云服务器下如何部署Flask项目详细操作步骤
参考网上各种方案,再结合之前学过的Django部署方案,最后确定Flask总体部署是基于:centos7+nginx+uwsgi+python3+Flask之上做的。
本地windows开发测试好了我的OCR项目,现在要部署我的OCR项目到云服务器上验证下。
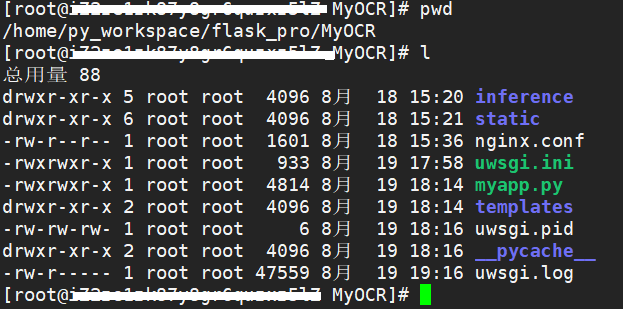
第一步:打包上传Flask项目代码到服务器指定目录下
如图:
第二步:安装 Flask,PaddleOCR 等相关依赖包
手工启动myapp.py,查看缺少哪些包,就下载缺少的包即可。

第三步:安装Linux版本 paddlepaddle 百度飞浆
进入百度飞浆官网安装地址:
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/windows-pip.html
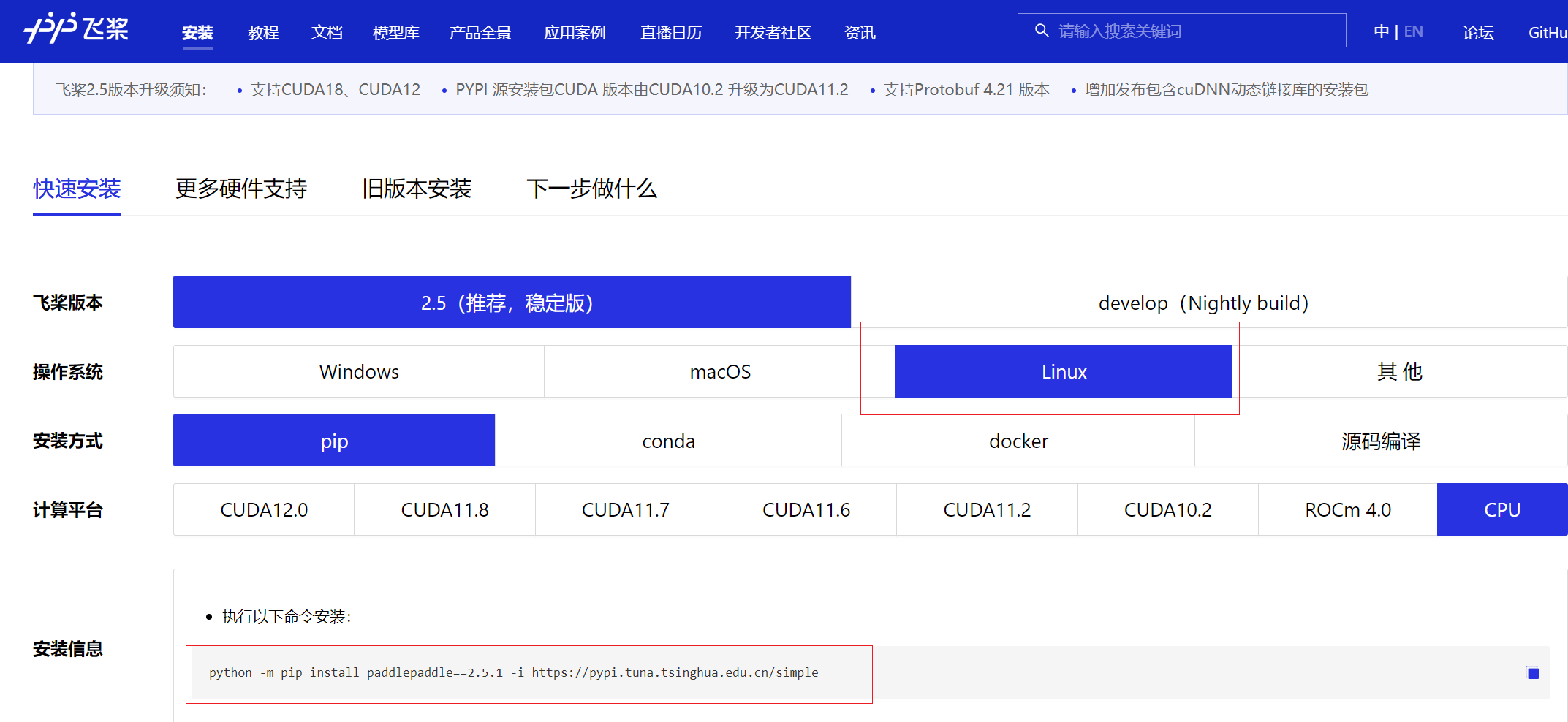
到服务器上执行下载命令:
python -m pip install paddlepaddle==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
第四步:验证PaddleOCR 安装
执行要部署的 myapp.py 启动程序,其他验证方法也可以。
注意事项:
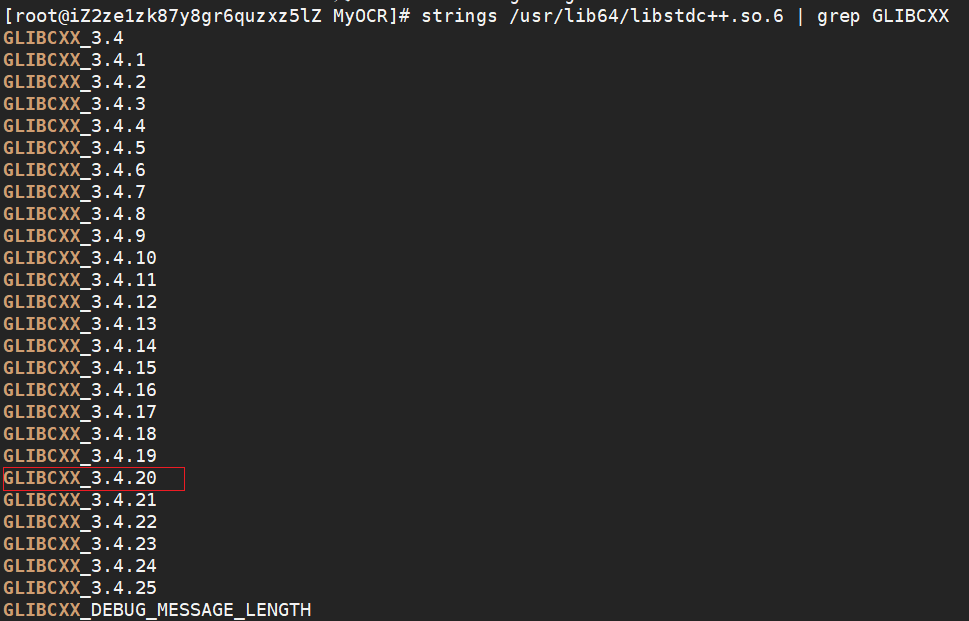
一般在服务器上第一次安装 PaddleOCR 都会出现一个libstdc++.so.6问题
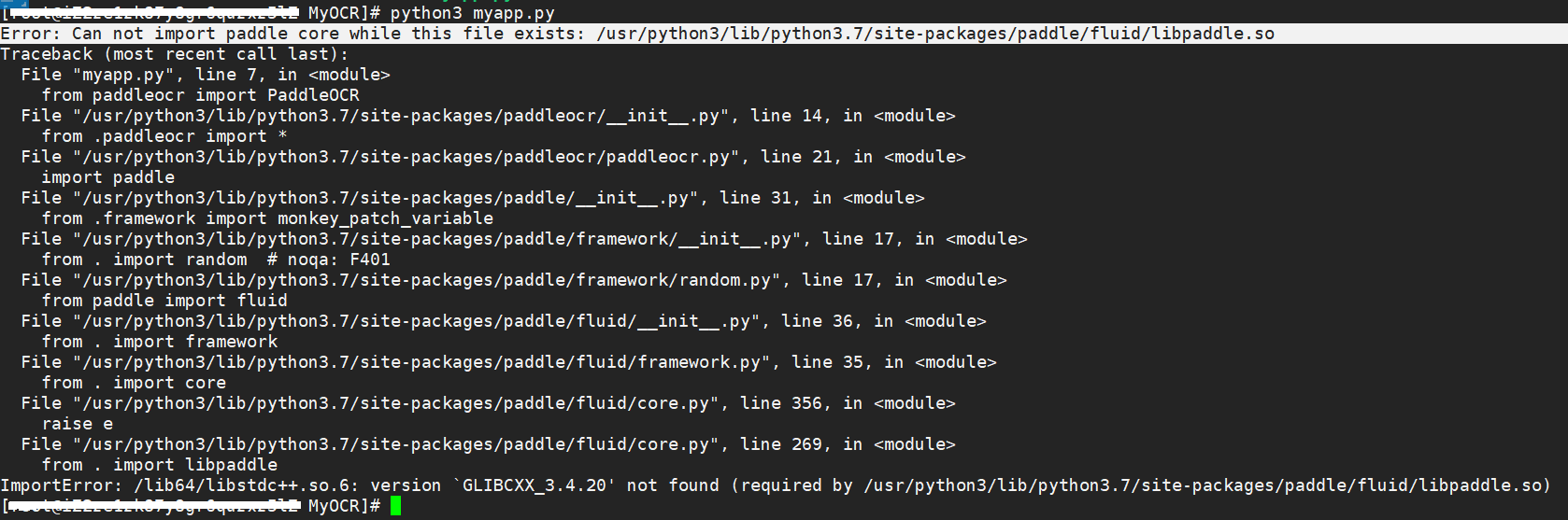
/lib64/libstdc++.so.6: version `GLIBCXX_3.4.20' not found问题解决方法:
1,查看验证是否缺少缺少GLIBCXX_3.4.20
[root@localhost]# strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
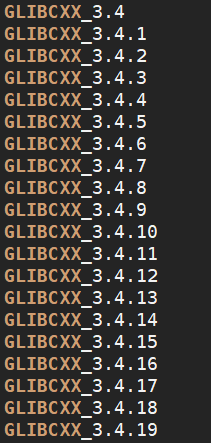
发现少了GLIBCXX_3.4.20,解决方法是升级libstdc++.
然后我在网上找了很多关于升级libstdc++方法,尝试了10几种方法都没实现,可能跟服务器版本有关吧。
