TVM: 编译深度学习模型的快速入门教程
支持的TVM硬件后端概述
下图显示了 TVM 目前支持的硬件后端:
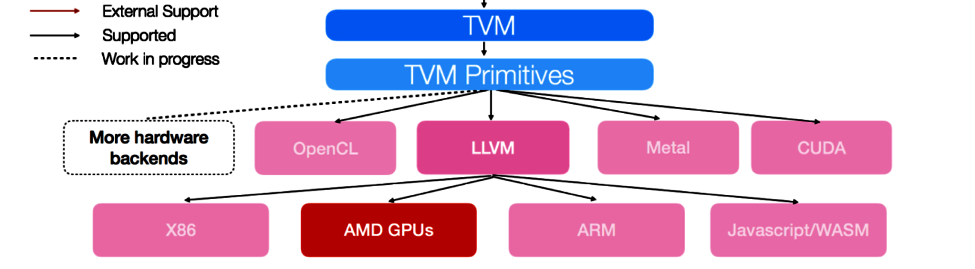
在本教程中,将选择 cuda 和 llvm 作为目标后端。首先,让导入 Relay 和 TVM。
import numpy as np
from tvm import relay
from tvm.relay import testing
import tvm
from tvm import te
from tvm.contrib import graph_executor
import tvm.testing
Define Neural Network in Relay
首先,用 relay 的 python 前端定义神经网络。为了简单起见,将使用 Relay 中预先定义的 resnet-18 网络。参数用 Xavier 初始化器进行初始化。Relay 也支持其他模型格式,如 MXNet、CoreML、ONNX 和 Tensorflow。
在本教程中,假设将在我们的设备上进行推理,并且批量大小被设置为 1。输入图像是大小为 224*224 的 RGB 彩色图像。可以调用 tvm.relay.expr.TupleWrapper.astext() 来显示网络结构。
batch_size = 1
num_class = 1000
image_shape = (3, 224, 224)
data_shape = (batch_size,) + image_shape
out_shape = (batch_size, num_class)
mod, params = relay.testing.resnet.get_workload(
num_layers=18, batch_size=batch_size, image_shape=image_shape
)
# set show_meta_data=True if you want to show meta data
print(mod.astext(show_meta_data=False))
输出结果:
#[version = "0.0.5"]
def @main(%data: Tensor[(1, 3, 224, 224), float32] /* ty=Tensor[(1, 3, 224, 224), float32] */, %bn_data_gamma: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %bn_data_beta: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %bn_data_moving_mean: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %bn_data_moving_var: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %conv0_weight: Tensor[(64, 3, 7, 7), float32] /* ty=Tensor[(64, 3, 7, 7), float32] */, %bn0_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %bn0_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %bn0_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %bn0_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_conv1_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage1_unit1_bn2_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn2_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn2_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn2_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_conv2_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage1_unit1_sc_weight: Tensor[(64, 64, 1, 1), float32] /* ty=Tensor[(64, 64, 1, 1), float32] */, %stage1_unit2_bn1_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn1_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn1_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn1_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_conv1_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage1_unit2_bn2_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn2_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn2_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn2_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_conv2_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage2_unit1_bn1_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_bn1_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_bn1_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_bn1_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_conv1_weight: Tensor[(128, 64, 3, 3), float32] /* ty=Tensor[(128, 64, 3, 3), float32] */, %stage2_unit1_bn2_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_bn2_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_bn2_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_bn2_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_conv2_weight: Tensor[(128, 128, 3, 3), float32] /* ty=Tensor[(128, 128, 3, 3), float32] */, %stage2_unit1_sc_weight: Tensor[(128, 64, 1, 1), float32] /* ty=Tensor[(128, 64, 1, 1), float32] */, %stage2_unit2_bn1_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn1_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn1_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn1_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_conv1_weight: Tensor[(128, 128, 3, 3), float32] /* ty=Tensor[(128, 128, 3, 3), float32] */, %stage2_unit2_bn2_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn2_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn2_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn2_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_conv2_weight: Tensor[(128, 128, 3, 3), float32] /* ty=Tensor[(128, 128, 3, 3), float32] */, %stage3_unit1_bn1_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_bn1_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_bn1_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_bn1_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_conv1_weight: Tensor[(256, 128, 3, 3), float32] /* ty=Tensor[(256, 128, 3, 3), float32] */, %stage3_unit1_bn2_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_bn2_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_bn2_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_bn2_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_conv2_weight: