TVM: 编译深度学习模型的快速入门教程
支持的TVM硬件后端概述
下图显示了 TVM 目前支持的硬件后端:
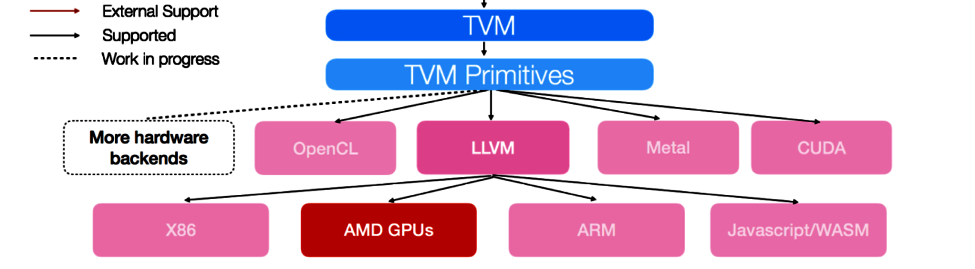
在本教程中,将选择 cuda 和 llvm 作为目标后端。首先,让导入 Relay 和 TVM。
import numpy as np
from tvm import relay
from tvm.relay import testing
import tvm
from tvm import te
from tvm.contrib import graph_executor
import tvm.testing
Define Neural Network in Relay
首先,用 relay 的 python 前端定义神经网络。为了简单起见,将使用 Relay 中预先定义的 resnet-18 网络。参数用 Xavier 初始化器进行初始化。Relay 也支持其他模型格式,如 MXNet、CoreML、ONNX 和 Tensorflow。
在本教程中,假设将在我们的设备上进行推理,并且批量大小被设置为 1。输入图像是大小为 224*224 的 RGB 彩色图像。可以调用 tvm.relay.expr.TupleWrapper.astext() 来显示网络结构。
batch_size = 1
num_class = 1000
image_shape = (3, 224, 224)
data_shape = (batch_size,) + image_shape
out_shape = (batch_size, num_class)
mod, params = relay.testing.resnet.get_workload(
num_layers=18, batch_size=batch_size, image_shape=image_shape
)
# set show_meta_data=True if you want to show meta data
print(mod.astext(show_meta_data=False))
输出结果:
#[version = "0.0.5"]
def @main(%data: Tensor[(1, 3, 224, 224), float32] /* ty=Tensor[(1, 3, 224, 224), float32] */, %bn_data_gamma: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %bn_data_beta: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %bn_data_moving_mean: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %bn_data_moving_var: Tensor[(3), float32] /* ty=Tensor[(3), float32] */, %conv0_weight: Tensor[(64, 3, 7, 7), float32] /* ty=Tensor[(64, 3, 7, 7), float32] */, %bn0_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %bn0_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %bn0_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %bn0_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn1_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_conv1_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage1_unit1_bn2_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn2_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn2_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_bn2_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit1_conv2_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage1_unit1_sc_weight: Tensor[(64, 64, 1, 1), float32] /* ty=Tensor[(64, 64, 1, 1), float32] */, %stage1_unit2_bn1_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn1_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn1_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn1_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_conv1_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage1_unit2_bn2_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn2_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn2_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_bn2_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage1_unit2_conv2_weight: Tensor[(64, 64, 3, 3), float32] /* ty=Tensor[(64, 64, 3, 3), float32] */, %stage2_unit1_bn1_gamma: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_bn1_beta: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_bn1_moving_mean: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_bn1_moving_var: Tensor[(64), float32] /* ty=Tensor[(64), float32] */, %stage2_unit1_conv1_weight: Tensor[(128, 64, 3, 3), float32] /* ty=Tensor[(128, 64, 3, 3), float32] */, %stage2_unit1_bn2_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_bn2_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_bn2_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_bn2_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit1_conv2_weight: Tensor[(128, 128, 3, 3), float32] /* ty=Tensor[(128, 128, 3, 3), float32] */, %stage2_unit1_sc_weight: Tensor[(128, 64, 1, 1), float32] /* ty=Tensor[(128, 64, 1, 1), float32] */, %stage2_unit2_bn1_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn1_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn1_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn1_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_conv1_weight: Tensor[(128, 128, 3, 3), float32] /* ty=Tensor[(128, 128, 3, 