ISCC2025破阵夺旗赛三阶段Misc详解 By Alexander
ISCC2025破阵夺旗赛三阶段Misc详解 By Alexander
写在前面:十八天吃石终于结束了,第一次就让我见到了这个比赛有多么的构式,平台是构式的,睡一觉就1000解了,全是对flag的渴望,对比赛的认可。
校赛阶段
书法大师
下载图片

随波逐流检测

有很多zip
foremost分离出来
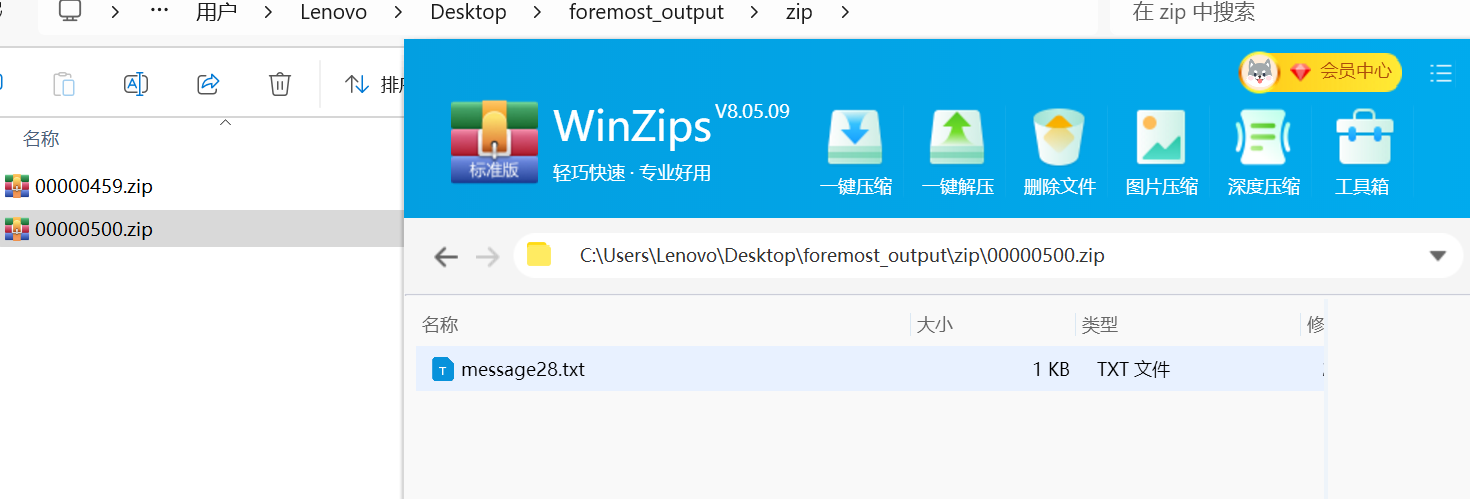
第二个zip(plus:当时解出来的时候,有50zip,50个全是flag,那我问你,你是把所有人flag放一起了?)
图片注释有密码
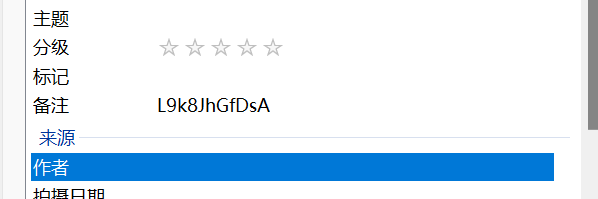
起初解法
import binascii
import base64
import os
import pyzipper
import requests
import urllib.parse
import json
# foremost -i 分离图片压缩包,然后删除所有压缩包内容为 message.txt 的,保留 message1-50.txt
# 压缩包密码在图片属性中
path = r"output_Wed_Apr_30_22_56_59_2025\zip"
pwd = 'L9k8JhGfDsA'
for file in os.listdir(path):
tmp_path = path + '\\' + file
zipfile = pyzipper.ZipFile(tmp_path)
zipfile.extractall(pwd=pwd.encode())
zipfile.close()
url = "https://unpkg.com/cnchar-data@1.1.0/draw/"
def get_strokes(x):
res = requests.get(url + urllib.parse.quote(x) + ".json")
j = json.loads(res.text)['strokes']
return str(hex(len(j))[2:])
data = ''
for i in range(1, 51):
data += open(f'message{i}.txt', 'r', encoding='UTF-8', errors='ignore').read() + ' '
output = ''
for char in data[:72]:
if char == ' ':
pass
else:
output += get_strokes(char)
print(output)
print(base64.b64decode(binascii.unhexlify(output)))
修复后的解法
解压
巧卫 正西 贝旗 太贝 丙乙 大马 没少 远国 为靠 巧切 片海 个一 那乙 西海 石真 马卫 为数 圾谁 早林 众谁 年圾 丙一 个罪 工数
53 56 4E 44 51 33 74 78 4F 54 4A 31 61 6A 5A 33 4D 6A 68 6A 66 51 3D 3D
每两位对应笔划组成2位16进制,base64解码
import base64
hex_str = "53564E44513374784F544A31616A5A334D6A686A66513D3D"
bytes_data = bytes.fromhex(hex_str)
decoded_data = base64.b64decode(bytes_data).decode('utf-8', errors='ignore')
print(decoded_data)
ISCC{q92uj6w28c}
反方向的钟
打开txt

Dx8CBEkFfE1XfBQtAwknAgVN
010检测到有多余隐写部分
零宽隐写
https://yuanfux.github.io/zero-width-web/
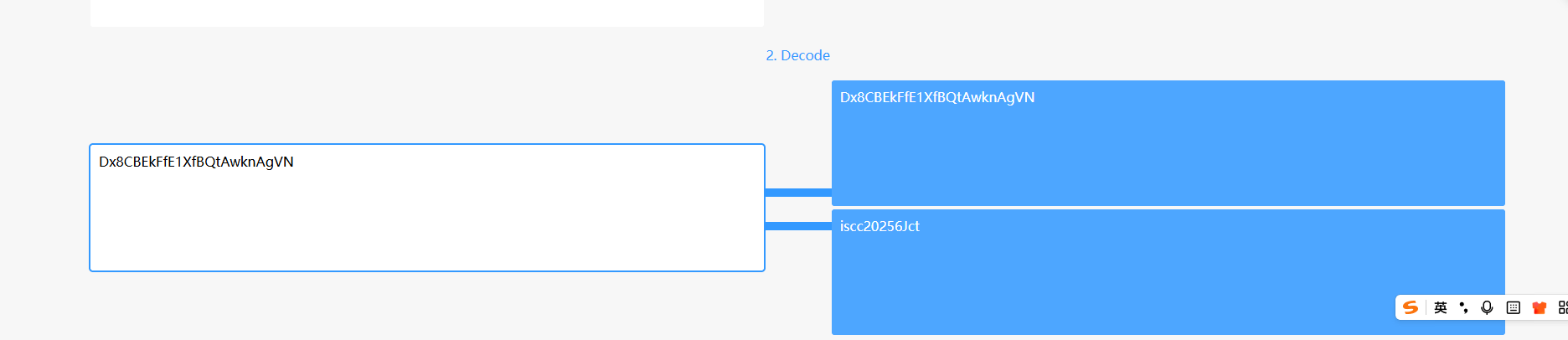
得到key,厨子xor
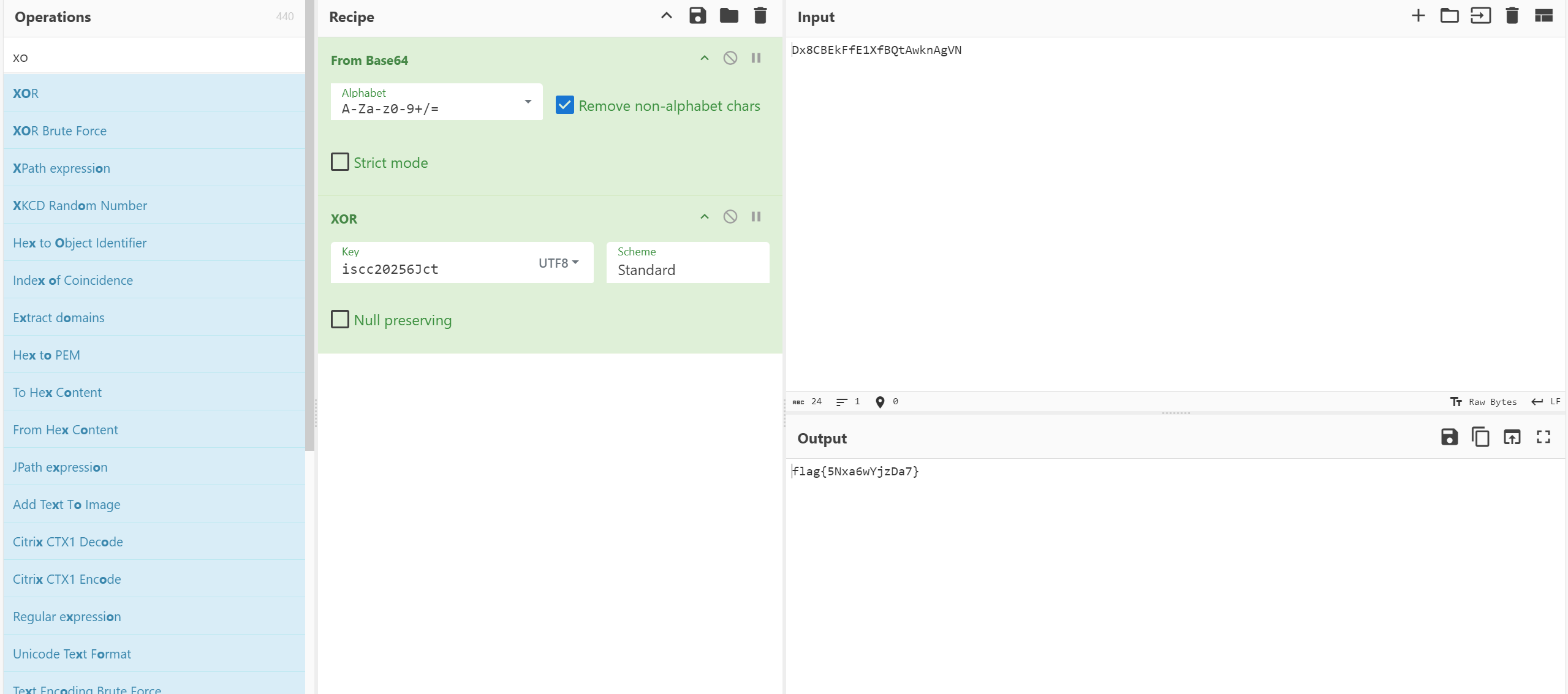
iscc{5Nxa6wYjzDa7}
区域赛
睡美人
ps:写之前提一嘴,爆6h密码的哥们你是真的牛。密码怎么来的我不说
下载图片
发现右下有神秘字符串,放大看

UGFzc3dvcmQgPSBzdW0oUilfc3VtKEcpX3N1bShCKQ==
Base64解码
Password = sum(R)_sum(G)_sum(B)
跟颜色通道R,G,B有关,结合题目提示,“红红红红红红绿绿绿蓝”。红绿蓝比例为6:3:1 加权乘上并提取图片颜色通道的值,编写脚本
from PIL import Image
# Open image (replace path)
path = r"Sleeping_Beauty_23.png"
img = Image.open(path).convert("RGB")
wr = 0.6
wg = 0.3
wb = 0.1
sum = 0.0
w, h = img.size
# Process pixels
for y in range(h):
for x in range(w):
r, g, b = img.getpixel((x, y))
# Calculate weighted value
p = round(r*wr + g*wg + b*wb, 1)
sum += p
sum = round(sum, 1)
print(f"Total weighted value: {sum}")
Total weighted value: 1375729349.6 //解压密码为1375729349.6
binwalk分离图片中的压缩包

用上述密码进行解压
得到一个wav文件
听一下
https://products.aspose.ai/total/zh/speech-to-text/#google_vignette
There is a hidden message in this sound file. Can you find it?