最后通过直接搜索,linux 下载 libstdc++.so.6.0.25
找到 libstdc++.so.6.0.25 下载链接:
https://download.csdn.net/download/qq_39466755/87812280?utm_source=bbsseo
花点积分下载到 libstdc++.so.6.0.25 文件。
然后上传文件到服务器, /usr/lib64 目录下
然后执行下列步骤:
0、进入当前目录:
[root@localhost]# cd /usr/lib64
1、删除 旧的libstdc++.so.6软连接
[root@localhost]# rm -rf libstdc++.so.6
2、创建新的软连接指向6.0.25版本的库
[root@localhost]# ln -s libstdc++.so.6.0.25 libstdc++.so.6
3、查看libstdc++.so文件
[root@localhost]# ls -lrt libstdc++.so*
-rwxr-xr-x 1 root root 995840 9月 30 2020 libstdc++.so.6.0.19
-rwxrwxr-x 1 root root 12129824 8月 19 17:01 libstdc++.so.6.0.25
lrwxrwxrwx 1 root root 19 8月 19 17:18 libstdc++.so.6 -> libstdc++.so.6.0.25
3、再运行检查GLIBCXX版本
[root@localhost]# strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
第五步:配置uwsgi.ini文件
[uwsgi]
# 这里是你的项目根目录路径
chdir = /home/py_workspace/flask_pro/MyOCR
# 模块名,这里用myapp; myapp:app是指定一个Python的可执行文件,它包括Flask的代码from myapp.app import app
module = myapp:app
# 因为app是启动整个服务的入口,所以是app
callable = app
# 是否启动主进程来管理其他进程
master = true
# 设置进程数
processes = 5