3), float32] */, %stage2_unit2_bn2_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn2_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn2_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_bn2_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage2_unit2_conv2_weight: Tensor[(128, 128, 3, 3), float32] /* ty=Tensor[(128, 128, 3, 3), float32] */, %stage3_unit1_bn1_gamma: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_bn1_beta: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_bn1_moving_mean: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_bn1_moving_var: Tensor[(128), float32] /* ty=Tensor[(128), float32] */, %stage3_unit1_conv1_weight: Tensor[(256, 128, 3, 3), float32] /* ty=Tensor[(256, 128, 3, 3), float32] */, %stage3_unit1_bn2_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_bn2_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_bn2_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_bn2_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit1_conv2_weight: Tensor[(256, 256, 3, 3), float32] /* ty=Tensor[(256, 256, 3, 3), float32] */, %stage3_unit1_sc_weight: Tensor[(256, 128, 1, 1), float32] /* ty=Tensor[(256, 128, 1, 1), float32] */, %stage3_unit2_bn1_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn1_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn1_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn1_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_conv1_weight: Tensor[(256, 256, 3, 3), float32] /* ty=Tensor[(256, 256, 3, 3), float32] */, %stage3_unit2_bn2_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn2_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn2_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_bn2_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage3_unit2_conv2_weight: Tensor[(256, 256, 3, 3), float32] /* ty=Tensor[(256, 256, 3, 3), float32] */, %stage4_unit1_bn1_gamma: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_bn1_beta: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_bn1_moving_mean: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_bn1_moving_var: Tensor[(256), float32] /* ty=Tensor[(256), float32] */, %stage4_unit1_conv1_weight: Tensor[(512, 256, 3, 3), float32] /* ty=Tensor[(512, 256, 3, 3), float32] */, %stage4_unit1_bn2_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_bn2_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_bn2_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_bn2_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit1_conv2_weight: Tensor[(512, 512, 3, 3), float32] /* ty=Tensor[(512, 512, 3, 3), float32] */, %stage4_unit1_sc_weight: Tensor[(512, 256, 1, 1), float32] /* ty=Tensor[(512, 256, 1, 1), float32] */, %stage4_unit2_bn1_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn1_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn1_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn1_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_conv1_weight: Tensor[(512, 512, 3, 3), float32] /* ty=Tensor[(512, 512, 3, 3), float32] */, %stage4_unit2_bn2_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn2_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn2_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_bn2_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %stage4_unit2_conv2_weight: Tensor[(512, 512, 3, 3), float32] /* ty=Tensor[(512, 512, 3, 3), float32] */, %bn1_gamma: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %bn1_beta: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %bn1_moving_mean: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %bn1_moving_var: Tensor[(512), float32] /* ty=Tensor[(512), float32] */, %fc1_weight: Tensor[(1000, 512), float32] /* ty=Tensor[(1000, 512), float32] */, %fc1_bias: Tensor[(1000), float32] /* ty=Tensor[(1000), float32] */) -> Tensor[(1, 1000), float32] {
%0 = nn.batch_norm(%data, %bn_data_gamma, %bn_data_beta, %bn_data_moving_mean, %bn_data_moving_var, epsilon=2e-05f, scale=False) /* ty=(Tensor[(1, 3, 224, 224), float32], Tensor[(3), float32], Tensor[(3), float32]) */;
