DeepSeek-R1本地部署如何选择适合你的版本?看这里
DeepSeek-R1本地部署:选择最适合你的版本,轻松搞定!

关于本地部署DeepSeek-R1前期知识
如果你正在考虑将DeepSeek-R1部署到本地服务器上,了解每种类型的硬件需求是非常重要的。DeepSeek-R1是一个非常强大的语言模型,它有多个不同的版本,每个版本在计算资源和硬件要求上都有不同的需求。本文将帮助你理解每个版本的参数、所需硬件以及如何根据自己的需求选择合适的类型。

选择最合适你的版本
PS:本文是本地化部署DeepSeek系列教程第二篇。本系列共计4篇文章,最终,我们讲实操在Windows操作系统和Mac操作系统实现本地部署DeepSeek-R1大模型。
DeepSeek-R1的不同类型及含义
DeepSeek-R1有多个不同的类型,每个类型的名称后面跟着一个数字(比如1.5B、7B、14B等),这些数字代表模型的参数量。参数量直接决定了模型的计算能力和存储需求,数字越大,模型越强,但也需要更多的硬件资源。
什么是“B”?
在这些数字中,B代表“billion”(十亿),所以:
1.5B意味着该模型有15亿个参数
7B表示70亿个参数
8B表示80亿个参数
14B表示140亿个参数
32B表示320亿个参数
70B表示700亿个参数
671B表示6710亿个参数
这些模型的参数量越大,处理的数据和生成的内容就越复杂,但它们也需要更多的计算资源来运行。
每种类型的硬件需求
每个模型的计算和存储需求都有所不同,下面我们列出了DeepSeek-R1的各个型号,并给出了所需的硬件配置。根据不同的使用需求,选择合适的模型可以帮助你节省成本,同时提升部署效率。
DeepSeek-R1类型信息表格
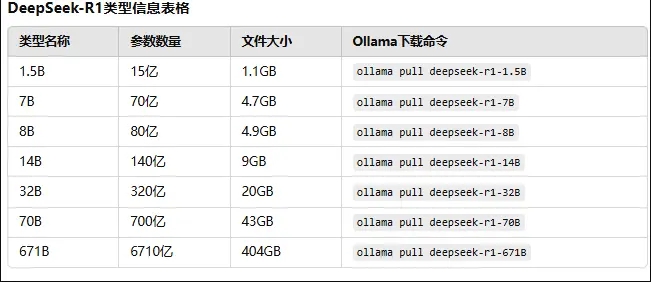
R1不同版本模型大小
各类型模型的硬件需求总结
根据你选择的型号,硬件需求会有所不同。以下是每个模型的大致硬件要求:
1.5B(1.1GB):
CPU:普通的四核或六核处理器即可。
显卡:中等性能显卡,如NVIDIA GTX 1650或RTX 2060。
内存:16GB RAM。
磁盘空间:至少50GB空闲空间。
7B(4.7GB):
CPU:6核或8核处理器。
显卡:NVIDIA RTX 3060或更强显卡。
内存:32GB RAM。
磁盘空间:至少100GB空闲空间。
8B(4.9GB):
CPU:6核或8核处理器。
显卡:NVIDIA RTX 3060或更强显卡。
内存:32GB RAM。
磁盘空间:至少100GB空闲空间。
14B(9GB):
CPU:8核以上处理器,如Intel i9或AMD Ryzen 9。
显卡:NVIDIA RTX 3080或更强。
内存:64GB RAM。
磁盘空间:至少200GB空闲空间。
32B(20GB):
CPU:8核以上处理器。
显卡:NVIDIA RTX 3090、A100或V100显卡。
内存:128GB RAM。
磁盘空间:至少500GB空闲空间。
70B(43GB):
CPU:12核以上处理器,推荐使用高端Intel或AMD处理器。
显卡:NVIDIA A100、V100显卡,甚至需要多个显卡配置。
内存:128GB RAM。
磁盘空间:至少1TB空闲空间。
671B(404GB):
CPU:高性能、多核CPU,建议多台服务器配置。
显卡:NVIDIA A100或多个V100显卡,甚至需要集群支持。
内存:至少512GB RAM。
磁盘空间:至少2TB空闲空间。
各模型硬件需求如下表:
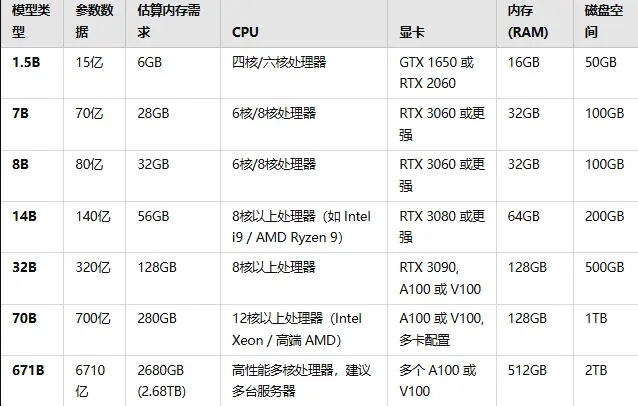
各模型对比
说明:
CPU:随着模型参数量的增加,CPU的核心数要求也逐渐增加。高端多核处理器有助于减少计算瓶颈,尤其在大模型推理时。
显卡:随着模型规模的增大,对显卡的要求也越来越高。GPU的显存和计算能力成为关键。如果单卡显存不够,可能需要多个显卡联合工作。
内存:内存不仅仅用于存储模型参数,还需要为计算过程中的中间结果、缓存等分配足够空间。大模型尤其对内存的需求大,超过32GB的模型在内存方面会有较大压力。
磁盘空间:磁盘空间是根据模型的大小和推理过程中的临时数据存储需求计算的。尤其对于大型模型,在存储和加载数据时需要更多的空间。
注意:
这些硬件需求是针对 推理 场景进行估算的,如果是 训练,硬件需求会更高,特别是在GPU和内存方面。
实际硬件需求还取决于模型优化方法、量化技术、分布式计算和云服务等因素,可能会有所不同。
每个参数需要多少字节?
一般来说,DeepSeek-R1模型中的每个参数占用4个字节(32位)。这个值相对固定,常用于大多数深度学习模型。通过这个假设,我们可以计算出每个版本大致需要多少内存。
计算方法:
每个参数需要4字节
假设某个模型有70亿个参数(即70B模型)
所以,内存需求 = 70亿个参数 × 4字节/参数 = 28GB
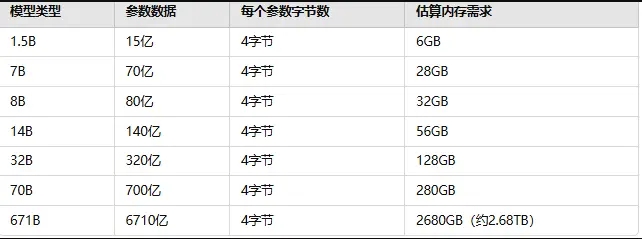
不同模型需要内存大小
疑问:7B或者8B是阉割版本吗?
在DeepSeek-r1中,1.5B、7B、8B模型分别指的是模型的参数数量:1.5B代表15亿个参数,7B代表70亿个参数,8B代表80亿个参数。这些参数数量直接影响模型的计算能力和所需的存储空间。
1.5B模型是较小的版本,计算能力较弱,但占用的内存和存储空间较小,适合对硬件要求不高的场景。
7B和8B是更强大的版本,参数更多,计算能力更强,因此模型的推理能力和生成质量也更高。
7B不是阉割版,它只是相对于8B而言,参数数量稍少,因此它的计算能力和生成效果可能略差,但并不意味着它比8B“功能不全”或者“缩水”,只是在计算能力上有所差距。
如果你对推理速度和资源占用有较高的要求,选择1.5B会更合适。如果你希望模型生成质量更高,可能更倾向于7B或8B。不过,性能差距主要体现在任务的复杂性和精度上。
下面是每个版本的计算能力和生成质量的详细比较:
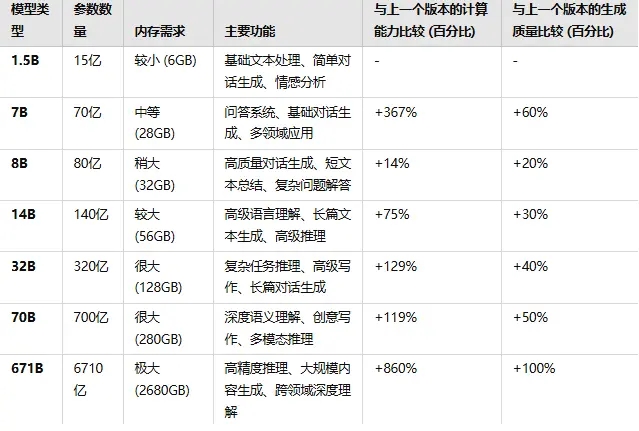
各个版本之间计算能力及生产能力对比
详细比较:
1.5B (15亿参数)
主要功能:适合基础的文本处理、情感分析、简单对话生成等。
与上一个版本的计算能力比较:没有前一个版本可比,作为最小模型,计算能力最弱。
与上一个版本的生成质量比较:同理,生成质量最低,文本较为简单和粗糙。
7B (70亿参数)
主要功能:能够处理多领域应用,如问答系统、对话生成、基本文本总结。
与上一个版本的计算能力比较:相比1.5B,计算能力提升了 367%,推理能力增强,能处理更多复杂任务。
与上一个版本的生成质量比较:相比1.5B,生成质量提升 60%,文本更自然,理解上下文能力增强。
8B (80亿参数)
主要功能:适用于高质量对话生成、短文本总结、复杂问题解答等。
与上一个版本的计算能力比较:相比7B,计算能力提升 14%,推理能力有所增强,但增幅较小。
与上一个版本的生成质量比较:相比7B,生成质量提升 20%,生成的文本更加自然、准确,适应更复杂的语境。
14B (140亿参数)