# 每个进程的线程个数
threads = 10
# 这里的sock文件不是某个现成的文件,也不需要事先创建,运行时会自动创建,文件名也是自己定
# socket = /tmp/myapp.sock
# 套接字方式的 IP地址:端口号,搭配 nginx使用socket
socket = 127.0.0.1:8000
# chmod-socket = 660
# 当服务器退出时自动清理环境
vacuum = true
# 超时时间,单位秒
harakiri = 60
# 服务的pid记录文件
pidfile = uwsgi.pid
# 服务的日志文件位置
daemonize = uwsgi.log
配置完成后,我们就可以使用下面的命令启动 uWSGI 了:
#启动 uwsgi 命令
$ cd ./flask_pro/MyOCR # 项目文件夹,uwsgi.ini 配置文件 下执行
$ uwsgi --ini uwsgi.ini
#停止 uwsgi 命令
$ uwsgi --stop uwsgi.pid
第六步:配置 nginx.conf 文件
#user root;
#worker_processes 1; events {
worker_connections 1024;
} http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
gzip on;
# server被称为虚拟主机,可以有多个
# 第2个主机
server {
# 监听端口号
listen 80;
# 你的服务器ip
server_name xx.xx.xx.xx;
charset utf-8;
client_max_body_size 75M; # adjust to taste location / {
# 将nginx所有请求转到uwsgi
include uwsgi_params;
# uwsgi的ip与端口
uwsgi_pass 127.0.0.1:8000;
} location /static {
# 静态文件目录
alias /home/py_workspace/flask_pro/MyOCR/static;
} error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
} }
配置完成后,启动nginx.