%1 = %0.0 /* ty=Tensor[(1, 3, 224, 224), float32] */;
%2 = nn.conv2d(%1, %conv0_weight, strides=[2, 2], padding=[3, 3, 3, 3], channels=64, kernel_size=[7, 7]) /* ty=Tensor[(1, 64, 112, 112), float32] */;
%3 = nn.batch_norm(%2, %bn0_gamma, %bn0_beta, %bn0_moving_mean, %bn0_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 112, 112), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%4 = %3.0 /* ty=Tensor[(1, 64, 112, 112), float32] */;
%5 = nn.relu(%4) /* ty=Tensor[(1, 64, 112, 112), float32] */;
%6 = nn.max_pool2d(%5, pool_size=[3, 3], strides=[2, 2], padding=[1, 1, 1, 1]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%7 = nn.batch_norm(%6, %stage1_unit1_bn1_gamma, %stage1_unit1_bn1_beta, %stage1_unit1_bn1_moving_mean, %stage1_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%8 = %7.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%9 = nn.relu(%8) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%10 = nn.conv2d(%9, %stage1_unit1_conv1_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%11 = nn.batch_norm(%10, %stage1_unit1_bn2_gamma, %stage1_unit1_bn2_beta, %stage1_unit1_bn2_moving_mean, %stage1_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%12 = %11.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%13 = nn.relu(%12) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%14 = nn.conv2d(%13, %stage1_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%15 = nn.conv2d(%9, %stage1_unit1_sc_weight, padding=[0, 0, 0, 0], channels=64, kernel_size=[1, 1]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%16 = add(%14, %15) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%17 = nn.batch_norm(%16, %stage1_unit2_bn1_gamma, %stage1_unit2_bn1_beta, %stage1_unit2_bn1_moving_mean, %stage1_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%18 = %17.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%19 = nn.relu(%18) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%20 = nn.conv2d(%19, %stage1_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%21 = nn.batch_norm(%20, %stage1_unit2_bn2_gamma, %stage1_unit2_bn2_beta, %stage1_unit2_bn2_moving_mean, %stage1_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%22 = %21.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%23 = nn.relu(%22) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%24 = nn.conv2d(%23, %stage1_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%25 = add(%24, %16) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%26 = nn.batch_norm(%25, %stage2_unit1_bn1_gamma, %stage2_unit1_bn1_beta, %stage2_unit1_bn1_moving_mean, %stage2_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%27 = %26.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%28 = nn.relu(%27) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%29 = nn.conv2d(%28, %stage2_unit1_conv1_weight, strides=[2, 2], padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%30 = nn.batch_norm(%29, %stage2_unit1_bn2_gamma, %stage2_unit1_bn2_beta, %stage2_unit1_bn2_moving_mean, %stage2_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%31 = %30.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%32 = nn.relu(%31) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%33 = nn.conv2d(%32, %stage2_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%34 = nn.conv2d(%28, %stage2_unit1_sc_weight, strides=[2, 2], padding=[0, 0, 0, 0], channels=128, kernel_size=[1, 1]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%35 = add(%33, %34) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%36 = nn.batch_norm(%35, %stage2_unit2_bn1_gamma, %stage2_unit2_bn1_beta, %stage2_unit2_bn1_moving_mean, %stage2_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%37 = %36.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%38 = nn.relu(%37) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%39 = nn.conv2d(%38, %stage2_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%40 = nn.batch_norm(%39, %stage2_unit2_bn2_gamma, %stage2_unit2_bn2_beta, %stage2_unit2_bn2_moving_mean, %stage2_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%41 = %40.