主要功能:高级语言理解、长篇文本生成、高级推理等任务。
与上一个版本的计算能力比较:相比8B,计算能力提升 75%,能够处理更复杂的语境和任务。
与上一个版本的生成质量比较:相比8B,生成质量提升 30%,长篇生成更连贯、自然,文本质量大幅提升。
32B (320亿参数)
主要功能:适合复杂推理任务、高级写作、长篇对话生成等。
与上一个版本的计算能力比较:相比14B,计算能力提升 129%,可以处理更多复杂任务。
与上一个版本的生成质量比较:相比14B,生成质量提升 40%,文本质量接近人工水平,适合高级写作和深度理解。
70B (700亿参数)
主要功能:深度语义理解、创意写作、多模态推理等高端应用。
与上一个版本的计算能力比较:相比32B,计算能力提升 119%,能够处理更加复杂的推理和生成任务。
与上一个版本的生成质量比较:相比32B,生成质量提升 50%,文本质量更加精细,几乎无明显错误,适用于创意和高精度任务。
671B (6710亿参数)
主要功能:超高精度推理、大规模内容生成、跨领域深度理解等任务。
与上一个版本的计算能力比较:相比70B,计算能力提升 860%,能够处理极为复杂的推理任务和大规模内容生成。
与上一个版本的生成质量比较:相比70B,生成质量提升 100%,文本生成几乎完美,几乎没有语境偏差,适用于最复杂的任务。
总结:
计算能力:从1.5B到671B,每个版本相对于前一个版本的计算能力都有显著提升,尤其是从 70B 到 671B,计算能力的大幅度提升说明了超大模型在推理复杂性上的巨大优势。
生成质量:生成质量从 1.5B 到 671B 逐步提升,每个新版本生成的文本更加自然、流畅,能够处理更复杂的上下文和细节。尤其是 70B 和 671B 版本的文本生成已经达到了极高水平,几乎可以媲美人工写作。
如何选择合适的型号?
选择哪种类型的DeepSeek-R1模型取决于你的应用场景以及硬件配置。如果你只是进行简单的文本处理、学习或小型项目,1.5B和7B可能就足够了。如果你的需求是生成高质量的文本,或者做大规模的数据处理,14B和更高的型号可能更适合。对于科研或者企业级应用,32B、70B甚至671B的型号能提供超高的性能和处理能力。
总结
不同型号的DeepSeek-R1:每个型号的参数数量和存储需求不同,越大的型号需要的硬件配置越高,处理能力也越强。
硬件配置:选择合适的型号时,需要考虑自己的硬件配置。例如,1.5B模型对硬件要求较低,而70B和671B则需要非常强大的计算资源。
估算内存需求:一般来说,每个参数占用4字节,通过参数数量和字节数可以粗略估算每个模型的内存需求。
DeepSeek-R1本地部署如何选择适合你的版本?看这里的更多相关文章
- 更改Dynamics 365 Customer Engagement本地部署的高级配置
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...
- virtual judge 本地部署方案
这是一种将自己的电脑当作服务器来部署一个vj的方法,我也是参考前辈们的做法稍作了改动,如果在服务器上部署的话需要在细节上稍作改动: 一.什么是Virtual Judge? vj的工作原理什么? vj ...
- Kubernetes 学习笔记(二):本地部署一个 kubernetes 集群
前言 前面用到过的 minikube 只是一个单节点的 k8s 集群,这对于学习而言是不够的.我们需要有一个多节点集群,才能用到各种调度/监控功能.而且单节点只能是一个加引号的"集群&quo ...