后面还有一串声音,audacity打开
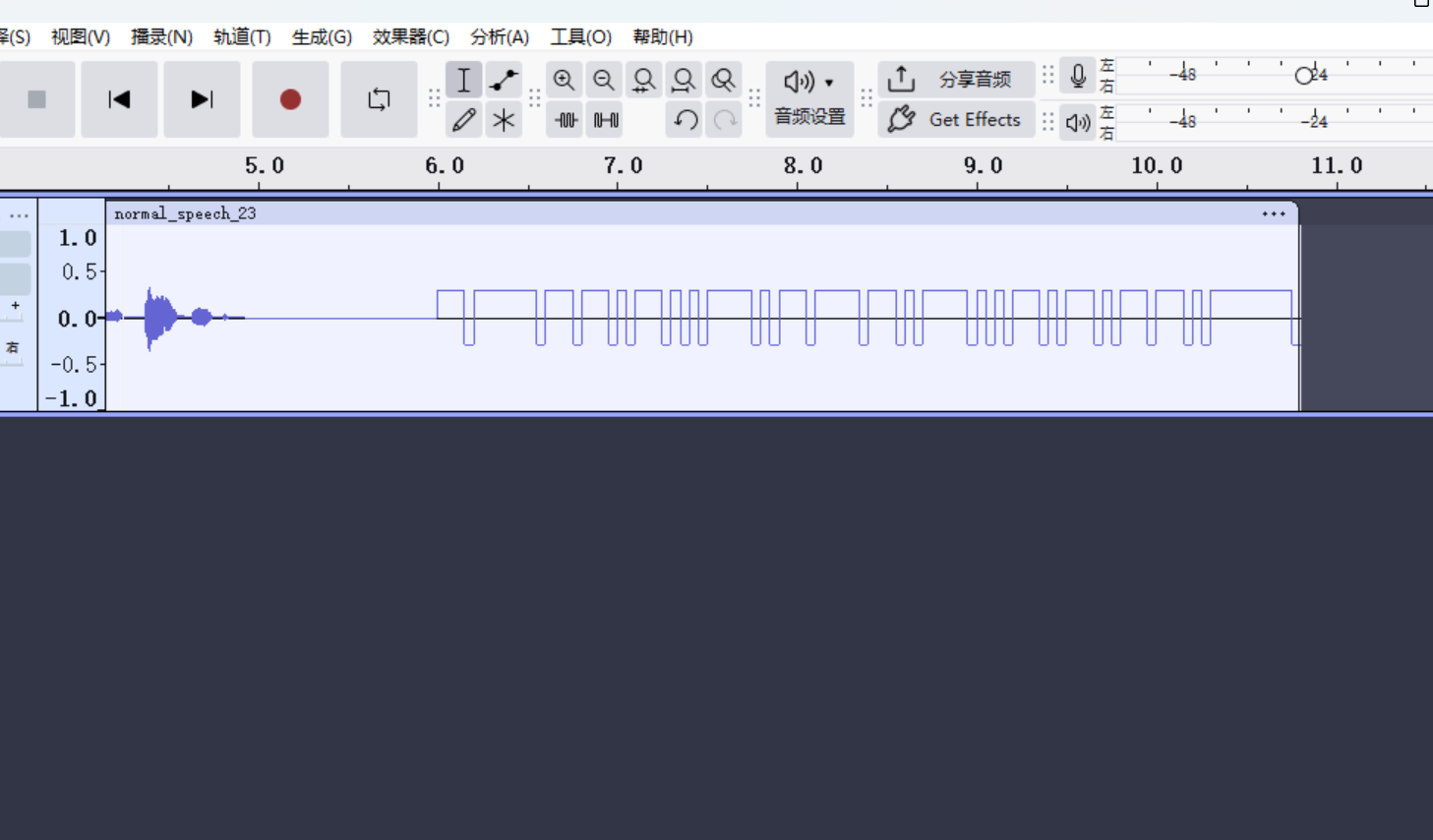
猜测为曼彻斯特编码,我们截取片段,对照序列,还原,最后二进制转字符
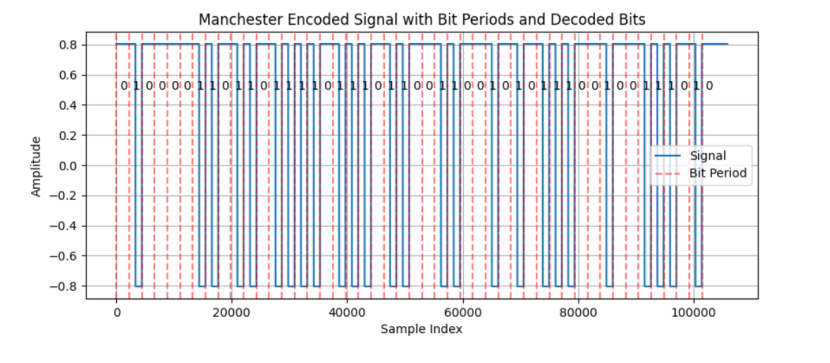
import scipy.io.wavfile as wavfile
import numpy as np
def load_audio_file(file_path):
try:
return wavfile.read(file_path)
except:
return None, None
def preprocess_audio_signal(audio_data):
return audio_data[:, 0] if audio_data.ndim == 2 else audio_data
def analyze_audio_segment(segment, threshold=0):
binary = (segment > threshold).astype(int)
return '0' if np.all(binary == 1) else '1' if np.any(np.diff(binary) == -1) else None
def decode_audio(audio_signal, sample_rate, start_sample, samples_per_segment):
total_samples = len(audio_signal)
return [
bit
for current_position in range(start_sample, total_samples, samples_per_segment)
if current_position + samples_per_segment <= total_samples
for bit in [analyze_audio_segment(audio_signal[current_position:current_position + samples_per_segment])]
if bit is not None
]
def binary_to_string(binary_data):
