实战 PCA
简介
PCA
code
#加载数据
import pandas as pd
import numpy as np
data = pd.read_csv('iris_data.csv')
data.head(100)
print(pd.value_counts(data.loc[:,'label']))
#定义X,y
X = data.drop(['target','label'],axis=1)#去掉最后两列
y = data.loc[:,'label']
#建立模型
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=3)#选用最近的三个点来预测新的点属于哪一类
KNN.fit(X,y)
y_predict = KNN.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
#将数据进行标准化处理
from sklearn.preprocessing import StandardScaler
X_norm = StandardScaler().fit_transform(X)
print(X_norm)
#数据可视化
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(20,5))
plt.subplot(121)
plt.hist(X.loc[:,'sepal length'],bins=100)#这里只取sepal length这一个维度
plt.subplot(122)
plt.hist(X_norm[:,0],bins=100)#将标准化处理后的数据可视化
plt.show()
#计算均值和标准差
x1_mean = X.loc[:,'sepal length'].mean()#原数据的均值
x1_norm_mean = X_norm[:,0].mean()#处理后数据的均值
x1_sigma = X.loc[:,'sepal length'].std()#原数据的标准差
x1_norm_sigma = X_norm[:,0].std()#处理后数据的标准差
print(x1_mean,x1_sigma,x1_norm_mean,x1_norm_sigma)
#看一下原数据的维度,下面要用
print(X.shape)
# pca analysis
from sklearn.decomposition import PCA
pca = PCA(n_components=4)#原数据是维度是4,要进行同等维度的PCA处理,故n_components=4
X_pca = pca.fit_transform(X_norm)#这里已经是经过PCA处理的主成分了
#计算各维度下的主成分的方差比例
var_ratio = pca.explained_variance_ratio_
print(var_ratio)
#可视化数据
fig2 = plt.figure(figsize=(20,5))
plt.bar([1,2,3,4],var_ratio)#有4个维度,所以这里是1,2,3,4
plt.xticks([1,2,3,4],['PC1','PC2','PC3','PC4'])#给每维度的主成分的方差比例图加上名称
plt.ylabel('variance ratio of each PC')#给y轴加上名称
plt.show()
pca = PCA(n_components=2) #因为我们要把数据维度降为2,所以这里n_components=2
X_pca = pca.fit_transform(X_norm)
X_pca.shape #看一下维度,这里已经为2了
type(X_pca)#看一下类型
#可视化数据
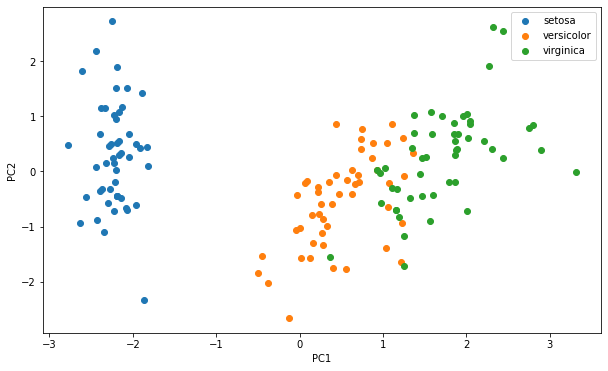
fig3 = plt.figure(figsize=(10,6))
setosa = plt.scatter(X_pca[:,0][y==0],X_pca[:,1][y==0])#标签为0的
versicolor = plt.scatter(X_pca[:,0][y==1],X_pca[:,1][y==1])#标签为1的
virginica = plt.scatter(X_pca[:,0][y==2],X_pca[:,1][y==2])#标签为2的
plt.legend((setosa,versicolor,virginica),('setosa','versicolor','virginica'))
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X_pca,y)
y_predict = KNN.predict(X_pca)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
image
实战 PCA的更多相关文章
- 主成分分析(PCA)原理及R语言实现
原理: 主成分分析 - stanford 主成分分析法 - 智库 主成分分析(Principal Component Analysis)原理 主成分分析及R语言案例 - 文库 主成分分析法的原理应用及 ...
