MongoDB索引优化的艺术:从基础原理到性能调优
title: MongoDB索引优化的艺术:从基础原理到性能调优实战
date: 2025/05/21 18:08:22
updated: 2025/05/21 18:08:22
author: cmdragon
excerpt:
MongoDB索引优化与性能调优的核心策略包括:索引基础原理,如单字段、复合、唯一和TTL索引;索引创建与管理,通过FastAPI集成Motor实现;查询性能优化,使用Explain分析、覆盖查询和聚合管道优化;实战案例,如电商平台订单查询优化;常见报错解决方案,如索引创建失败、查询性能下降和文档扫描过多问题。这些策略能显著提升查询速度和系统性能。
categories:
- 后端开发
- FastAPI
tags:
- MongoDB
- 索引优化
- 性能调优
- FastAPI
- 查询分析
- 聚合管道
- 错误处理

扫描二维码
关注或者微信搜一搜:编程智域 前端至全栈交流与成长
探索数千个预构建的 AI 应用,开启你的下一个伟大创意:https://tools.cmdragon.cn/
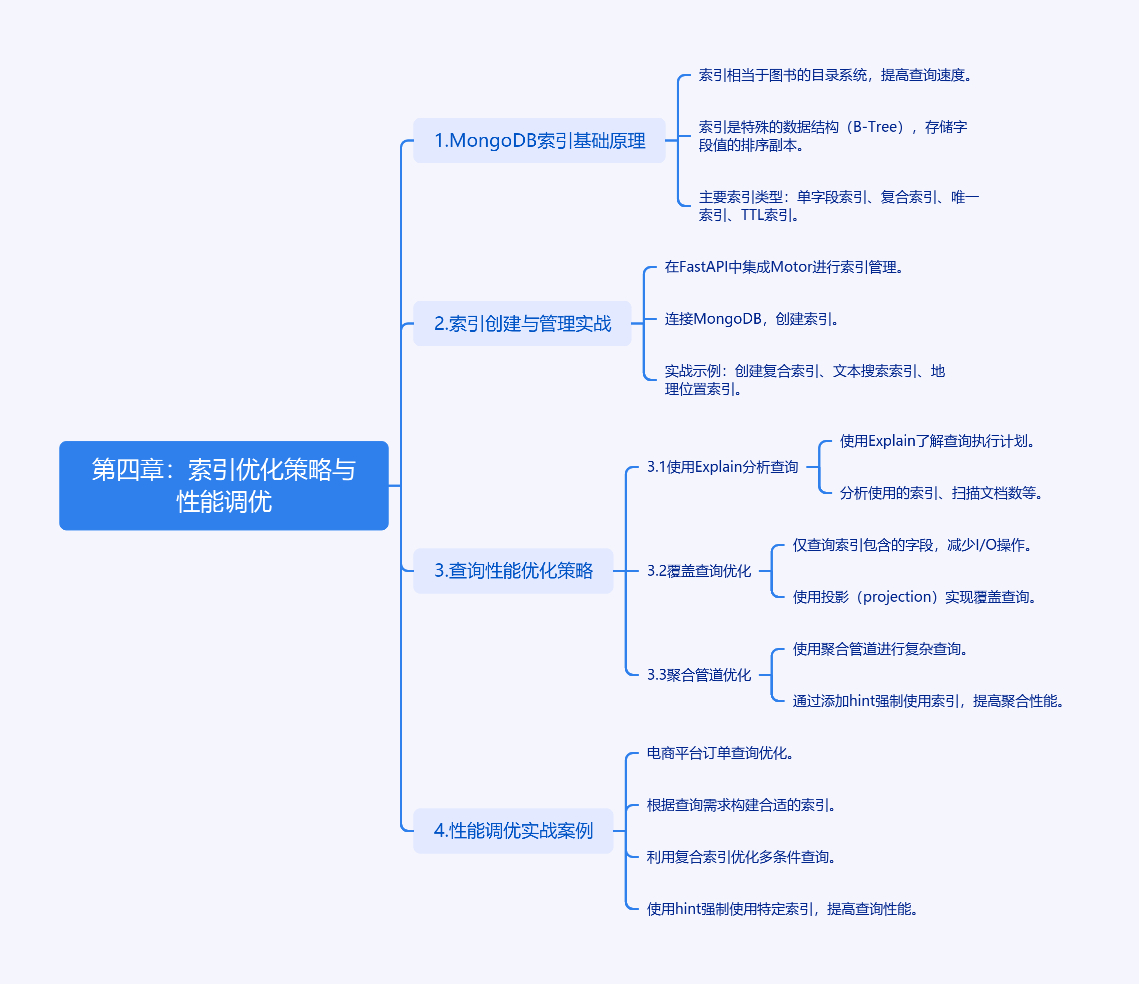
第四章:索引优化策略与性能调优
1. MongoDB索引基础原理
在MongoDB中,索引相当于图书的目录系统。当集合存储量达到百万级时,合理的索引设计能让查询速度提升10-100倍。索引本质上是特殊的数据结构(B-Tree),存储着字段值的排序副本。
主要索引类型:
# 单字段索引示例
async def create_single_index():
await db.products.create_index("name")
# 复合索引示例(注意字段顺序)
async def create_compound_index():
await db.orders.create_index([("user_id", 1), ("order_date", -1)])
# 唯一索引示例
async def create_unique_index():
await db.users.create_index("email", unique=True)
# TTL索引示例(自动过期)
async def create_ttl_index():
await db.logs.create_index("created_at", expireAfterSeconds=3600)
2. 索引创建与管理实战
在FastAPI中集成Motor进行索引管理的最佳实践:
from fastapi import APIRouter
from motor.motor_asyncio import AsyncIOMotorClient
from pydantic import BaseModel
router = APIRouter()
class Product(BaseModel):
name: str
price: float
category: str
# 连接MongoDB
client = AsyncIOMotorClient("mongodb://localhost:27017")
db = client["ecommerce"]
@router.on_event("startup")
async def initialize_indexes():
# 创建复合索引
await db.products.create_index([("category", 1), ("price", -1)])
# 文本搜索索引
await db.products.create_index([("name", "text")])
# 地理位置索引(需2dsphere)
await db.stores.create_index([("location", "2dsphere")])
3. 查询性能优化策略
3.1 使用Explain分析查询
async def analyze_query():