if not binary_data:
return ""
binary_str = ''.join(binary_data).ljust((len(binary_data) + 7) // 8 * 8, '0')
return ''.join(chr(int(binary_str[i:i+8], 2)) for i in range(0, len(binary_str), 8))
def decode_audio_file(file_path="normal_speech_23.wav", start_time_sec=6.0, segment_duration_sec=0.1):
sample_rate, audio_data = load_audio_file(file_path)
if sample_rate is None or audio_data is None:
return ""
audio_signal = preprocess_audio_signal(audio_data)
start_sample = int(start_time_sec * sample_rate)
samples_per_segment = int(segment_duration_sec * sample_rate)
if start_sample + samples_per_segment > len(audio_signal):
return ""
return binary_to_string(decode_audio(audio_signal, sample_rate, start_sample, samples_per_segment))
if __name__ == "__main__":
print("Decoded String:", decode_audio_file())
#Decoded String: Enigma
ISCC{Enigma}
签个到吧
010打开hint.zip,发现有png图片,我们foremost分离出来
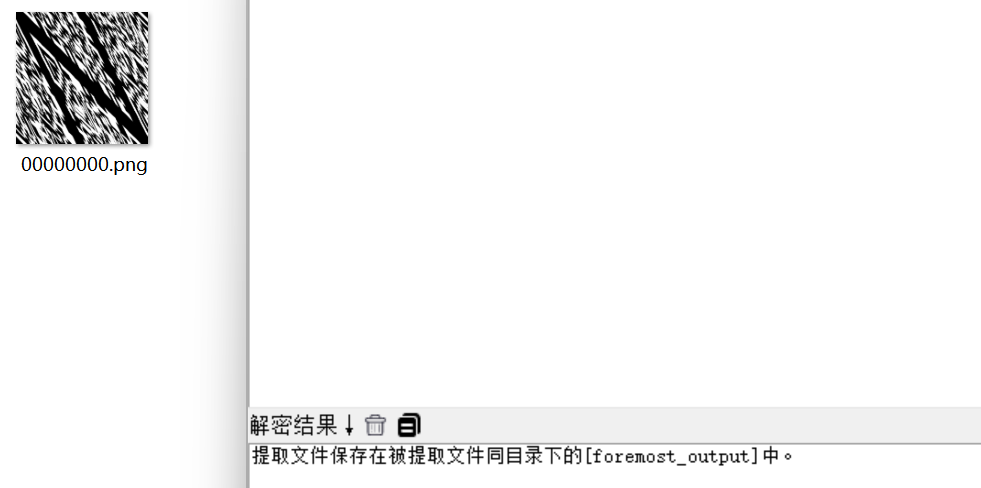
Stegsolve
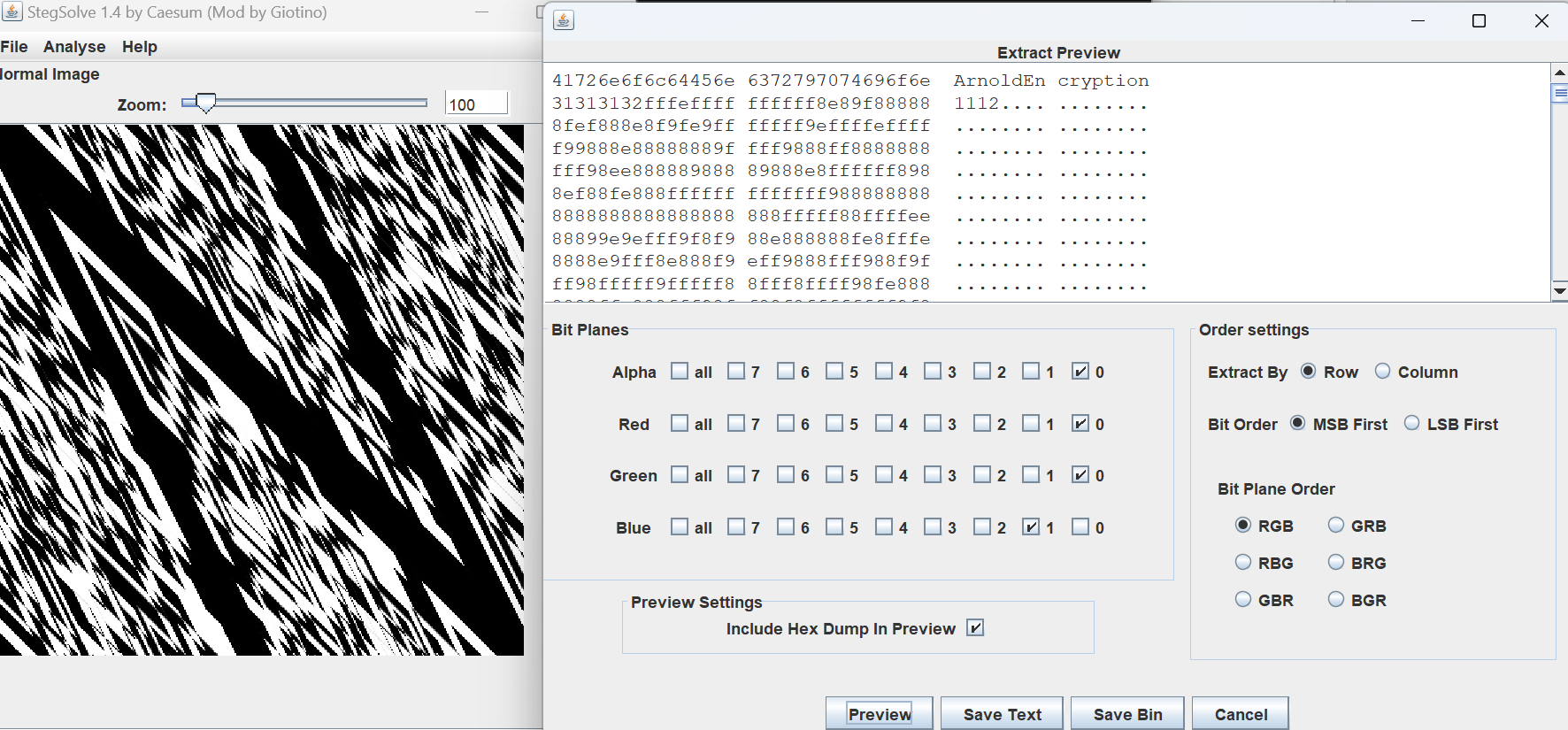
根据提示“变换一次再混入点东西”,是猫脸变换