- 异常日志框架Exceptionless结合.NET Core(本地部署)
一.前言 1.分布式异常日志收集框架Exceptionless是开源的工具,根据官方给出的说明: Exceptionless可以为您的ASP.NET.Web API.WebFrm.WPF.控制台和MV ...
- Windows 之 手机访问 PC 端本地部署的站点
测试网页在手机上的显示工具我们可以使用谷歌内核的浏览器,打开开发者工具(F12),在device那里选择设备,然后刷新来查看网页在手机上的显示效果. 但毕竟是模拟的,如果想要在真机上调试该怎么办呢. ...
- ArcGIS API for JavaScript开发笔记(一)——ArcGIS for Javascript API 3.14本地部署
堪称史上最详细的< ArcGIS forJavascript API 3.14本地部署>文档,有图有真相~~~ ---------环境:Windows server 2012R2,IIS ...
- Win7环境下Apache+mod_wsgi本地部署Django
django基础已经掌握的同学可以尝试将项目发布已寻找些许成就感,以鼓励自己接下来进行django的进阶学习 以前你总是使用python manage.py runserver进行服务启动,但是却不知 ...
- 【Tomcat】使用tomcat manager 管理和部署项目,本地部署项目到服务器
在部署tomcat项目的时候,除了把war文件直接拷贝到tomcat的webapp目录下,还有一种方法可以浏览器中管理和部署项目,那就是使用tomcat manager. 默认情况下,tomcat m ...
- gitlab本地部署方法(ubuntu16.04+gitlab9.5.5)
Gitlab本地部署方法 1 前期准备 电脑配置:windows7 ,内存8GB以上(因为有4GB左右要分配给虚拟机中的ubuntu) 虚拟机:VMware Linux系统:ubuntu16.04 ...
- RocketMq灰皮书(二)------本地部署启动MQ
RocketMq灰皮书(二)------本地部署启动MQ Windows10本地部署RocketMQ 在上一篇文章中,我们对rocket的几个基本概念进行了介绍,也了解了业内几大消息中间件的区别.在本 ...
随机推荐
- elasticsearch-head插件基本使用
1. 查看搜索setting信息 mp_index/_settings 2. 设置分片数量 3, 修改数据刷新间隔 { "refresh_interval": "30s& ...
- 李世铭SFE|销售的四种境界-与之匹配的CRM功能
销售有四种境界,与之匹配的也应有四种不同的CRM系统的功能. 1.服务型销售 这类销售代表人数最为众多,超过半数的销售代表皆属于服务型.他们主要基于客户的需求,来提供相应的解决方案,或者公司所规定的某 ...
- shp转featureclass
public void ConvertShapefileToFeatureClass() { // Create a name object for the source (shapefile) wo ...
- Ant Design Pro项目ProTable怎么获取搜索表单值
前情 公司有经常需要做一些后台管理页面,我们选择了Ant Design Pro,它是基于 Ant Design 和 umi 的封装的一整套企业级中后台前端/设计解决方案. 产品效果图 最新接到的一个后 ...
- Ant Design Pro项目一初始化就报a标签嵌套a标签错误<a> cannot as a descendant of <a>
前情 公司经常需要做一些后台管理页面,我们选择了Ant Design Pro,它是基于 Ant Design 和 umi 的封装的一整套企业级中后台前端/设计解决方案. 坑位 按官方文挡一步步下来,项 ...
- Qt 子窗口 隐藏标题栏的图标,在任务栏上的不显示
Qt子窗口使用Qt::Dialog样式时,隐藏窗口标题栏图标方法: this->setWindowIcon(QIcon()); Qt子窗口,在任务栏上的不显示,最简单的方法是设置Qt::Tool ...
- cve-2021-3156-sudo堆溢出简单分析
调试方式 首先从github下载代码 https://github.com/sudo-project/sudo/archive/SUDO_1_9_5p1.tar.gz 编译 tar xf sudo-S ...
- tableau连接不上mysql或不显示mysql表的终极解决方法
[报错一]连不上mysql An error occurred while communicating with MySQL The connection to the data source mig ...
- R数据分析:cox模型如何做预测,高分文章复现
今天要给大家分享的文章是 Cone EB, Marchese M, Paciotti M, Nguyen DD, Nabi J, Cole AP, Molina G, Molina RL, Minam ...
- 【Word】文献引用批量上标
\[([0-9]{1,2})\]