cursor = db.products.find({"price": {"$gt": 100}})
explain = await cursor.explain()
print(f"使用的索引:{explain['queryPlanner']['winningPlan']['inputStage']['indexName']}")
print(f"扫描文档数:{explain['executionStats']['totalDocsExamined']}")
3.2 覆盖查询优化
async def covered_query():
# 只查询索引包含的字段
projection = {"_id": 0, "name": 1, "category": 1}
cursor = db.products.find({"category": "electronics"}, projection)
async for doc in cursor:
print(doc)
3.3 聚合管道优化
async def optimized_aggregation():
pipeline = [
{"$match": {"status": "completed"}},
{"$sort": {"total_amount": -1}},
{"$group": {
"_id": "$user_id",
"total_spent": {"$sum": "$total_amount"}
}},
{"$limit": 10}
]
# 添加hint强制使用索引
cursor = db.orders.aggregate(pipeline).hint([("status", 1), ("total_amount", -1)])
results = await cursor.to_list(length=10)
return results
4. 性能调优实战案例
电商平台订单查询优化:
class OrderQuery(BaseModel):
user_id: str
start_date: datetime
end_date: datetime
min_amount: float = None
@router.post("/orders/search")
async def search_orders(query: OrderQuery):
# 构建查询条件
conditions = {
"user_id": query.user_id,
"order_date": {"$gte": query.start_date, "$lte": query.end_date}
}
if query.min_amount:
conditions["total_amount"] = {"$gte": query.min_amount}
# 使用复合索引优化查询
projection = {"_id": 0, "order_id": 1, "total_amount": 1, "items": 1}
cursor = db.orders.find(
conditions,
projection
).sort("order_date", -1).hint([("user_id", 1), "order_date", -1)])
return await cursor.to_list(length=100)
5. 课后Quiz
Q1:以下哪种索引顺序更适合查询db.orders.find({"status":"shipped", "total":{$gt:100}}).sort("ship_date":1)?
A) (status, total, ship_date)
B) (status, ship_date, total)
C) (ship_date, status, total)
正确答案:A
解析:等值查询字段(status)应放在最前,范围查询字段(total)在后,排序字段(ship_date)在最后可以避免内存排序
Q2:如何判断查询是否使用了覆盖索引?