工具爆破
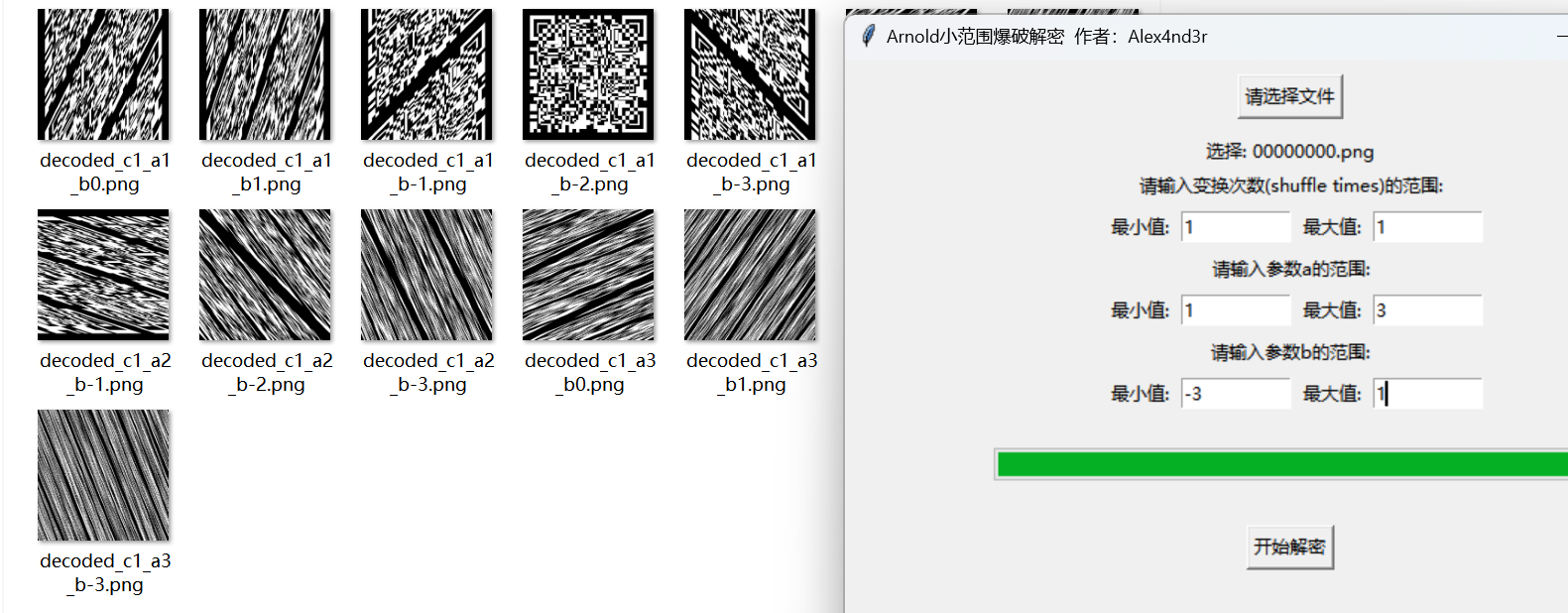
a=1,b=-2,shuffle times=1时得到图(工具是我自己写的)
再放个梭哈代码详细看blog:https://www.cnblogs.com/alexander17/p/18551089
import numpy as np
from PIL import Image
def arnold_decode_once(image: Image.Image, a: int = 1, b: int = -2, mode: str = '1'):
image = np.array(image)
N = image.shape[0]
next_image = np.zeros_like(image)
for x in range(N):
for y in range(N):
new_x = ((a * b + 1) * x - b * y) % N
new_y = (-a * x + y) % N
if mode == '1':
next_image[new_x, new_y] = image[x, y]
else:
next_image[new_x, new_y, :] = image[x, y, :]
return Image.fromarray(next_image)
if __name__ == '__main__':
img = Image.open('1.png').convert('1')
result_img = arnold_decode_once(img, a=1, b=-2, mode='1')
result_img.save('output.png')
我们将图反色(随波逐流),再逆时针旋转90°

最后与flag_is_not_here.jpg双图xor
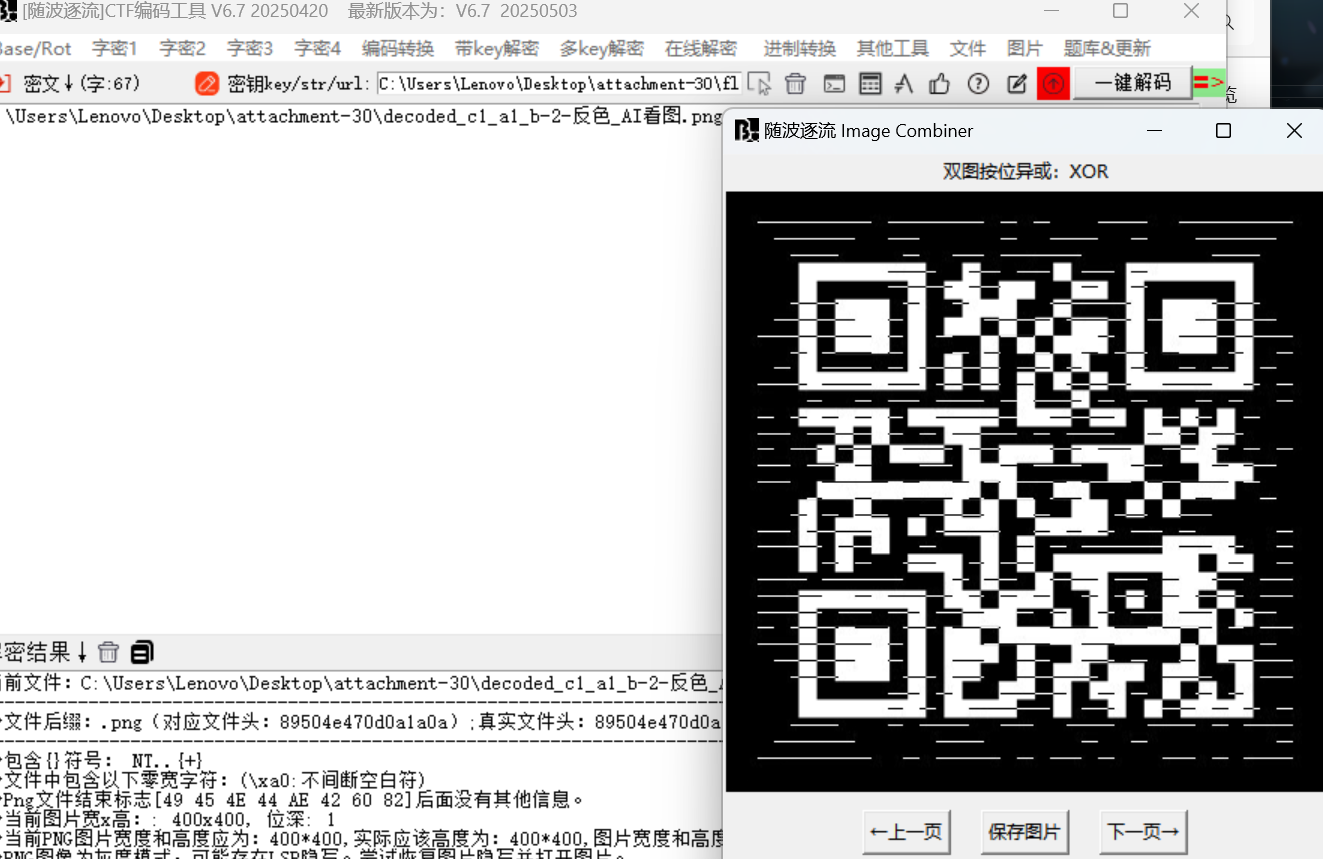
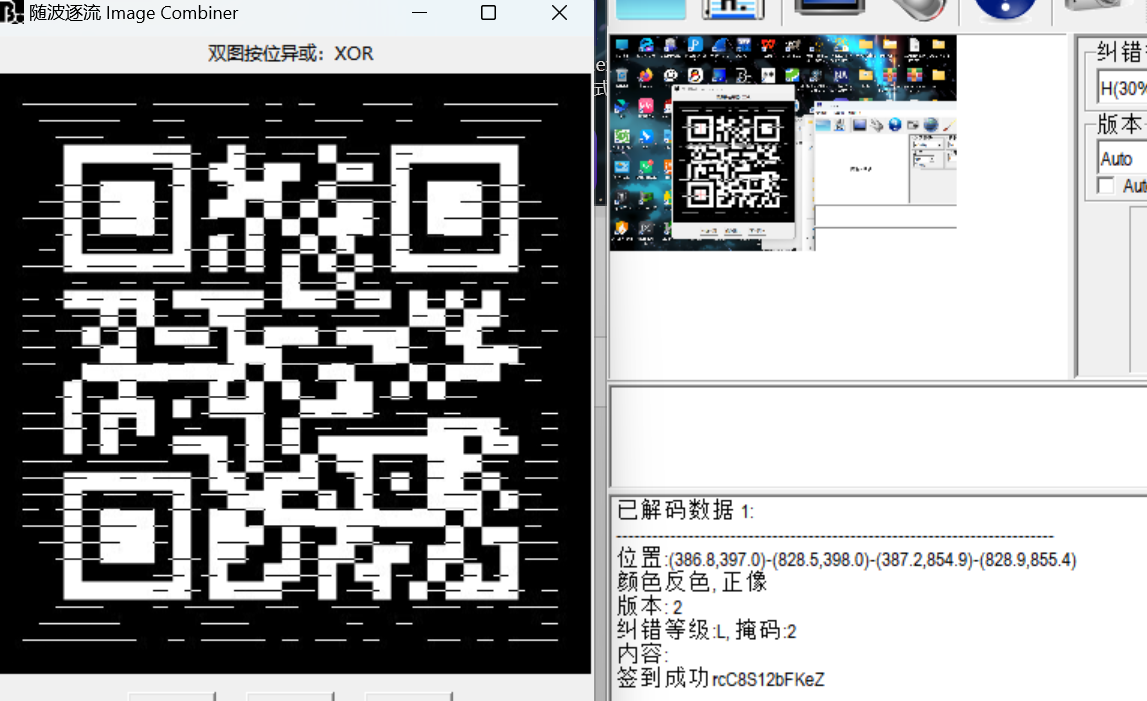
ISCC{rcC8S12bFKeZ}
返校之路
Winzip打开part1
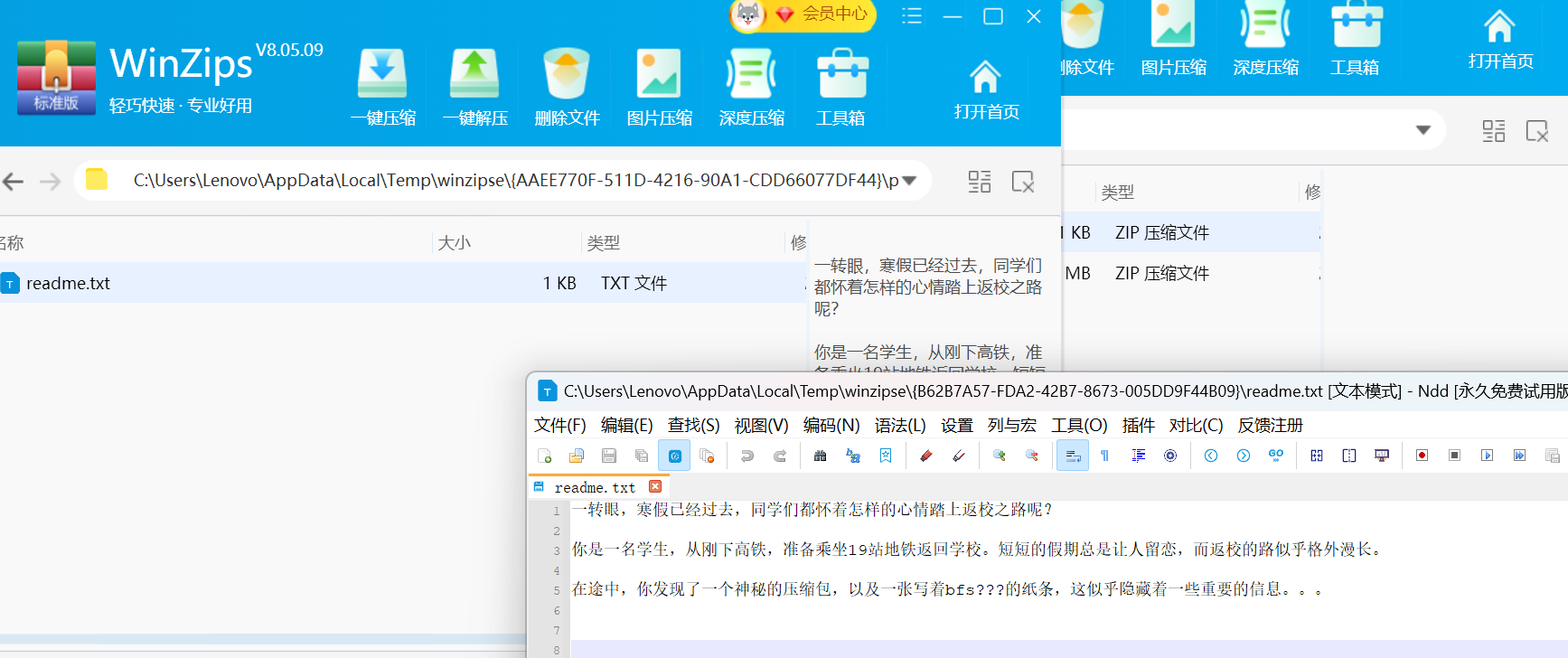
一转眼,寒假已经过去,同学们都怀着怎样的心情踏上返校之路呢?