- 主成分分析(PCA)原理及R语言实现 | dimension reduction降维
如果你的职业定位是数据分析师/计算生物学家,那么不懂PCA.t-SNE的原理就说不过去了吧.跑通软件没什么了不起的,网上那么多教程,copy一下就会.关键是要懂其数学原理,理解算法的假设,适合解决什么 ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- 《机器学习实战》学习笔记——第13章 PCA
1. 降维技术 1.1 降维的必要性 1. 多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯.2. 高维空间本身具有稀疏性.一维正态分布有68%的值落于正负 ...
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- 《机器学习实战》学习笔记第十三章 —— 利用PCA来简化数据
相关博文: 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA) 主成分分析(PCA)的推导与解释 主要内容: 一.向量內积的几何意义 二.基的变换 三.协方差矩阵 四.PCA求解 一.向量內 ...
- python异常值(outlier)检测实战:KMeans + PCA + IsolationForest + SVM + EllipticEnvelope
机器学习_深度学习_入门经典(博主永久免费教学视频系列) https://study.163.com/course/courseMain.htm?courseId=1006390023&sha ...
- 【机器学习实战】第13章 利用 PCA 来简化数据
第13章 利用 PCA 来简化数据 降维技术 场景 我们正通过电视观看体育比赛,在电视的显示器上有一个球. 显示器大概包含了100万像素点,而球则可能是由较少的像素点组成,例如说一千个像素点. 人们实 ...
- 13机器学习实战之PCA(2)
PCA——主成分分析 简介 PCA全称Principal Component Analysis,即主成分分析,是一种常用的数据降维方法.它可以通过线性变换将原始数据变换为一组各维度线性无关的表示,以此 ...
随机推荐
- 基于源码分析 HikariCP 常见参数的具体含义
HikariCP 是目前风头最劲的 JDBC 连接池,号称性能最佳,SpringBoot 2.0 也将 HikariCP 作为默认的数据库连接池. 要想用好 HikariCP,理解常见参数的具体含义至 ...
- 12.ZIP伪加密
题目是伪加密,打开压缩包,发现里面直接放着flag.txt,但是好像需要输入密码,此时我们在不看题目的第一反应就是破解,但是无果,看了别人的wp之后,了解了一点伪加密. ZIP文件分为:压缩源文件数据 ...
- 使用搜索引擎时如何排除一些垃圾站点,比如csdn.net
使用搜索引擎时需要排除一些垃圾站点,比如csdn.net时,可以在关键词后面加上-site:csdn.net: stable diffusion docker部署TensorFlow 教程 -site ...
- element-ui $prompt输入弹框和$confirm确认弹框用法--输入框默认值、校验、阻止关闭等问题
可输入弹框 $prompt 1.默认值.校验 this.$prompt( '请输入文件夹名称:', '提示', { confirmButtonText: '确定', cancelButtonText: ...
- python相关函数
1.pow()函数 pow()函数解释 pow(x,y):表示x的y次幂. >>> pow(2,4) 16 >>> pow(x,y,z):表示x的y次幂后除以z的余 ...
- FastAPI与Tortoise-ORM模型配置及aerich迁移工具
title: FastAPI与Tortoise-ORM模型配置及aerich迁移工具 date: 2025/04/30 00:11:45 updated: 2025/04/30 00:11:45 au ...
- 【经验】博客|Windows下,一键安装和部署 hexo-admin 插件(Hexo 静态博客)
1. 在博客根目录下运行下列指令 npm install --save hexo-admin -y echo "hexo clean && hexo g -d"&g ...
- [随记]-SpringMVC中的handler到底是什么东西
HandlerMapping 初始化时候的 HandlerMapping 有,按顺序排列: requestMappingHandlerMapping beanNameHandlerMapping -& ...
- Node v18.6 发布的这个新特性未来可能改变前端工程化
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- codeup之【字符串】回文串
题目描述 读入一串字符,判断是否是回文串."回文串"是一个正读和反读都一样的字符串,比如"level"或者"noon"等等就是回文串. 输入 ...