Tensor[(256, 256, 3, 3), float32] /* ty=Tensor[(256, 256, 3, 3), float32] */, %stage3_unit1_sc_weight: Tensor[(256, 128, 1, 1), float32] /* ty=Tensor[(256, 128, 1, 1), float32] */, %stage3_unit2_bn1_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn1_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn1_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn1_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_conv1_weight: Tensor[(256, 256, 3, 3), float32] /* ty=Tensor[(256, 256, 3, 3), float32] */, %stage3_unit2_bn2_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn2_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn2_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn2_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_conv2_weight: Tensor[(256, 256, 3, 3), float32] /* ty=Tensor[(256, 256, 3, 3), float32] */, %stage4_unit1_bn1_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_bn1_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_bn1_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_bn1_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_conv1_weight: Tensor[(512, 256, 3, 3), float32] /* ty=Tensor[(512, 256, 3, 3), float32] */, %stage4_unit1_bn2_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_bn2_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_bn2_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_bn2_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_conv2_weight: Tensor[(512, 512, 3, 3), float32] /* ty=Tensor[(512, 512, 3, 3), float32] */, %stage4_unit1_sc_weight: Tensor[(512, 256, 1, 1), float32] /* ty=Tensor[(512, 256, 1, 1), float32] */, %stage4_unit2_bn1_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn1_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn1_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn1_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_conv1_weight: Tensor[(512, 512, 3, 3), float32] /* ty=Tensor[(512, 512, 3, 3), float32] */, %stage4_unit2_bn2_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn2_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn2_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn2_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_conv2_weight: Tensor[(512, 512, 3, 3), float32] /* ty=Tensor[(512, 512, 3, 3), float32] */, %bn1_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %bn1_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %bn1_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %bn1_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %fc1_weight: Tensor[(1000, 512), float32] /* ty=Tensor[(1000, 512), float32] */, %fc1_bias: Tensor[(1000), float32] /* ty=Tensor[(1000), float32] */) -> Tensor[(1, 1000), float32] {
%0 = nn.batch_norm(%data, %bn_data_gamma, %bn_data_beta, %bn_data_moving_mean, %bn_data_moving_var, epsilon=2e-05f, scale=False) /* ty=(Tensor[(1, 3, 224, 224), float32], Tensor[(3), float32], Tensor[(3), float32]) */;
%1 = %0.0 /* ty=Tensor[(1, 3, 224, 224), float32] */;
%2 = nn.conv2d(%1, %conv0_weight, strides=[2, 2], padding=[3, 3, 3, 3], channels=64, kernel_size=[7, 7]) /* ty=Tensor[(1, 64, 112, 112), float32] */;
%3 = nn.batch_norm(%2, %bn0_gamma, %bn0_beta, %bn0_moving_mean, %bn0_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 112, 112), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%4 = %3.0 /* ty=Tensor[(1, 64, 112, 112), float32] */;
%5 = nn.relu(%4) /* ty=Tensor[(1, 64, 112, 112), float32] */;
%6 = nn.max_pool2d(%5, pool_size=[3, 3], strides=[2, 2], padding=[1, 1, 1, 1]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%7 = nn.batch_norm(%6, %stage1_unit1_bn1_gamma, %stage1_unit1_bn1_beta, %stage1_unit1_bn1_moving_mean, %stage1_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%8 = %7.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%9 = nn.relu(%8) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%10 = nn.conv2d(%9, %stage1_unit1_conv1_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%11 = nn.batch_norm(%10, %stage1_unit1_bn2_gamma, %stage1_unit1_bn2_beta, %stage1_unit1_bn2_moving_mean, %stage1_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%12 = %11.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%13 = nn.relu(%12) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%14 = nn.conv2d(%13, %stage1_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%15 = nn.conv2d(%9, %stage1_unit1_sc_weight, padding=[0, 0, 0, 0], channels=64, kernel_size=[1, 1]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%16 = add(%14, %15) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%17 = nn.batch_norm(%16, %stage1_unit2_bn1_gamma, %stage1_unit2_bn1_beta, %stage1_unit2_bn1_moving_mean, %stage1_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%18 = %17.