你是一名学生,从刚下高铁,准备乘坐19站地铁返回学校。短短的假期总是让人留恋,而返校的路似乎格外漫长。
在途中,你发现了一个神秘的压缩包,以及一张写着bfs???的纸条,这似乎隐藏着一些重要的信息。。。
Part2的部分加密了,根据txt内容我们进行掩码爆破
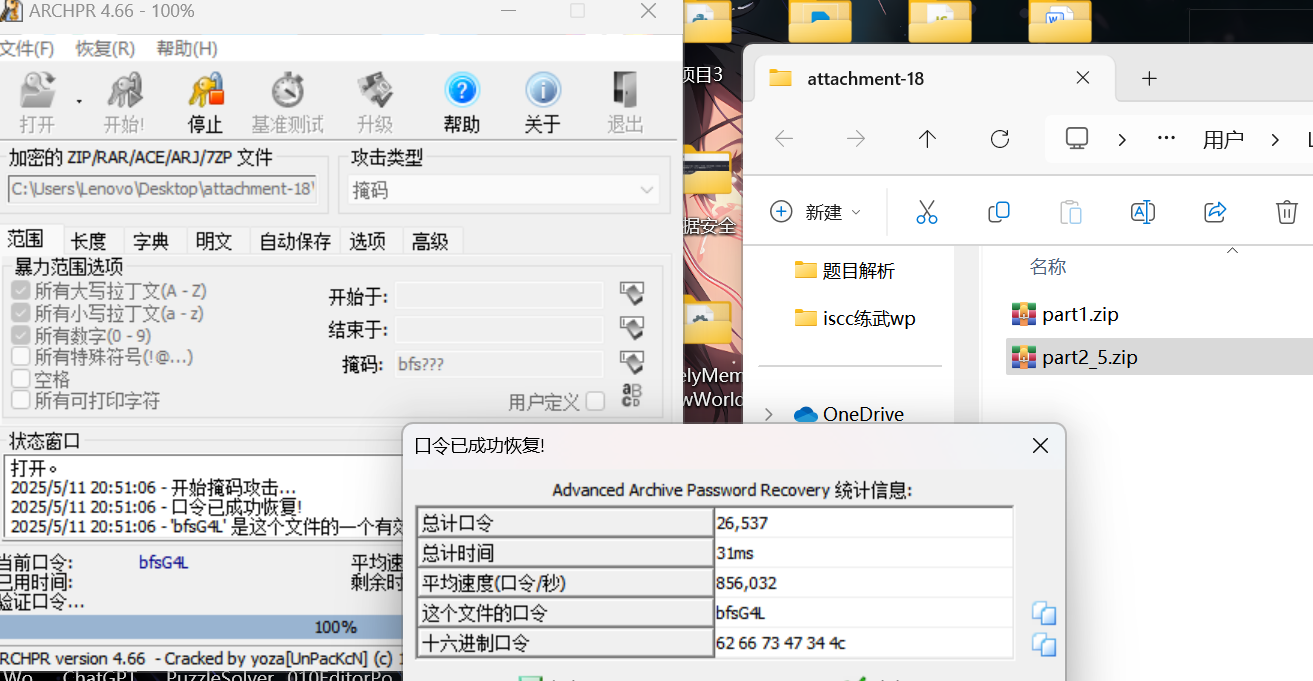
解压压缩包
zsteg扫picture2.png得到
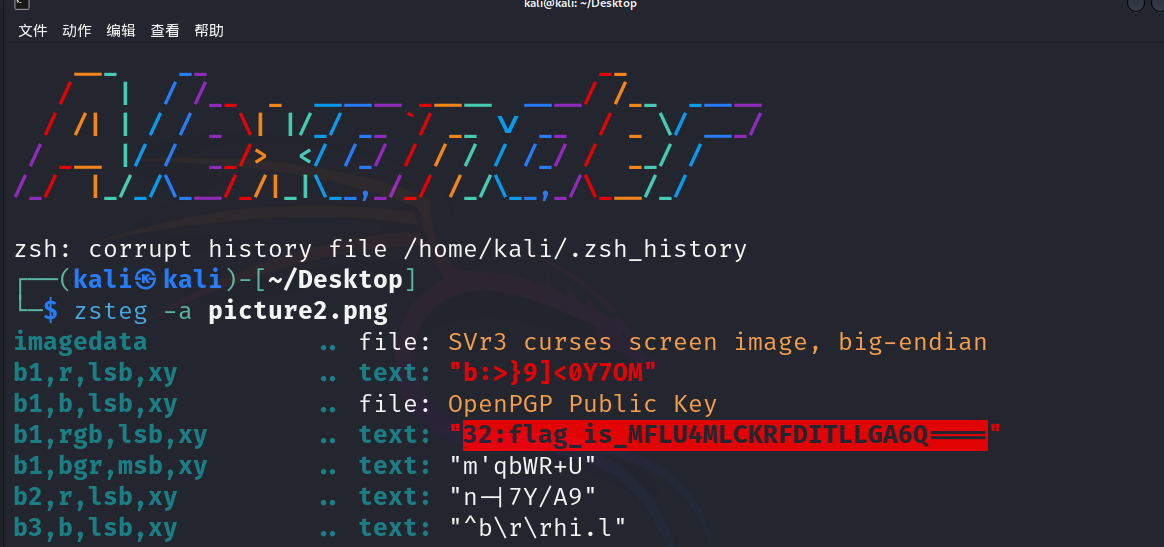
32:flag_is_MFLU4MLCKRFDITLLGA6Q====
base32->base64解密

icum2x2M
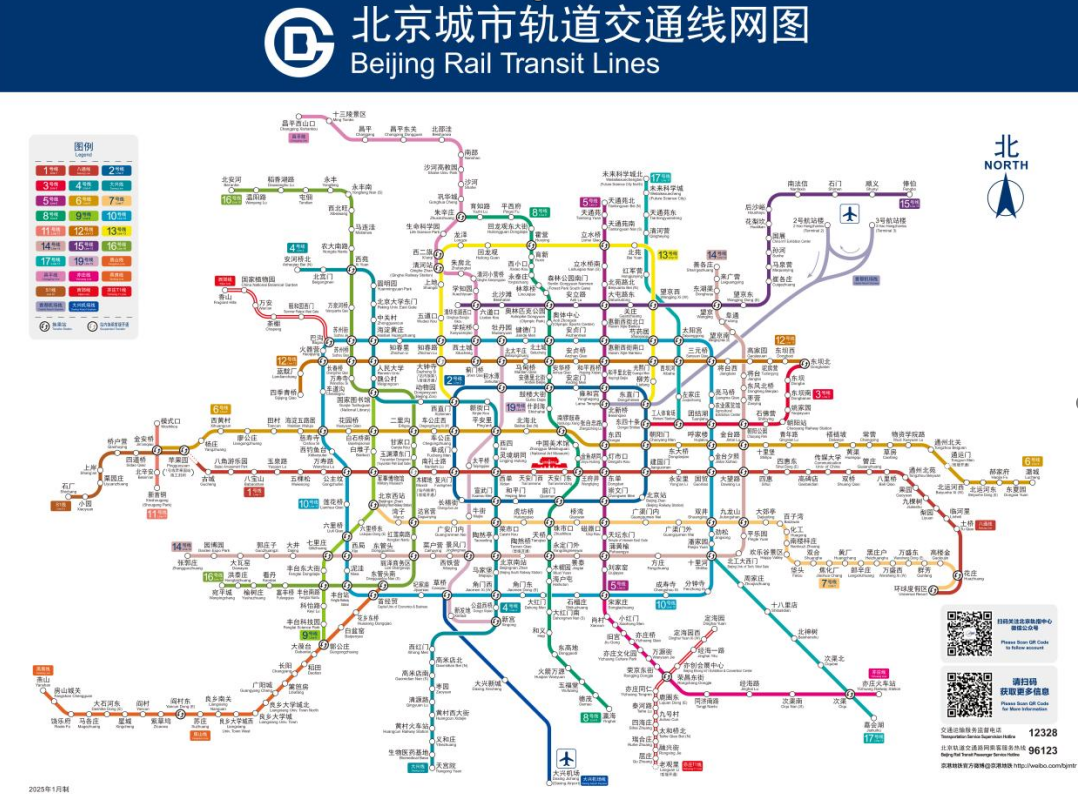
第二部分分析路线图,我们需要从地铁朝阳站到地铁魏公村站,3号线转10号线再转4号
所以是3104,拼接上一部分
ISCC{icum2x2M3104}
取证分析
下载并解压hint的镜像,Lovelymem打开内存镜像
Vol2文件扫描,并提出一个hahaha.zip
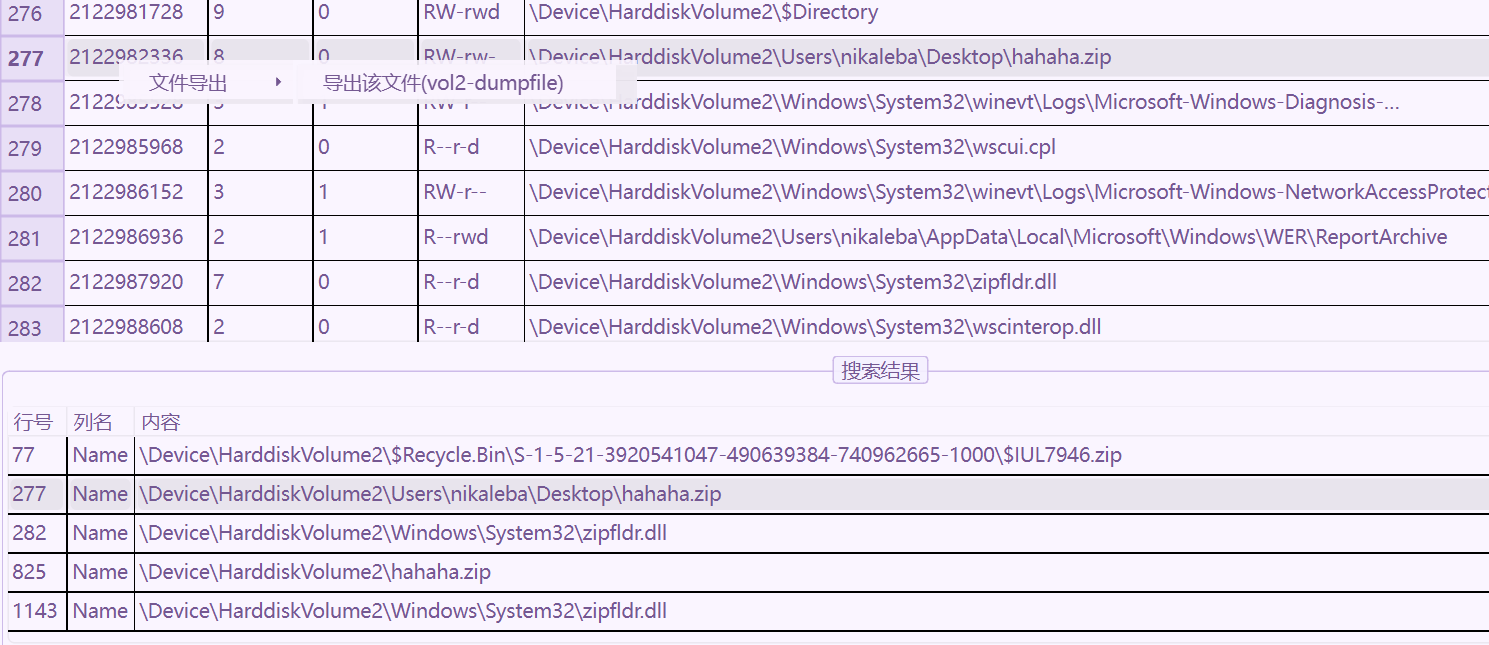
文件加密了,但是没想到上一题的掩码可以爆出密码(非预期),预期应该是明文攻击
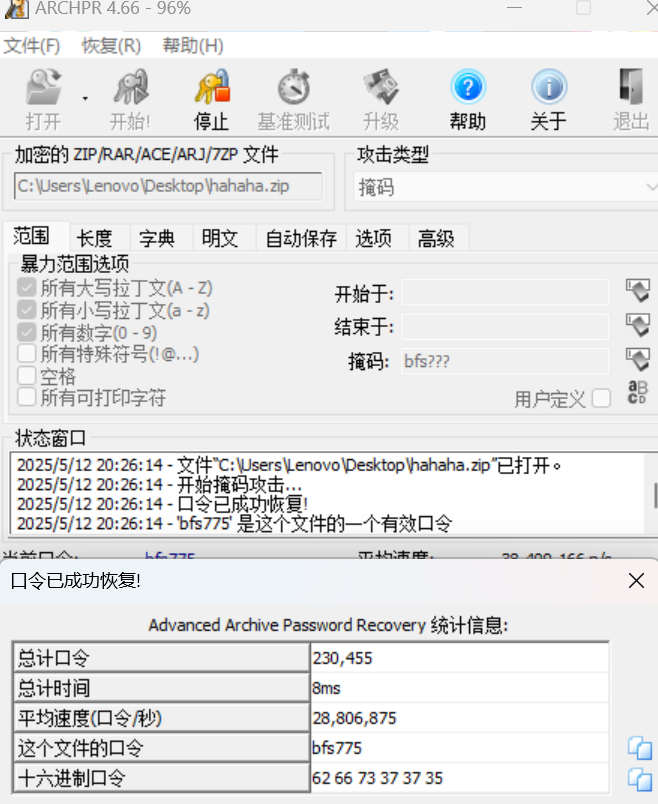
解密Hint.txt

凯撒移位12位