cd /usr/sbin #进入执行路径
复制代码
#启动 nginx
./nginx
#重启 nginx
./nginx -s reload
#停止 nginx
./nginx -s stop
第七步:打开浏览器验证网址
经过 uwsgi 服务器和 nginx 服务器 部署配置,启动完成后,基本就结束部署了,打开浏览器,查看部署的第一个Flask项目。
xx.xx.xx.xx 代表你的云服务器对外访问IP,因为nginx 配置默认端口为 80 , 云服务器一般开通了80端口访问权限,然后 uwsgi + Flask 配置了 8000端口,需要在云服务器官网,自己添加 8000 端口访问权限,这块自行网上搜索解决,网络端口解决了,直接输入下面网址查看部署结果。
部署完成后可能出现问题二: 打开 http://xx.xx.xx.xx/upload ,报错无法访问:
Not Found
The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
通过nginx访问时自动加末尾斜杠的问题, 配置完nginx之后访问每次都是404,经过原因排查,发现是这么回事:
在后端代码中,我写的是@app.route(‘/info’,methods=[‘GET’,‘POST’])这样的。
当不使用uwsgi+nginx部署,而是用flask自带的web服务器进行测试时,我访问xxxx:xx/info,可以访问到界面。
但是通过nginx访问时,nginx会把所有末尾不带斜杠的非文件类请求都加上斜杠,并且给出301回应,然后重定向到有斜杠的URL下。
这可能是因为其他一些比较经典的WEB开发语言中请求往往是一个文件如.php,.aspx,.html等,而python的框架实际上是把一个“目录”节点作为一个html文件给出了。
这就使得末尾要加上一个斜杠,才能让nginx知道这是一个指向目录的请求。