A) 检查执行时间
B) 查看explain输出中的totalDocsExamined
C) 观察返回字段是否都在索引中
正确答案:C
解析:覆盖查询需要所有返回字段都包含在索引中,且查询不包含_id字段或显式排除
6. 常见报错解决方案
报错1:OperationFailure: Error creating index
原因:尝试在已存在重复值的字段上创建唯一索引
解决:
# 先清理重复数据
async def clean_duplicate_emails():
pipeline = [
{"$group": {"_id": "$email", "dups": {"$push": "$_id"}, "count": {"$sum": 1}}},
{"$match": {"count": {"$gt": 1}}}
]
async for dup in db.users.aggregate(pipeline):
await db.users.delete_many({"_id": {"$in": dup["dups"][1:]}})
报错2:查询性能突然下降
可能原因:索引碎片化或统计信息过期
解决:
# 重建索引
async def rebuild_indexes():
await db.products.drop_index("category_1_price_-1")
await db.products.create_index([("category", 1), ("price", -1)])
报错3:Executor error during find command: Too many documents scanned
原因:查询未命中索引或索引选择不当
解决:
- 使用explain分析查询计划
- 添加适当的索引
- 优化查询条件,减少扫描范围
运行环境要求:
- Python 3.8+
- FastAPI==0.78.0
- motor==3.1.1
- pydantic==1.10.7
- uvicorn==0.18.2
安装命令:
pip install fastapi==0.78.0 motor==3.1.1 pydantic==1.10.7 uvicorn==0.18.2
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:MongoDB索引优化的艺术:从基础原理到性能调优实战 | cmdragon's Blog
往期文章归档:
- 解锁FastAPI与MongoDB聚合管道的性能奥秘 | cmdragon's Blog
- 异步之舞:Motor驱动与MongoDB的CRUD交响曲 | cmdragon's Blog
- 异步之舞:FastAPI与MongoDB的深度协奏 | cmdragon's Blog
- 数据库迁移的艺术:FastAPI生产环境中的灰度发布与回滚策略 | cmdragon's Blog
- 数据库迁移的艺术:团队协作中的冲突预防与解决之道 | cmdragon's Blog
- 驾驭FastAPI多数据库:从读写分离到跨库事务的艺术 | cmdragon's Blog
- 数据库事务隔离与Alembic数据恢复的实战艺术 | cmdragon's Blog
- FastAPI与Alembic:数据库迁移的隐秘艺术 | cmdragon's Blog
- 飞行中的引擎更换:生产环境数据库迁移的艺术与科学 | cmdragon's Blog
- Alembic迁移脚本冲突的智能检测与优雅合并之道 | cmdragon's Blog
- 多数据库迁移的艺术:Alembic在复杂环境中的精妙应用 | cmdragon's Blog
- 数据库事务回滚:FastAPI中的存档与读档大法 | cmdragon's Blog
- Alembic迁移脚本:让数据库变身时间旅行者 | cmdragon's Blog
- 数据库连接池:从银行柜台到代码世界的奇妙旅程 | cmdragon's Blog
- 点赞背后的技术大冒险:分布式事务与SAGA模式 | cmdragon's Blog
- N+1查询:数据库性能的隐形杀手与终极拯救指南 | cmdragon's Blog
- FastAPI与Tortoise-ORM开发的神奇之旅 | cmdragon's Blog
- DDD分层设计与异步职责划分:让你的代码不再“异步”混乱 | cmdragon's Blog
- 异步数据库事务锁:电商库存扣减的防超卖秘籍 | cmdragon's Blog
- FastAPI中的复杂查询与原子更新指南 | cmdragon's Blog
- 深入解析Tortoise-ORM关系型字段与异步查询 | cmdragon's Blog
- FastAPI与Tortoise-ORM模型配置及aerich迁移工具 | cmdragon's Blog
- 异步IO与Tortoise-ORM的数据库 | cmdragon's Blog
- FastAPI数据库连接池配置与监控 | cmdragon's Blog
- 分布式事务在点赞功能中的实现 | cmdragon's Blog
- Tortoise-ORM级联查询与预加载性能优化 | cmdragon's Blog
- 使用Tortoise-ORM和FastAPI构建评论系统 | cmdragon's Blog
- 分层架构在博客评论功能中的应用与实现 | cmdragon's Blog
- 深入解析事务基础与原子操作原理 | cmdragon's Blog
- 掌握Tortoise-ORM高级异步查询技巧 | cmdragon's Blog
- FastAPI与Tortoise-ORM实现关系型数据库关联 | cmdragon's Blog
- Tortoise-ORM与FastAPI集成:异步模型定义与实践 | cmdragon's Blog
- 异步编程与Tortoise-ORM框架 | cmdragon's Blog
- FastAPI数据库集成与事务管理 | cmdragon's Blog
- XML Sitemap
MongoDB索引优化的艺术:从基础原理到性能调优的更多相关文章
- MySQL性能优化总结___本文乃《MySQL性能调优与架构设计》读书笔记!
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- GO学习-(21) Go语言基础之Go性能调优
Go性能调优 在计算机性能调试领域里,profiling 是指对应用程序的画像,画像就是应用程序使用 CPU 和内存的情况. Go语言是一个对性能特别看重的语言,因此语言中自带了 profiling ...