flag{ vigenere cipher }
说明flag是维吉尼亚加密的
再看杨辉三角
我们根据给定的坐标计算杨辉三角中的值,然后对 26 取模,再映射成字母得到密钥
from math import comb
coordinates = [(2,10), (4,8), (2,4), (3,4), (11,13), (2,11), (1,1), (10,26), (5,6), (5,9)]
values = [comb(row-1, col-1) for col, row in coordinates]
mod_values = [v % 26 for v in values]
key = ''.join([chr(65 + (m-1)) for m in mod_values])
print(key)
#IICCNJAYER
我们将题目附件给word解压,在[Content_Types].xml中找到了密文
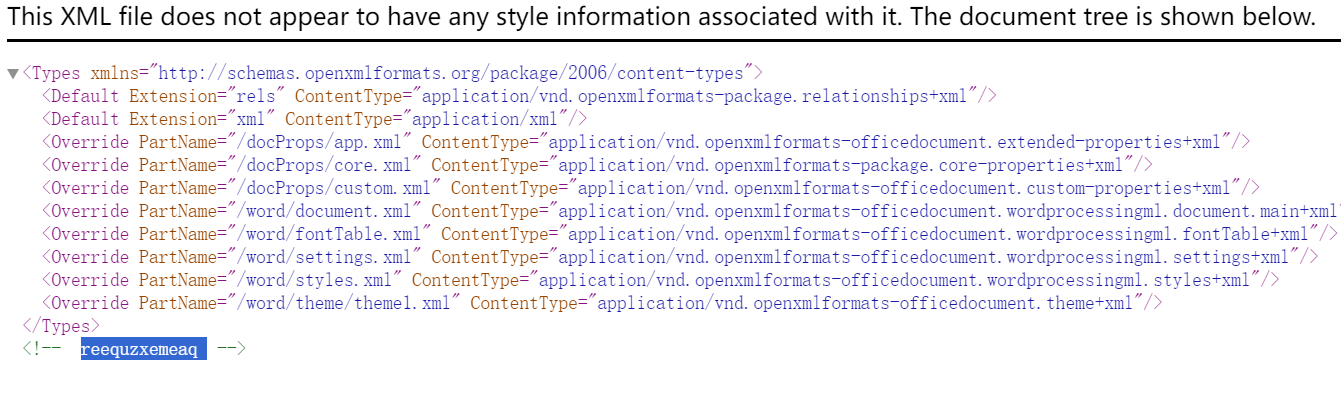
最后维吉尼亚解密
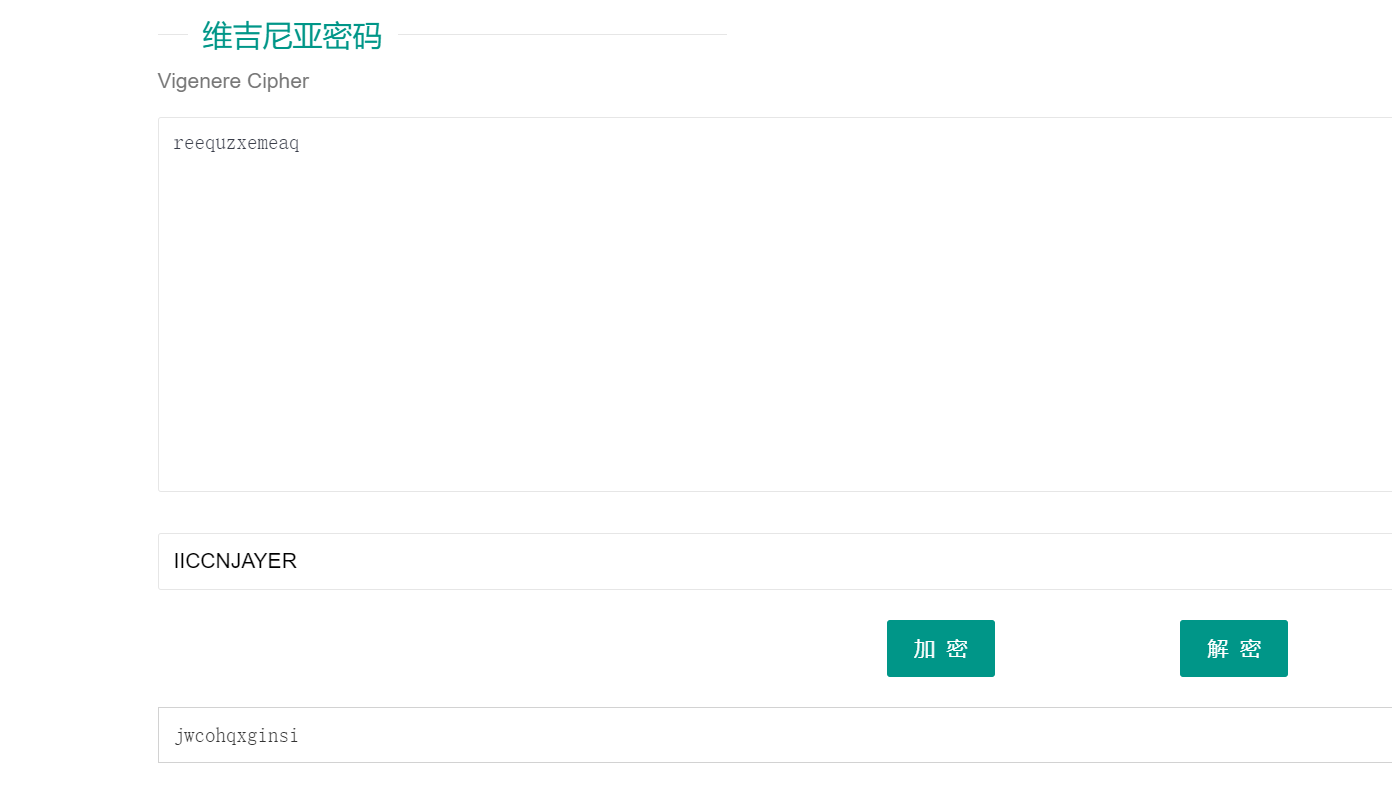
ISCC{jwcohqxginsi}
总决赛
神经网络迷踪
非预期:解压,文件名为flag(我奶奶来了都会写),主办方你是牛的。真的做到了题目的前两个字
预期解
下载得到模型文件
挂载模型(secretkey解出来的2025ISCC2025key!毛用没有!!!!)