解决的办法也很简单,通过浏览器直接发起GET请求的页面(也就是一定要经过nginx访问的),python代码和html代码里,路由设置时记得加上末尾的斜杠就好了。
因为不同过键盘打到浏览器地址栏这种方式的GET请求(比如页面的一个超链接的href值,或者AJAX发起指向的URL)都是不会自动补齐斜杠的,所以其他那些页面也都不会受影响。
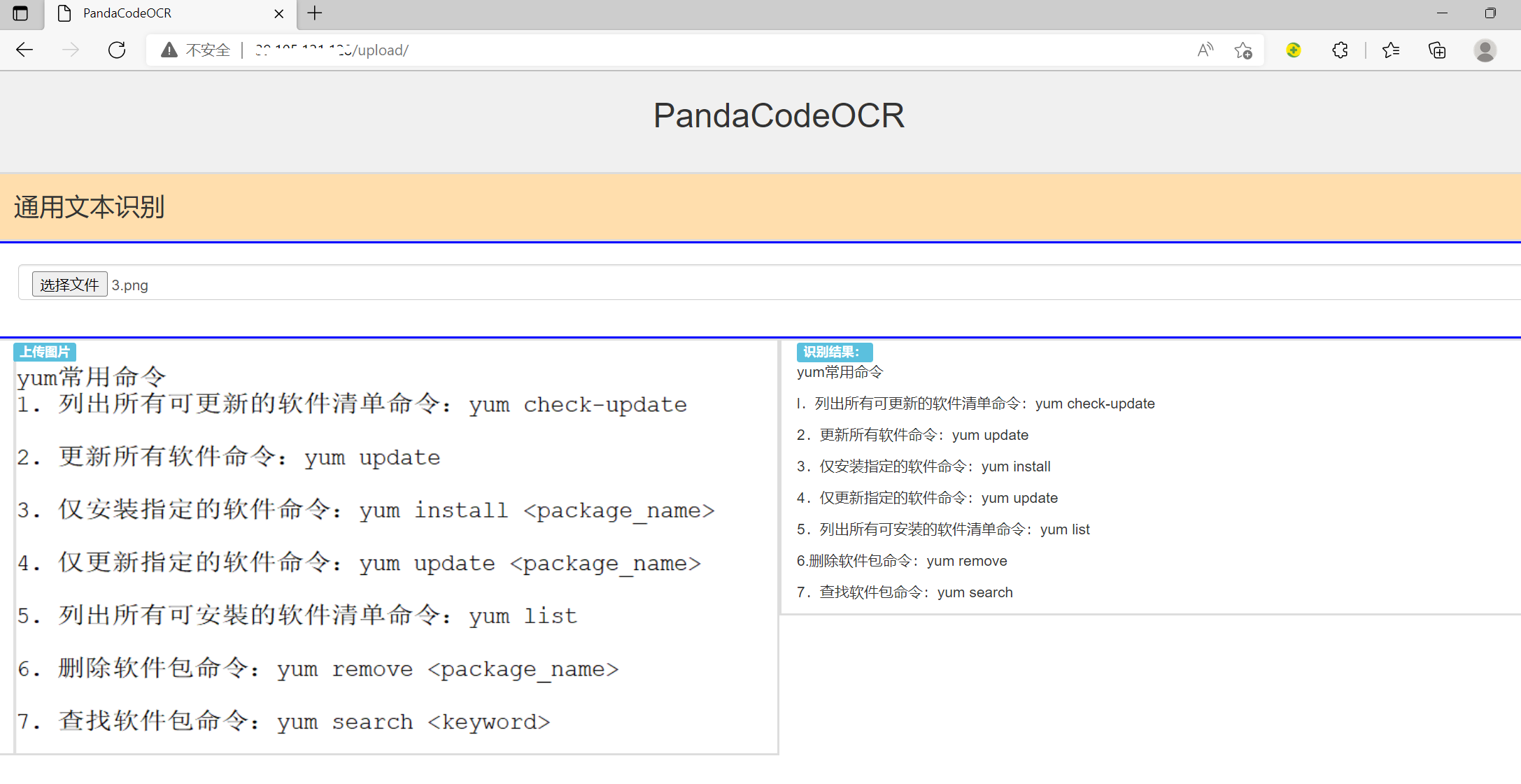
-- 进入我的OCR页面
http://xx.xx.xx.xx/upload/
--------------------------------end --------------------------------
云服务器下如何部署Flask项目详细操作步骤的更多相关文章
- CentOS7下部署Django项目详细操作步骤
严格按下面步骤 一.更新系统软件包 yum update -y 二.安装软件管理包和可能使用的依赖 yum -y groupinstall "Development tools" ...
- 转载:CentOS7下部署Django项目详细操作步骤
部署是基于:centos7+nginx+uwsgi+python3+django 之上做的 文章转自:Django中文网 https://www.django.cn/article/sh ...
- Linux云服务器下Tomcat部署超详细
基于阿里云Centos 7服务器的Tomcat 项目部署 工具:一台安装jdk1.8的Centos 6/7.X 云服务器(64位) Putty ssh远程连接云服务器的软件 FileZillaCli ...
- Linux云服务器下Tomcat部署
基于阿里云Centos 7服务器的Tomcat 项目部署 工具:一台安装jdk1.8的Centos 6/7.X 云服务器(64位) Putty ssh远程连接云服务器的软件 FileZillaCli ...