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%19 = nn.relu(%18) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%20 = nn.conv2d(%19, %stage1_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%21 = nn.batch_norm(%20, %stage1_unit2_bn2_gamma, %stage1_unit2_bn2_beta, %stage1_unit2_bn2_moving_mean, %stage1_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%22 = %21.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%23 = nn.relu(%22) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%24 = nn.conv2d(%23, %stage1_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%25 = add(%24, %16) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%26 = nn.batch_norm(%25, %stage2_unit1_bn1_gamma, %stage2_unit1_bn1_beta, %stage2_unit1_bn1_moving_mean, %stage2_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%27 = %26.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%28 = nn.relu(%27) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%29 = nn.conv2d(%28, %stage2_unit1_conv1_weight, strides=[2, 2], padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%30 = nn.batch_norm(%29, %stage2_unit1_bn2_gamma, %stage2_unit1_bn2_beta, %stage2_unit1_bn2_moving_mean, %stage2_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%31 = %30.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%32 = nn.relu(%31) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%33 = nn.conv2d(%32, %stage2_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%34 = nn.conv2d(%28, %stage2_unit1_sc_weight, strides=[2, 2], padding=[0, 0, 0, 0], channels=128, kernel_size=[1, 1]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%35 = add(%33, %34) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%36 = nn.batch_norm(%35, %stage2_unit2_bn1_gamma, %stage2_unit2_bn1_beta, %stage2_unit2_bn1_moving_mean, %stage2_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%37 = %36.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%38 = nn.relu(%37) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%39 = nn.conv2d(%38, %stage2_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%40 = nn.batch_norm(%39, %stage2_unit2_bn2_gamma, %stage2_unit2_bn2_beta, %stage2_unit2_bn2_moving_mean, %stage2_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%41 = %40.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%42 = nn.relu(%41) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%43 = nn.conv2d(%42, %stage2_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%44 = add(%43, %35) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%45 = nn.batch_norm(%44, %stage3_unit1_bn1_gamma, %stage3_unit1_bn1_beta, %stage3_unit1_bn1_moving_mean, %stage3_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%46 = %45.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%47 = nn.relu(%46) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%48 = nn.conv2d(%47, %stage3_unit1_conv1_weight, strides=[2, 2], padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%49 = nn.batch_norm(%48, %stage3_unit1_bn2_gamma, %stage3_unit1_bn2_beta, %stage3_unit1_bn2_moving_mean, %stage3_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%50 = %49.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%51 = nn.relu(%50) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%52 = nn.conv2d(%51, %stage3_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%53 = nn.conv2d(%47, %stage3_unit1_sc_weight, strides=[2, 2], padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%54 = add(%52, %53) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%55 = nn.batch_norm(%54, %stage3_unit2_bn1_gamma, %stage3_unit2_bn1_beta, %stage3_unit2_bn1_moving_mean, %stage3_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%56 = %55.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%57 = nn.relu(%56) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%58 = nn.conv2d(%57, %stage3_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%59 = nn.batch_norm(%58, %stage3_unit2_bn2_gamma, %stage3_unit2_bn2_beta, %stage3_unit2_bn2_moving_mean, %stage3_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%60 = %59.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%61 = nn.relu(%60) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%62 = nn.conv2d(%61, %stage3_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%63 = add(%62, %54) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%64 = nn.batch_norm(%63, %stage4_unit1_bn1_gamma, %stage4_unit1_bn1_beta, %stage4_unit1_bn1_moving_mean, %stage4_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%65 = %64.