我们把secret那一层的元素内容转utf-8
出现hint:放大/缩小255
我们到output.bias
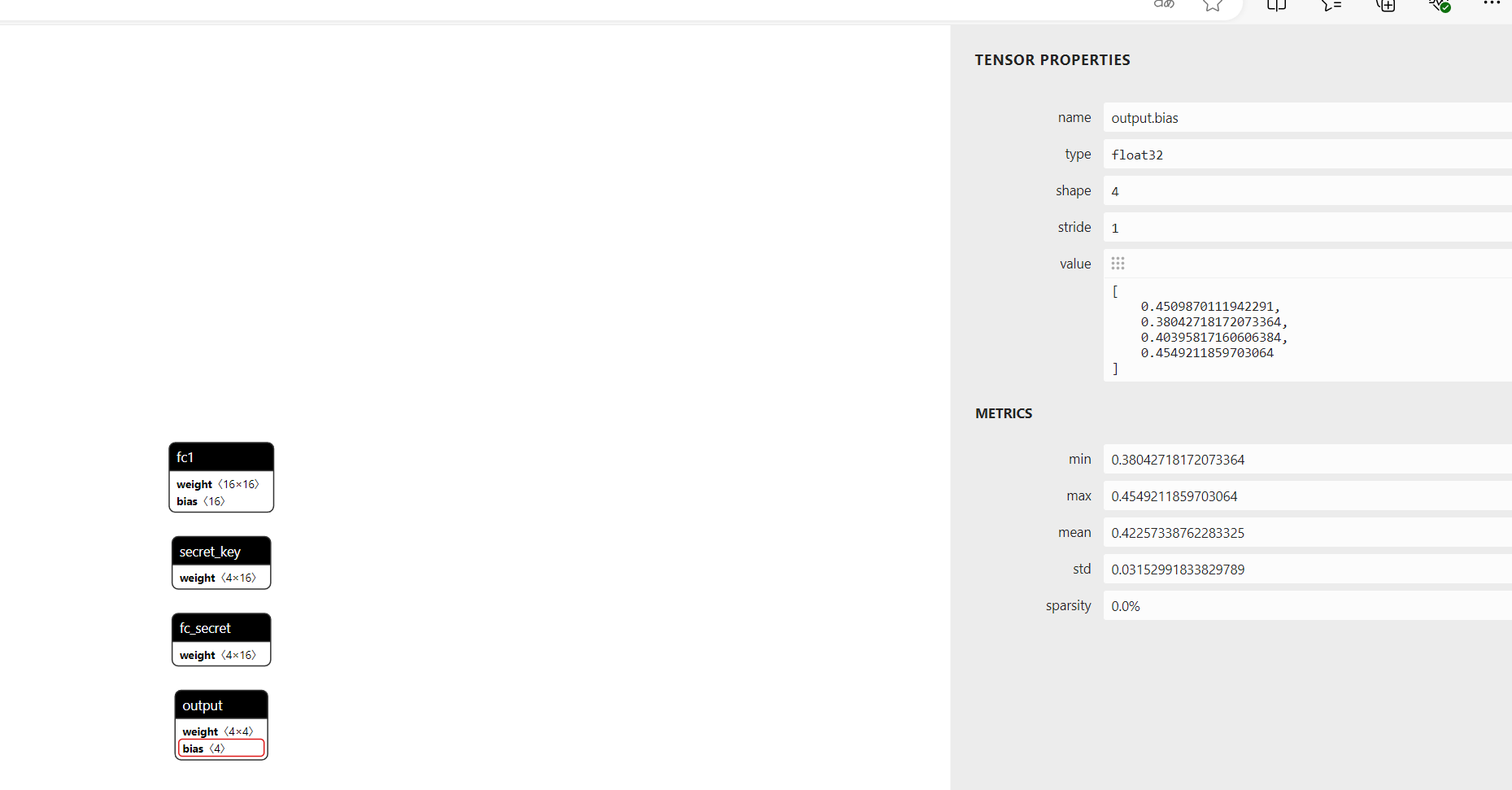
每个值乘255转ascii
values = [
0.4509870111942291,
0.38042718172073364,
0.40395817160606384,
0.4549211859703064
]
# 转换为整数ASCII码并映射到字符,添加ISCC{}包裹
result = 'ISCC{' + ''.join(chr(int(value * 255)) for value in values) + '}'
print(f"转换结果: {result}")
ISCC{sagt}
八卦
下载附件
是个动图,我们后缀改成gif

发现有内容
010发现末尾有个7z
我们手提出来
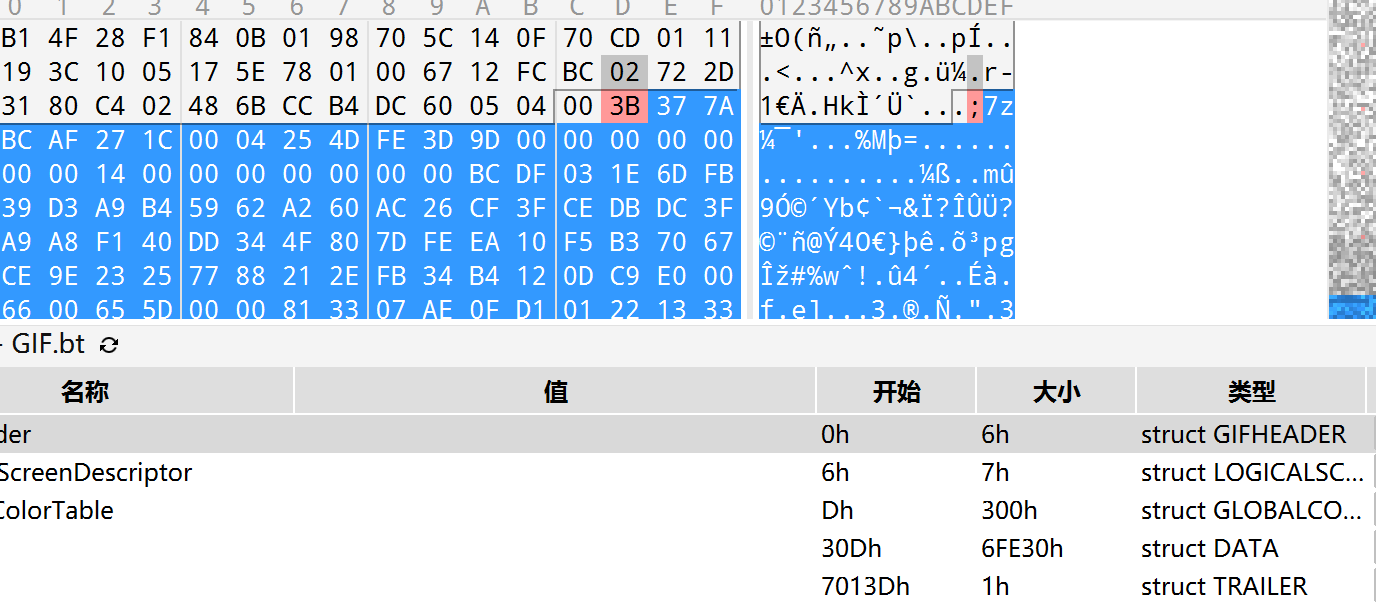
接着puzzlersolver分离动图
Base64解码发现
乾为天 山水蒙 水雷屯 水天需
对分离的图片进行随波逐流
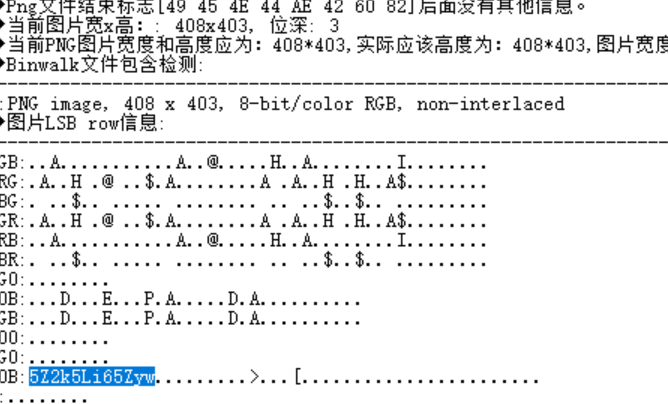
在00B通道发现数据
Base64解密 坤为地
根据给的hint
我们puzzlersolver获取动图间隔帧
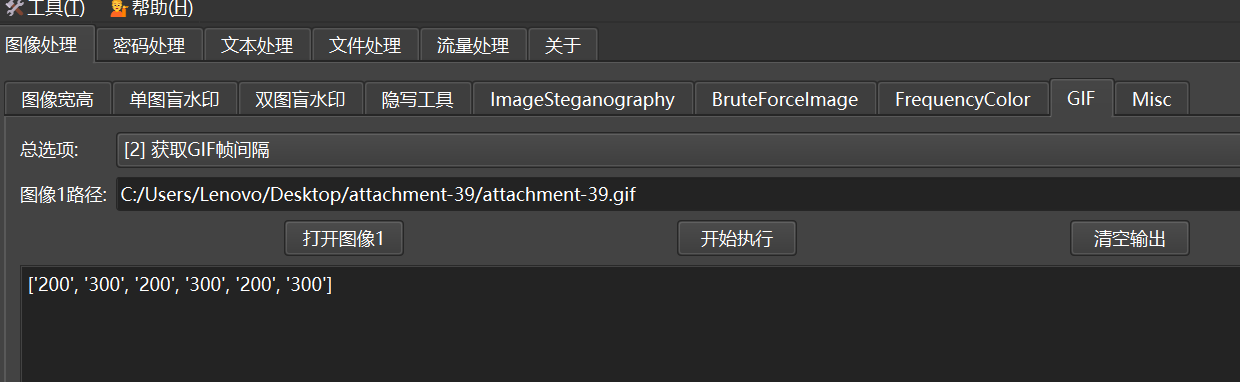
意指向23,指的是64卦中的23卦
在线网站查询
https://lzltool.cn/tool/infozhouyi64
存在内容即在分离的5张图片中,存在内容即为1,不存在即为0,1235帧存在base64,46帧没有,即111010
111010转十进制为58,指的为58卦
题目中的7卦已经形成,我们在上述在线网站中找到所对应的上下卦



我们按照从小到大拼接上下卦
得到压缩包密码
乾乾坤坤坎震艮坎坎乾艮坤兑兑
(比赛结束看到烛影佬用卦写了个字典把密码硬爆破出来了,好强)
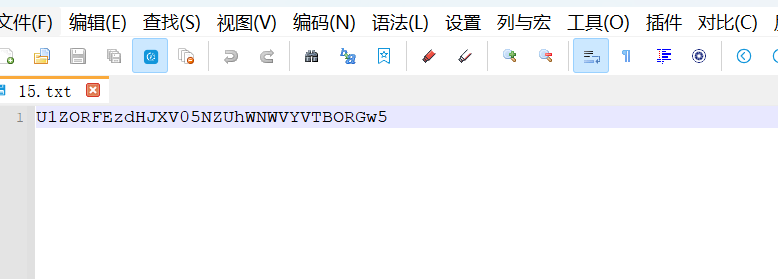
随波逐流梭哈(双base64)
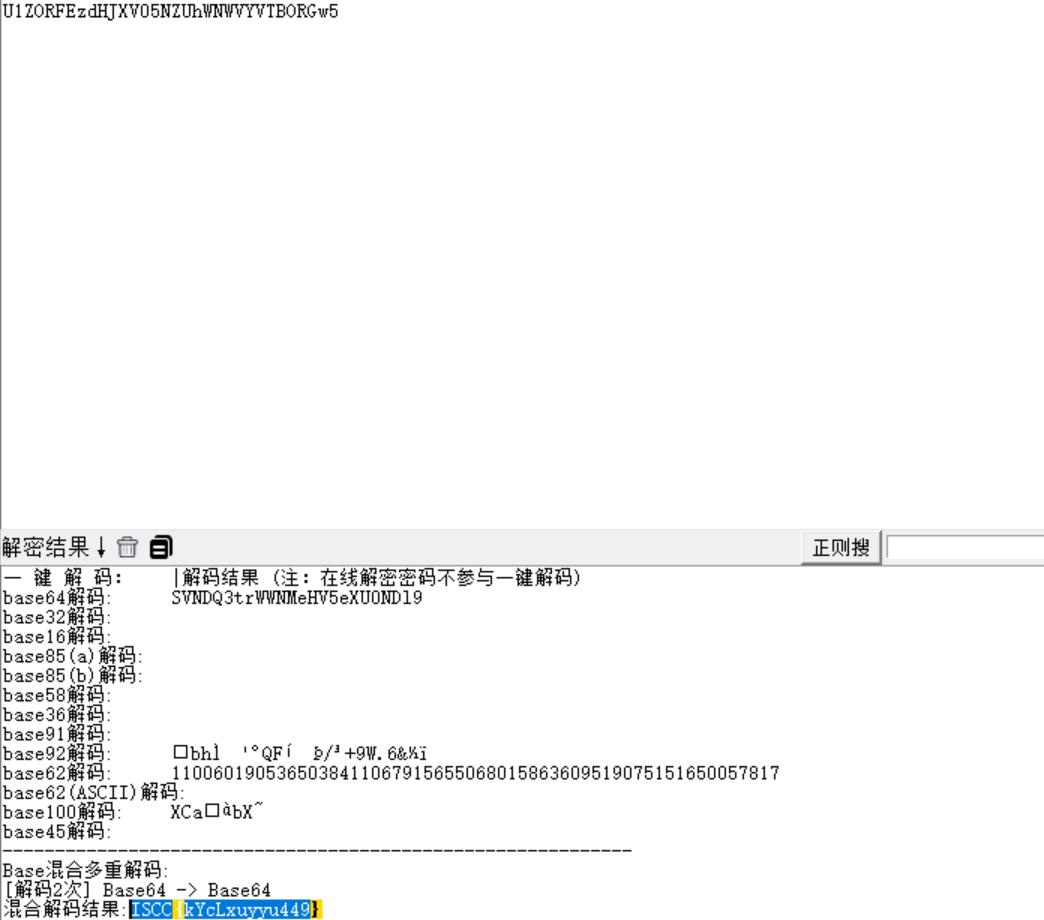
ISCC{kYcLxuyyu449}
ISCC2025破阵夺旗赛三阶段Misc详解 By Alexander的更多相关文章
- elasticsearch系列三:索引详解(分词器、文档管理、路由详解(集群))
一.分词器 1. 认识分词器 1.1 Analyzer 分析器 在ES中一个Analyzer 由下面三种组件组合而成: character filter :字符过滤器,对文本进行字符过滤处理,如 ...
- [转]hibernate三种状态详解
本文来自 http://blog.sina.com.cn/u/2924525911 hibernate 三种状态详解 (2013-04-15 21:24:23) 转载▼ 分类: hibernate ...
- 多表连接的三种方式详解 hash join、merge join、 nested loop
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式.多表之间的连接有三种方式:Nested Loops,Hash Join 和 Sort Merge Join.具体适用哪 ...
- Hexo系列(三) 常用命令详解
Hexo 框架可以帮助我们快速创建一个属于自己的博客网站,熟悉 Hexo 框架提供的命令有利于我们管理博客 1.hexo init hexo init 命令用于初始化本地文件夹为网站的根目录 $ he ...
- 【C/C++开发】C++11 并发指南三(std::mutex 详解)
本系列文章主要介绍 C++11 并发编程,计划分为 9 章介绍 C++11 的并发和多线程编程,分别如下: C++11 并发指南一(C++11 多线程初探)(本章计划 1-2 篇,已完成 1 篇) C ...
- 学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳
学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳 JERRY_Z. ~ 2020 / 10 / 25 转载请注明出处!️ 目录 学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳 ...
