/profile
|
#HBASE_HOME export HBASE_HOME=/opt/modules/cdh5.12.0/hbase-1.2.0-cdh5.12.0 export PATH=$HBASE_HOME/bin:$PATH |
三.配置文件
hbase 相关的配置主要包括hbase-env.sh、hbase-site.xml、regionservers三个文件,都在$HBASE_HOME/conf目录下面,同时拷贝hadoop的配置文件core-site.xml,hdfs-site.xml到该目录下,因为hadoop使用了HA集群模式,hbase访问hdfs时需要知道访问地址。
1.配置hbase-env.sh
|
export JAVA_HOME=/opt/modules/jdk1.7.0_71 #关联hadoop #Hbase日志目录,需创建 #使用单独的zookeeper,禁用hbase自带的zookeeper |
2.配置 hbase-site.xml
|
<configuration> |
3.修改regionservers
|
vim /opt/modules/cdh5.12.0/hbase-1.2.0-cdh5.12.0/conf/regionservers hdp-node-02 hdp-node-03 hdp-node-04 hdp-node-05 |
4.复制分发hbase到其他4个从节点中
| $ scp -r hbase-1.2.0-cdh5.12.0/ root@hdp-node-02:/opt/modules/cdh5.12.0/ |
四.启动HBase
由于是集群在master节点hdp-node-01上启动hbase即可
| $ bin/start-hbase.sh |
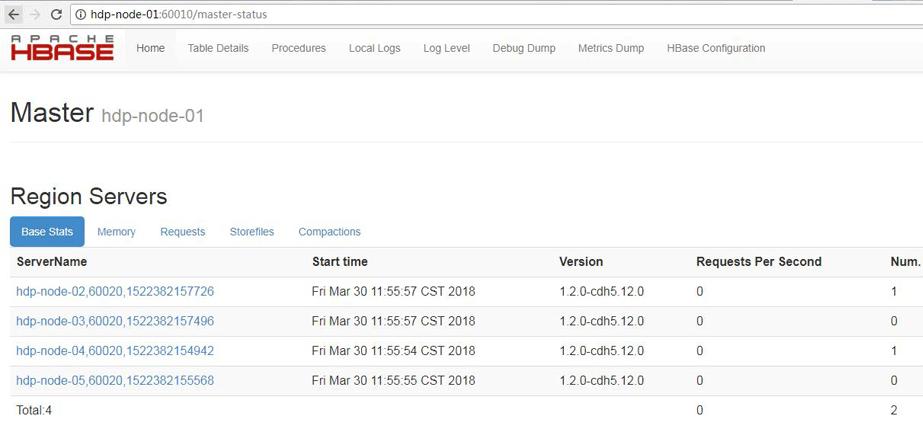
五.访问HBase Web页面
| http://hdp-node-01:60010 |
HBase完全分布式集群搭建的更多相关文章
- hbase完整分布式集群搭建
简介: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop2.8 ha 集群搭建 hbase完整分布式集群搭建 hadoop完整集群遇到问题汇总 Hb ...
- HBase HA分布式集群搭建
HBase HA分布式集群搭建部署———集群架构 搭建之前建议先学习好HBase基本构架原理:https://www.cnblogs.com/lyywj170403/p/9203012.html 集群 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 基于HBase0.98.13搭建HBase HA分布式集群
在hadoop2.6.0分布式集群上搭建hbase ha分布式集群.搭建hadoop2.6.0分布式集群,请参考“基于hadoop2.6.0搭建5个节点的分布式集群”.下面我们开始啦 1.规划 1.主 ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
- HBase篇--搭建HBase完全分布式集群
一.前述. 完全分布式基于hadoop集群和Zookeeper集群.所以在搭建之前保证hadoop集群和Zookeeper集群可用.可参考本人博客地址 https://www.cnblogs.com/ ...
- 分布式实时日志系统(四) 环境搭建之centos 6.4下hbase 1.0.1 分布式集群搭建
一.hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- 1、搭建HBase完全分布式集群
搭建完全分布式集群 HBase集群建立在hadoop集群基础之上,所以在搭建HBase集群之前需要把Hadoop集群搭建起来,并且要考虑二者的兼容性.现在就以5台机器为例,搭建一个简单的集群. 软件版 ...
随机推荐
- UML-领域模型-属性
1.属性预览 2.导出属性是什么? 3.属性使用什么样的数据类型? 常见的数据类型:boolean.Date.String(Text).Integer 其他常见的:SKU.枚举类型等 而在java类中 ...
- 关于本人:-D(必读)
关于本人 本人目前从事iOS开发,但心中也有一个全栈的梦想,希望与大家共勉! 关于博客内容 自己会不时分享一些iOS方面的技术点.总结的一些经验及工具类.还有学习其他语言过程中的笔记.技术.总结及心得 ...
- 哈夫曼编码的理解(Huffman Coding)
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,可变字长编码(VLC)的一种.Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最 ...
- Django 多对多 关系
多对多,本意就是多个一对多的关系 定义多对多 ManyToManyField 字段 from django.db import models # 学生类 class Student(models.Mo ...
- UserTokenManager JwtHelper
package org.linlinjava.litemall.wx.service; import org.linlinjava.litemall.wx.util.JwtHelper; /** * ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:windows操作系统删除tensorflow
输入:pip uninstall tensorflow Proceed(y/n):y
- yuyuecms 1.2文件删除漏洞
www.yuyue-cms.com yuyuecms版本1.2 管理员/索引控制器删除方法中的漏洞 请参阅catfishcmsCatfish isPost静态方法 如果调用后验证静态方法 如果为tru ...
- Debian8.8同步时间
1.安装ntpdate 2.设置当前年月 如:sudo date -s 2017-05-18 3.同步:sudo ntpdate /usr/sbin/ntpdate time.nist.gov
- VUEJS文件扩展名esm.js和common.js是什么意思
vue.js : vue.js则是直接用在<script>标签中的,完整版本,直接就可以通过script引用. vue.common.js :预编译调试时,CommonJS规范的格式,可以 ...
- WMS出库单重复
发货通知单?WMS备货单选项勾选 不自动复制?新增?