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%66 = nn.relu(%65) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%67 = nn.conv2d(%66, %stage4_unit1_conv1_weight, strides=[2, 2], padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%68 = nn.batch_norm(%67, %stage4_unit1_bn2_gamma, %stage4_unit1_bn2_beta, %stage4_unit1_bn2_moving_mean, %stage4_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%69 = %68.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%70 = nn.relu(%69) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%71 = nn.conv2d(%70, %stage4_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%72 = nn.conv2d(%66, %stage4_unit1_sc_weight, strides=[2, 2], padding=[0, 0, 0, 0], channels=512, kernel_size=[1, 1]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%73 = add(%71, %72) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%74 = nn.batch_norm(%73, %stage4_unit2_bn1_gamma, %stage4_unit2_bn1_beta, %stage4_unit2_bn1_moving_mean, %stage4_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%75 = %74.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%76 = nn.relu(%75) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%77 = nn.conv2d(%76, %stage4_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%78 = nn.batch_norm(%77, %stage4_unit2_bn2_gamma, %stage4_unit2_bn2_beta, %stage4_unit2_bn2_moving_mean, %stage4_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%79 = %78.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%80 = nn.relu(%79) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%81 = nn.conv2d(%80, %stage4_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%82 = add(%81, %73) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%83 = nn.batch_norm(%82, %bn1_gamma, %bn1_beta, %bn1_moving_mean, %bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%84 = %83.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%85 = nn.relu(%84) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%86 = nn.global_avg_pool2d(%85) /* ty=Tensor[(1, 512, 1, 1), float32] */;
%87 = nn.batch_flatten(%86) /* ty=Tensor[(1, 512), float32] */;
%88 = nn.dense(%87, %fc1_weight, units=1000) /* ty=Tensor[(1, 1000), float32] */;
%89 = nn.bias_add(%88, %fc1_bias, axis=-1) /* ty=Tensor[(1, 1000), float32] */;
nn.softmax(%89) /* ty=Tensor[(1, 1000), float32] */
}
Compilation
下一步是使用 Relay/TVM 管道对模型进行编译。用户可以指定编译的优化级别(opt_level)。目前这个值可以是 0 到 3。优化 passes ** 包括 算子融合(operator fusion、预计算(pre-computation)、布局变换(layout transformation)**等。
relay.build() 返回三个部分:json 格式的执行图,TVM 模块库中专门为这个图在目标硬件上编译的函数,以及模型的参数 blobs。在编译过程中,Relay 做了图层面的优化,而 TVM 做了张量层面的优化,从而产生了优化的运行模块为模型服务。
首先为 Nvidia GPU 进行编译。在幕后, relay.build() 首先做了一些图层面的优化,例如修剪(pruning)、融合(fusing)等,然后将算子(即优化后的图的节点)注册到 TVM 实现中,生成 tvm.module。为了生成模块库,TVM 将首先把高层 IR 转移到指定目标后端的低层内在 IR 中,在这个例子中是 CUDA。然后机器代码将被生成为模块库。
opt_level = 3
target = tvm.target.cuda()
with tvm.transform.PassContext(opt_level=opt_level):
lib = relay.build(mod, target, params=params)
注意:
在执行relay.build时,报错:WARNING:root:Failed to download tophub package for cuda: <urlopen error [Errno 99] Cannot assign requested address>,
解决方法:拷贝下载tophub并拷贝至/root/.tvm/tophub下
git clone git@github.com:tlc-pack/tophub.git
mv ./tophub/* /root/.tvm/tophub
Run the generate library
可以创建图执行器并在 Nvidia GPU 上运行该模块。
# create random input
dev = tvm.cuda()
data = np.random.uniform(-1, 1, size=data_shape).astype("float32")
# create module
module = graph_executor.GraphModule(lib["default"](dev))
# set input and parameters
module.set_input("data", data)
# run
module.run()
# get output
out = module.get_output(0, tvm.nd.empty(out_shape)).numpy()
# Print first 10 elements of output
print(out.flatten()[0:10])
输出结果:
[0.00089283 0.00103331 0.0009094 0.00102275 0.00108751 0.00106737
0.00106262 0.00095838 0.00110792 0.00113151]
Save and Load Compiled Module
也可以将 graph、lib 和参数保存到文件中,并在部署环境中加载它们。
# save the graph, lib and params into separate files
from tvm.contrib import utils
temp = utils.tempdir()
path_lib = temp.relpath("deploy_lib.tar")
lib.export_library(path_lib)
print(temp.listdir())
输出结果:
['deploy_lib.tar']
# load the module back.
loaded_lib = tvm.runtime.load_module(path_lib)
input_data = tvm.nd.array(data)
module = graph_executor.GraphModule(loaded_lib["default"](dev))
module.run(data=input_data)
out_deploy = module.get_output(0).numpy()
# Print first 10 elements of output
print(out_deploy.flatten()[0:10])
# check whether the output from deployed module is consistent with original one
tvm.testing.assert_allclose(out_deploy, out, atol=1e-5)
输出结果:
[0.00089283 0.00103331 0.0009094 0.00102275 0.00108751 0.00106737
0.00106262 0.00095838 0.00110792 0.00113151]
TVM: 编译深度学习模型的快速入门教程的更多相关文章
- TVM将深度学习模型编译为WebGL
使用TVM将深度学习模型编译为WebGL TVM带有全新的OpenGL / WebGL后端! OpenGL / WebGL后端 TVM已经瞄准了涵盖各种平台的大量后端:CPU,GPU,移动设备等.这次 ...
- 【PyTorch深度学习60分钟快速入门 】Part1:PyTorch是什么?
0x00 PyTorch是什么? PyTorch是一个基于Python的科学计算工具包,它主要面向两种场景: 用于替代NumPy,可以使用GPU的计算力 一种深度学习研究平台,可以提供最大的灵活性 ...