- 基于阿里云服务器Linux系统部署JavaWeb项目
前段时间刚完成一个JavaWeb项目,想着怎么部署到服务器上,边学边做,花了点时间终于成功部署了,这里总结记录一下过程中所遇到的问题及解决方法.之所以选择阿里云,考虑到它是使用用户最多也是最广泛的云服 ...
- Linux下自动备份MySQL数据库详细操作步骤(转载)
环境说明操作系统:CentOSIP:192.168.150.214Oracle数据库版本:Oracle11gR2用户:root 密码:123456端口:3306数据库:ts_0.ts_1.ts_2.t ...
- linux下如何部署php项目?
linux下部署php项目环境可以分为两种,一种使用Apache,php,mysql的压缩包安装,一种用yum命令进行安装. 使用三种软件的压缩包进行安装,需要手动配置三者之间的关系.apache和p ...
- 部署Flask项目到腾讯云服务器CentOS7
部署Flask项目到腾讯云服务器CentOS7 安装git yum install git 安装依赖包 支持SSL传输协议 解压功能 C语言解析XML文档的 安装gdbm数据库 实现自动补全功能 sq ...
- 【配置阿里云 I】申请配置阿里云服务器,并部署IIS和开发环境,项目上线经验
https://blog.csdn.net/vapaad1/article/details/78769520 最近一年在实验室做web后端开发,涉及到一些和服务器搭建及部署上线项目的相关经验,写个帖子 ...
- 【史上最全】申请配置阿里云服务器,并部署IIS和开发环境,项目上线经验
最近一年在实验室做web后端开发,涉及到一些和服务器搭建及部署上线项目的相关经验,写个帖子和小伙伴们分享,一同进步! 首先谈一下,为什么越来越多中小型公司/实验室,部署项目的趋势都是在云服务器而不是普 ...
随机推荐
- OpenCV4.1.0编译时提示“CV_BGR2GRAY”: 未声明的标识符
OpenCV版本为4.1.0 使用CV_BGR2GRAY时报错: "CV_BGR2GRAY": 未声明的标识符 解决方法一:添加头文件:#include <opencv2/i ...
- 意外之喜——黑夜 CrossFire!!!
在日常逛L站时,偶然发现了"友链"功能,机缘巧合下进入了specialhua的博客,又被吸引着点进了其中一篇博客,于是便通过specialhua的博客看到了黑夜的这篇文章,感觉就像 ...
- Qt Quick 实现一个右下角弹出消息的组件
目录 开发环境 简介 预览图 如何使用 代码 main.qml MessageView.qml Background.qml ScroolBar.qml MessageQueueView.qml 开发 ...
- 手把手教你喂养 DeepSeek 本地模型
上篇文章<手把手教你部署 DeepSeek 本地模型>首发是在公众号,但截止目前只有500多人阅读量,而在自己博客园BLOG同步更新的文章热度很高,目前已达到50000+的阅读量,流量是公 ...
- linux mint 安装蓝牙
sudo apt-get install blueman 安装新的 sudo apt-get remove blueberry 卸载旧的
- FLink怎么做压力测试和监控?
我们一般碰到的压力来自以下几个方面: 一,产生数据流的速度如果过快,而下游的算子消费不过来的话,会产生背压问题.背压的监控可以使用Flink Web UI(localhost:8081)来可视化监控, ...
- 一文详解 MySQL 中的间隙锁
博客:https://www.emanjusaka.com 博客园:https://www.cnblogs.com/emanjusaka 公众号:emanjusaka的编程栈 by emanjusak ...
- 如何正确配置 .gitignore 以忽略特定文件夹下的文件(除指定子文件夹外)
在使用 Git 进行版本控制时,.gitignore 文件是一个非常有用的工具,可以帮助我们忽略不需要跟踪的文件或文件夹.然而,有时我们需要忽略某个文件夹下的所有内容,但保留其中的某个子文件夹.本文将 ...
- RLHF各种训练算法科普
强化学习在LLM中的应用越来越多了,本文针对常见的几种训练算法,用生活中的例子做类比,帮助理解相关概念. 包括:PPO.DRO.DPO.β-DPO.sDPO.RSO.IPO.GPO.KTO.ORPO. ...
- WPF DataTemplate DataContext 绑定问题
当使用DataTemplate时,需要用数据绑定,设置数据绑定的方式可参考: https://supportcenter.devexpress.com/ticket/details/t736087/d ...