- 艾编程coding老师:深入JVM底层原理与性能调优
1. Java内存模型JMM,内存泄漏及解决方法:2. JVM内存划分:New.Tenured.Perm:3. 垃圾回收算法:Serial算法.并行算法.并发算法:4. JVM性能调优,CPU负载不足 ...
- OCM_第十四天课程:Section6 —》数据库性能调优_各类索引 /调优工具使用/SQL 优化建议
注:本文为原著(其内容来自 腾科教育培训课堂).阅读本文注意事项如下: 1:所有文章的转载请标注本文出处. 2:本文非本人不得用于商业用途.违者将承当相应法律责任. 3:该系列文章目录列表: 一:&l ...
- MySQL性能调优与架构设计——第8章 MySQL数据库Query的优化
第8章 MySQL数据库Query的优化 前言: 在之前“影响 MySQL 应用系统性能的相关因素”一章中我们就已经分析过了Query语句对数据库性能的影响非常大,所以本章将专门针对 MySQL 的 ...
- MySql(十):MySQL性能调优——MySQL Server性能优化
本章主要通过针对MySQL Server( mysqld)相关实现机制的分析,得到一些相应的优化建议.主要涉及MySQL的安装以及相关参数设置的优化,但不包括mysqld之外的比如存储引擎相关的参数优 ...
- MySQL性能调优与架构设计——第10章 MySQL数据库Schema设计的性能优化
第10章 MySQL Server性能优化 前言: 本章主要通过针对MySQL Server(mysqld)相关实现机制的分析,得到一些相应的优化建议.主要涉及MySQL的安装以及相关参数设置的优化, ...
- MySQL基础普及《MySQL管理之道:性能调优、高可用与监控》
最近工作的内容涉及MySQL运维内容,陆陆续续读了几本相关的书,其中一本是<MySQL管理之道:性能调优.高可用与监控>. 内容涵盖性能调优(包括sql优化等).备份.高可用,以及读写分离 ...
- SQL Server调优系列基础篇 - 性能调优介绍
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- 性能调优之MYSQL高并发优化
性能调优之MYSQL高并发优化 一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之 ...
随机推荐
- .NET周刊【2月第3期 2025-02-16】
国内文章 我们是如何解决abp身上的几个痛点 https://www.cnblogs.com/jackyfei/p/18709265 张飞洪分享了abp框架在.net社区的使用经验,认为其在模块化.D ...
- 通过fetch_mcp,让Cline能够获取网页内容。
fetch_mcp介绍 GitHub地址:https://github.com/zcaceres/fetch-mcp 此MCP服务器提供了以多种格式(包括HTML.JSON.纯文本和Markdown) ...
- Ubuntu通过VMware虚拟机安装步骤
1.下载Ubuntu系统镜像 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17.这个错误需要BIOS CPU里面设置一下,具体问度娘. 18 ...
- 【MATLAB习题】四杆机构的运动学参数求解
1.问题描述 2. 推导过程 3. matlab代码 最新版代码 直接采用求微分的方式得到角度,角速度等数值解,速度慢,但是代码少,容易看懂(矩阵看起来真难受). 以前做的一个博客文章用的是矩阵运算求 ...
- Redis压测脚本及持久化机制
Redis压测脚本及持久化机制 Redis性能压测脚本 Redis的所有数据是保存在内存当中的,得益于内存高效的读写性能,Redis的性能是非常强悍的.但是,内存的缺点是断电即丢失,所以,在实际项目中 ...
- mongodb删除某个字段
如下 db.yourcollection.update({ "需要删除的字段": { "$exists": true } }, { "$unset&q ...
- [SDR] GNU Radio 系列教程 —— GNU Radio RX PDU (接收据包操作)的基础知识(超全)
目录 1 接收概述 2 相关块介绍 2.1 相关性估计器(Correlation Estimator) 2.2 多相时钟同步(Polyphase Clock Sync) 2.3 线性均衡器(Linea ...
- 关于IPMP
国际项目经理资质认证(International Project Manager Professional,简称IPMP)是国际项目管理协会(International Project Managem ...
- Pydantic根校验器:构建跨字段验证系统
title: Pydantic根校验器:构建跨字段验证系统 date: 2025/3/24 updated: 2025/3/24 author: cmdragon excerpt: Pydantic根 ...
- 深入浅出CPU眼中的函数调用&栈溢出攻击
深入浅出CPU眼中的函数调用--栈溢出攻击 原理解读 函数调用,大家再耳熟能详了,我们先看一个最简单的函数: #include <stdio.h> #include <stdlib. ...