- 【PyTorch深度学习60分钟快速入门 】Part3:神经网络
神经网络可以通过使用torch.nn包来构建. 既然你已经了解了autograd,而nn依赖于autograd来定义模型并对其求微分.一个nn.Module包含多个网络层,以及一个返回输出的方法f ...
- 【PyTorch深度学习60分钟快速入门 】Part5:数据并行化
在本节中,我们将学习如何利用DataParallel使用多个GPU. 在PyTorch中使用多个GPU非常容易,你可以使用下面代码将模型放在GPU上: model.gpu() 然后,你可以将所有张 ...
- 【PyTorch深度学习60分钟快速入门 】Part4:训练一个分类器
太棒啦!到目前为止,你已经了解了如何定义神经网络.计算损失,以及更新网络权重.不过,现在你可能会思考以下几个方面: 0x01 数据集 通常,当你需要处理图像.文本.音频或视频数据时,你可以使用标准 ...
- 【PyTorch深度学习60分钟快速入门 】Part2:Autograd自动化微分
在PyTorch中,集中于所有神经网络的是autograd包.首先,我们简要地看一下此工具包,然后我们将训练第一个神经网络. autograd包为张量的所有操作提供了自动微分.它是一个运行式定义的 ...
- 【PyTorch深度学习60分钟快速入门 】Part0:系列介绍
说明:本系列教程翻译自PyTorch官方教程<Deep Learning with PyTorch: A 60 Minute Blitz>,基于PyTorch 0.3.0.post4 ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
随机推荐
- 【攻防世界】wife_wife
wife_wife 题目来源 攻防世界 NO.GFSJ1192 题解 本题没有源码,也没有提示,非常困难,在网上搜索此题可以看到源码.由于使用了assign(),因此存在Javascript原型链污染 ...
- 跨平台Windows和Linux(银河麒麟)操作系统OCR识别应用
1 运行效果 代码下载链接: https://pan.baidu.com/s/1NUfLTjk6kzXJKsaH7yo4qA?pwd=rk5c 提取码: rk5c. 在银河麒麟桌面操作系统V10(SP ...
- 前端UI框架Ant Design Pro
https://012x.ant.design/ 一直忙于工作,也没时间总结.现在有点零散时间把之前做的笔记整理一下. 目前项目使用的技术栈是,前端UI框架Ant Design Pro,数据交互使用r ...
- Joker 智能开发平台再放大招,新作将彻底重塑开发模式
-- 突破传统枷锁,引领开发模式全面革新 自前端可视化智能平台重磅发布后,其在行业内的影响力便如涟漪般迅速扩散.凭借着创新的设计理念和过硬的性能表现,这个平台为无数开发者和企业提供了高效且便捷的开发解 ...
- delphi 让执行程序不在任务栏显示
Application.MainFormOnTaskbar := False; procedure TForm1.FormShow(Sender: TObject); begin ShowWindow ...
- 基于DotNetty实现自动发布 - 背景篇
故事背景 小公司,单体项目,接口和页面都在一起,生产和测试环境都是 Windows 服务器和 IIS, 本地编译完成,把相关的页面和程序集拷贝到服务器上,尤其是涉及到多个页面,一个个页面找到对应的位置 ...
- 本地部署overleaf服务帮助latex论文编写
是的,overleaf是一个很好的服务,提供了立刻上手就可以编写的latex文章的服务.但是,overleaf会面对latex超时,所以需要付钱的情况,这常出现在编写期刊的论文的情况. 因为时效性,所 ...
- Effective Java理解笔记系列-第1条-何时考虑用静态工厂方法替代构造器?
为什么写这系列博客? 在阅读<Effective Java>这本书时,我发现有许多地方需要仔细认真地慢慢阅读并且在必要时查阅相关资料才能彻底搞懂,相信有些读者在阅读此书时也有类似感受:同时 ...
- 【Git】基本操作
一.Git 基础 1.Git 介绍 Git 是目前世界上最先进的分布式版本控制系统. 版本控制系统: 设计师在设计的时候做了很多版本 经过了数天去问设计师每个版本都改了些啥,设计师此时可能就说不上来了 ...
- leetcode每日一题:最小化字符串长度
题目 2716. 最小化字符串长度 给你一个下标从 0 开始的字符串 s ,重复执行下述操作 任意 次: 在字符串中选出一个下标 i ,并使 c 为字符串下标 i 处的字符.并在 i 左侧(如果有)和 ...