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%42 = nn.relu(%41) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%43 = nn.conv2d(%42, %stage2_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3]) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%44 = add(%43, %35) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%45 = nn.batch_norm(%44, %stage3_unit1_bn1_gamma, %stage3_unit1_bn1_beta, %stage3_unit1_bn1_moving_mean, %stage3_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 128, 28, 28), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%46 = %45.0 /* ty=Tensor[(1, 128, 28, 28), float32] */;
%47 = nn.relu(%46) /* ty=Tensor[(1, 128, 28, 28), float32] */;
%48 = nn.conv2d(%47, %stage3_unit1_conv1_weight, strides=[2, 2], padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%49 = nn.batch_norm(%48, %stage3_unit1_bn2_gamma, %stage3_unit1_bn2_beta, %stage3_unit1_bn2_moving_mean, %stage3_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%50 = %49.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%51 = nn.relu(%50) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%52 = nn.conv2d(%51, %stage3_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%53 = nn.conv2d(%47, %stage3_unit1_sc_weight, strides=[2, 2], padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%54 = add(%52, %53) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%55 = nn.batch_norm(%54, %stage3_unit2_bn1_gamma, %stage3_unit2_bn1_beta, %stage3_unit2_bn1_moving_mean, %stage3_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%56 = %55.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%57 = nn.relu(%56) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%58 = nn.conv2d(%57, %stage3_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%59 = nn.batch_norm(%58, %stage3_unit2_bn2_gamma, %stage3_unit2_bn2_beta, %stage3_unit2_bn2_moving_mean, %stage3_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%60 = %59.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%61 = nn.relu(%60) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%62 = nn.conv2d(%61, %stage3_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3]) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%63 = add(%62, %54) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%64 = nn.batch_norm(%63, %stage4_unit1_bn1_gamma, %stage4_unit1_bn1_beta, %stage4_unit1_bn1_moving_mean, %stage4_unit1_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 256, 14, 14), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%65 = %64.0 /* ty=Tensor[(1, 256, 14, 14), float32] */;
%66 = nn.relu(%65) /* ty=Tensor[(1, 256, 14, 14), float32] */;
%67 = nn.conv2d(%66, %stage4_unit1_conv1_weight, strides=[2, 2], padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%68 = nn.batch_norm(%67, %stage4_unit1_bn2_gamma, %stage4_unit1_bn2_beta, %stage4_unit1_bn2_moving_mean, %stage4_unit1_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%69 = %68.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%70 = nn.relu(%69) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%71 = nn.conv2d(%70, %stage4_unit1_conv2_weight, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%72 = nn.conv2d(%66, %stage4_unit1_sc_weight, strides=[2, 2], padding=[0, 0, 0, 0], channels=512, kernel_size=[1, 1]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%73 = add(%71, %72) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%74 = nn.batch_norm(%73, %stage4_unit2_bn1_gamma, %stage4_unit2_bn1_beta, %stage4_unit2_bn1_moving_mean, %stage4_unit2_bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%75 = %74.