- Spring第三天,详解Bean的生命周期,学会后让面试官无话可说!
点击下方链接回顾往期 不要再说不会Spring了!Spring第一天,学会进大厂! Spring第二天,你必须知道容器注册组件的几种方式!学废它吊打面试官! 今天讲解Spring中Bean的生命周期. ...
- 分布式事务 Seata Saga 模式首秀以及三种模式详解 | Meetup#3 回顾
https://mp.weixin.qq.com/s/67NvEVljnU-0-6rb7MWpGw 分布式事务 Seata Saga 模式首秀以及三种模式详解 | Meetup#3 回顾 原创 蚂蚁金 ...
- JVM——三个ClassLoader详解
类装载工作由ClassLoader及其子类负责,ClassLoader是一个重要的Java执行时系统组件,它负责在运行时查找和装入Class字节码文件.JVM在运行时会产生三个ClassLoader: ...
- [置顶] 深入浅出Spring(三) AOP详解
上次的博文深入浅出Spring(二) IoC详解中,我为大家简单介绍了一下Spring框架核心内容中的IoC,接下来我们继续讲解另一个核心AOP(Aspect Oriented Programming ...
随机推荐
- Linux - VMware workstation安装虚拟机
Step1:新建虚拟机 主页/文件 >> 创建新的虚拟机 新建虚拟机向导 典型(推荐)(T) 通过几个简单的步骤创建Workstation虚拟机 自定义(高级)(C) 创建带有SCSI控制 ...
- 「二」移动光标、vim进入与退出、文本编辑之删除、插入、添加、编辑、光标移动、撤销
移动光标 h:向左移动 j:向下移动 k:向上移动 l:向右移动 vim进入与退出 按鍵, 确保处于正常模式 輸入:q! <回车>(丢弃所做的任何改动) 文本编辑之删除 在正常模式下修改命 ...
- php查询结果汉字乱码解决方法
问题描述:使用php查询数据显示,显示的结果中所有汉字乱码 问题及解决:这种情况是编码造成的,检查数据库及页面编码是否一致,也可在页面增加: header('Content-Type:text/htm ...
- css 保留后端 textarea 中的换行与空格字符
原文链接:https://blog.jijian.link/2020-10-22/css-pre/ 如果后台使用 textarea 输入内容,在前段显示需要保留换行符与空白字符,该如何做? 常规方法 ...
- Go Module使用 六大场景讲解示例
前言 通过学习Go是怎么解决包依赖管理问题的?.go module基本使用,我们掌握了 Go Module 构建模式的基本概念和工作原理,也初步学会了如何通过 go mod 命令,将一个 Go 项目转 ...
- go grpc的入门使用
简介 什么是grpc grpc是一个由google推出的.高性能.开源.通用的rpc框架.它是基于HTTP2协议标准设计开发,默认采用Protocol Buffers数据序列化协议,支持多种开发语言. ...
- webpack3使用additionalData和prependData都不管用
10.css相关配置 utils.js sass: generateLoaders('sass', { indentedSyntax: true, implementation: require('n ...
- 入门Dify平台:工作流节点分析
要让智能体在实际应用中表现出色,掌握工作流的使用至关重要.今天,我们将深入探讨Dify平台中的各个节点的功能,了解它们的使用方法以及常见的应用场景.通过对这些节点的全面了解,将能够高效地设计和优化智能 ...
- 【虚拟机】VirtualBox设置共享文件夹
VirtualBox设置共享文件夹 1.选中你要设置的虚拟机,点设置 2.共享文件夹,点右边的加号,设置一个共享文件夹路径,选择其他, 3.选一个你知道的位置,比如我的在E盘的共享文件夹下面 4.选好 ...
- Mybatis的原始的执行方式
一.通过SqlSessionFactory创建sqlsession,再由Sqlsession获取session对象,然后通过session中的执行器Executor,去执行MapperStatemen ...