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%76 = nn.relu(%75) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%77 = nn.conv2d(%76, %stage4_unit2_conv1_weight, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%78 = nn.batch_norm(%77, %stage4_unit2_bn2_gamma, %stage4_unit2_bn2_beta, %stage4_unit2_bn2_moving_mean, %stage4_unit2_bn2_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%79 = %78.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%80 = nn.relu(%79) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%81 = nn.conv2d(%80, %stage4_unit2_conv2_weight, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3]) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%82 = add(%81, %73) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%83 = nn.batch_norm(%82, %bn1_gamma, %bn1_beta, %bn1_moving_mean, %bn1_moving_var, epsilon=2e-05f) /* ty=(Tensor[(1, 512, 7, 7), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%84 = %83.0 /* ty=Tensor[(1, 512, 7, 7), float32] */;
%85 = nn.relu(%84) /* ty=Tensor[(1, 512, 7, 7), float32] */;
%86 = nn.global_avg_pool2d(%85) /* ty=Tensor[(1, 512, 1, 1), float32] */;
%87 = nn.batch_flatten(%86) /* ty=Tensor[(1, 512), float32] */;
%88 = nn.dense(%87, %fc1_weight, units=1000) /* ty=Tensor[(1, 1000), float32] */;
%89 = nn.bias_add(%88, %fc1_bias, axis=-1) /* ty=Tensor[(1, 1000), float32] */;
nn.softmax(%89) /* ty=Tensor[(1, 1000), float32] */
}
Compilation
下一步是使用 Relay/TVM 管道对模型进行编译。用户可以指定编译的优化级别(opt_level)。目前这个值可以是 0 到 3。优化 passes ** 包括 算子融合(operator fusion、预计算(pre-computation)、布局变换(layout transformation)**等。
relay.build() 返回三个部分:json 格式的执行图,TVM 模块库中专门为这个图在目标硬件上编译的函数,以及模型的参数 blobs。在编译过程中,Relay 做了图层面的优化,而 TVM 做了张量层面的优化,从而产生了优化的运行模块为模型服务。
首先为 Nvidia GPU 进行编译。在幕后, relay.build() 首先做了一些图层面的优化,例如修剪(pruning)、融合(fusing)等,然后将算子(即优化后的图的节点)注册到 TVM 实现中,生成 tvm.module。为了生成模块库,TVM 将首先把高层 IR 转移到指定目标后端的低层内在 IR 中,在这个例子中是 CUDA。然后机器代码将被生成为模块库。
opt_level = 3
target = tvm.target.cuda()
with tvm.transform.PassContext(opt_level=opt_level):
lib = relay.build(mod, target, params=params)
注意:
在执行relay.build时,报错:WARNING:root:Failed to download tophub package for cuda: <urlopen error [Errno 99] Cannot assign requested address>,
解决方法:拷贝下载tophub并拷贝至/root/.tvm/tophub下
git clone git@github.com:tlc-pack/tophub.git
mv ./tophub/* /root/.tvm/tophub
Run the generate library
可以创建图执行器并在 Nvidia GPU 上运行该模块。
# create random input
dev = tvm.cuda()
data = np.random.uniform(-1, 1, size=data_shape).astype("float32")
# create module
module = graph_executor.GraphModule(lib["default"](dev))
# set input and parameters
module.set_input("data", data)
# run
module.run()
# get output
out = module.get_output(0, tvm.nd.empty(out_shape)).numpy()
# Print first 10 elements of output
print(out.flatten()[0:10])
输出结果:
[0.00089283 0.00103331 0.0009094 0.00102275 0.00108751 0.00106737
0.00106262 0.00095838 0.00110792 0.00113151]
Save and Load Compiled Module
也可以将 graph、lib 和参数保存到文件中,并在部署环境中加载它们。
# save the graph, lib and params into separate files
from tvm.contrib import utils
temp = utils.tempdir()
path_lib = temp.relpath("deploy_lib.tar")
lib.export_library(path_lib)
print(temp.listdir())
输出结果:
['deploy_lib.tar']
# load the module back.
loaded_lib = tvm.runtime.load_module(path_lib)
input_data = tvm.nd.array(data)
module = graph_executor.GraphModule(loaded_lib["default"](dev))
module.run(data=input_data)
out_deploy = module.get_output(0).numpy()
# Print first 10 elements of output
print(out_deploy.flatten()[0:10])
# check whether the output from deployed module is consistent with original one
tvm.testing.assert_allclose(out_deploy, out, atol=1e-5)
输出结果:
[0.00089283 0.00103331 0.0009094 0.00102275 0.00108751 0.00106737
0.00106262 0.00095838 0.00110792 0.00113151]
TVM: 编译深度学习模型的快速入门教程的更多相关文章
- TVM将深度学习模型编译为WebGL
使用TVM将深度学习模型编译为WebGL TVM带有全新的OpenGL / WebGL后端! OpenGL / WebGL后端 TVM已经瞄准了涵盖各种平台的大量后端:CPU,GPU,移动设备等.这次 ...
- 【PyTorch深度学习60分钟快速入门 】Part1:PyTorch是什么?
0x00 PyTorch是什么? PyTorch是一个基于Python的科学计算工具包,它主要面向两种场景: 用于替代NumPy,可以使用GPU的计算力 一种深度学习研究平台,可以提供最大的灵活性 ...
- 【PyTorch深度学习60分钟快速入门 】Part3:神经网络
神经网络可以通过使用torch.nn包来构建. 既然你已经了解了autograd,而nn依赖于autograd来定义模型并对其求微分.一个nn.Module包含多个网络层,以及一个返回输出的方法f ...
- 【PyTorch深度学习60分钟快速入门 】Part5:数据并行化
在本节中,我们将学习如何利用DataParallel使用多个GPU. 在PyTorch中使用多个GPU非常容易,你可以使用下面代码将模型放在GPU上: model.gpu() 然后,你可以将所有张 ...
- 【PyTorch深度学习60分钟快速入门 】Part4:训练一个分类器
太棒啦!到目前为止,你已经了解了如何定义神经网络.计算损失,以及更新网络权重.不过,现在你可能会思考以下几个方面: 0x01 数据集 通常,当你需要处理图像.文本.音频或视频数据时,你可以使用标准 ...
- 【PyTorch深度学习60分钟快速入门 】Part2:Autograd自动化微分
在PyTorch中,集中于所有神经网络的是autograd包.首先,我们简要地看一下此工具包,然后我们将训练第一个神经网络. autograd包为张量的所有操作提供了自动微分.它是一个运行式定义的 ...
- 【PyTorch深度学习60分钟快速入门 】Part0:系列介绍
说明:本系列教程翻译自PyTorch官方教程<Deep Learning with PyTorch: A 60 Minute Blitz>,基于PyTorch 0.3.0.post4 ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
随机推荐
- C语言中函数有多个返回值的实现
在C中,正常情况下,我们只能从函数中返回一个值.但在有些情况下,我们需要从函数中返回多个值,此时使用数组或指针能够很好地完成这样的任务.这里是一个示例,这个程序使用一个整型数组作为参数,并将数组元素的 ...
- 1 前端知识学习-初始Web和Web标准
0️⃣ 初始Web和Web标准 Web Web(World Wide Web) 即全球广域网.也成为万维网.我们常说的Web端就是网页端. 网页 网页是构成网站的基本元素.网页主要由文字.图像 ...
- 【MATLAB习题】四杆机构的运动学参数求解
1.问题描述 2. 推导过程 3. matlab代码 最新版代码 直接采用求微分的方式得到角度,角速度等数值解,速度慢,但是代码少,容易看懂(矩阵看起来真难受). 以前做的一个博客文章用的是矩阵运算求 ...
- excel怎么根据数值做进度条
开始->条件格式->数据条
- SVG path 标签根据两点和角度绘制弧线
同步发布:https://blog.jijian.link/2020-04-14/svg-arc/ 由于功能受限,此处不能放 iframe 嵌入链接,如需看到实时效果,请移步 https://blog ...
- chrome播放webRTC的H265视频方法
需求描述 最近有需求实现浏览器直接播放摄像头视频 鉴于Camera本身支持了rtsp流,本想web直接播放rtsp,但是还不行,搜了一下webRTC实现的效果和延迟会好一些.于是就使用了mediaMT ...
- 【Win32】VC6 Visual C/C++ 6.0 修改程序图标
零.需求 就想给自己的C程序加个图标,好看些 一.解决 1.操作步骤 1.新建一个资源脚本 2.在新建的脚本上右键,选择插入 3.选择Icon,点新建或者引入,如果你没有准备图标点新建,有的话直接点引 ...
- fastreport6的frxpngimage.pas不能编译xe下
升级很痛苦,因为兼容问题. fastreport6的frxpngimage.pas不能编译出现错误 procedure TChunkIDAT.CopyInterlacedRGB8(const Pass ...
- 支付系统扩展:ZKmall开源商城支持跨境多币种结算的开发实践
于跨境电商平台而言,多币种支付是满足全球消费者支付需求的关键.不同国家和地区的消费者习惯使用各自的货币进行支付,如果平台不支持多币种交易,将极大地限制用户的购买意愿和支付便利性.因此,跨境电商平台必须 ...
- 配置QtJambi编译环境
所有代码都是以C++ GUI Qt 4编程(第二版)为准,只是重新用Java + QtJambi重写了. 当前编译IDE是intellij idea 2024, 系统win 11 LTSC.需要配置的 ...