AI应用实战课学习总结(7)聚类算法分析实战
大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第7站,一起了解下聚类算法基本概念 以及 通过聚类算法辅助用户画像的案例。
聚类基本介绍
聚类算法是将数据集中的对象分组成若干个簇,使得同一个簇中的对象之间的相似度较高,不同簇之间的对象相似度就较低。聚类算法可以帮助我们发现数据中的隐藏结构,可以用来给客户做分组、给文档做分组等等场景。
NOTE:聚类算法是目前我们这个系列接触到的第一个“无监督”机器学习算法。之前学习的回归和分类算法大部分都是“有监督”机器学习算法。
举个例子,电商平台可以利用聚类算法将用户分为不同的消费群体,然后针对不同群体推送个性化的广告和推荐商品。
聚类和分类的区别
聚类和分类最主要的区别有如下几点:
- 分类是监督学习,聚类是无监督学习
- 结果的含义
- 评估方法
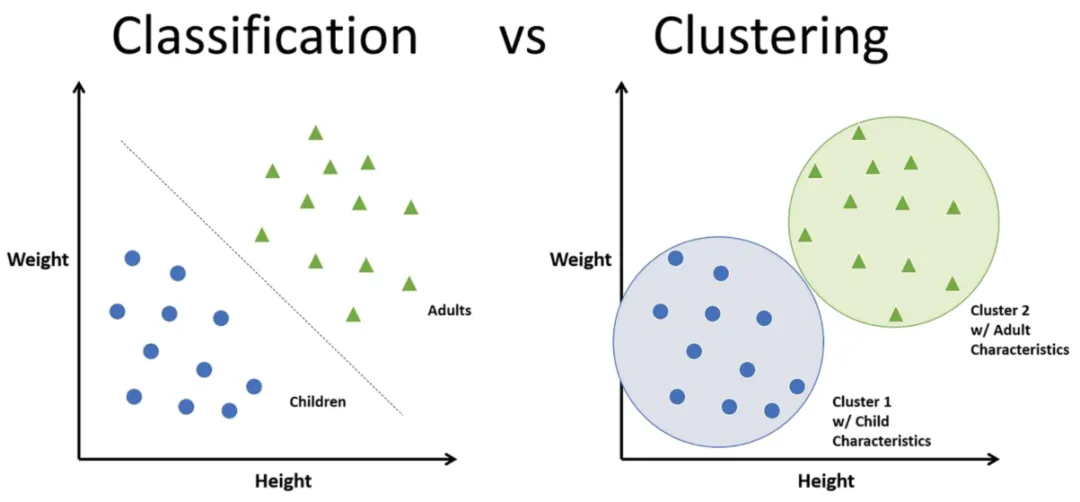
对于第一点,如何判断是监督还是无监督学习,主要是看数据集有没有被打上标签。对于无监督学习,机器通常是在没有任何标签的前提下自发地进行分组。对于第二点,分类的结果通常是预先定义好的类别,而聚类的结果则是一个个的数据簇,这些数据簇本身的结构是自发地凑在一起的而非预先定义好的。例如,下图中的分类是预先定义好了Adults 和 Children两个类别,而聚类则是没有预先定义完全通过自发凑在一起的,算法的结果只会告诉你Cluster1 和 Cluster2。
对于第三点,分类的评估方法有很多成熟的指标,例如准确率、精确率、召回率和F1分数等。聚类的性能效果则不太好评估,只能通过数据的结构或者额外的信息或者做数据可视化来进行观察。
总结:分类是监督学习,用于预测数据的类别;聚类是无监督学习,用于发现数据的隐藏结构。
常见聚类算法
最常见的聚类算法有:
- K-均指(K-Means)
- 层次聚类(Hierarchical Clustering)
- 密度聚类(DBSCAN)=> 当然,还有很多没有列出来!
这里,Edison再次推荐像我一样的零基础小白可以学习B站博主“五分钟机器学习”的视频,它在基础篇通俗易懂地讲解了 线性回归、逻辑回归、K近邻、决策树、K-Means、SVM、随机森林等算法,在进阶篇中介绍了梯度下降算法,简洁易懂,适合快速扫盲,这里我就不多赘述了。
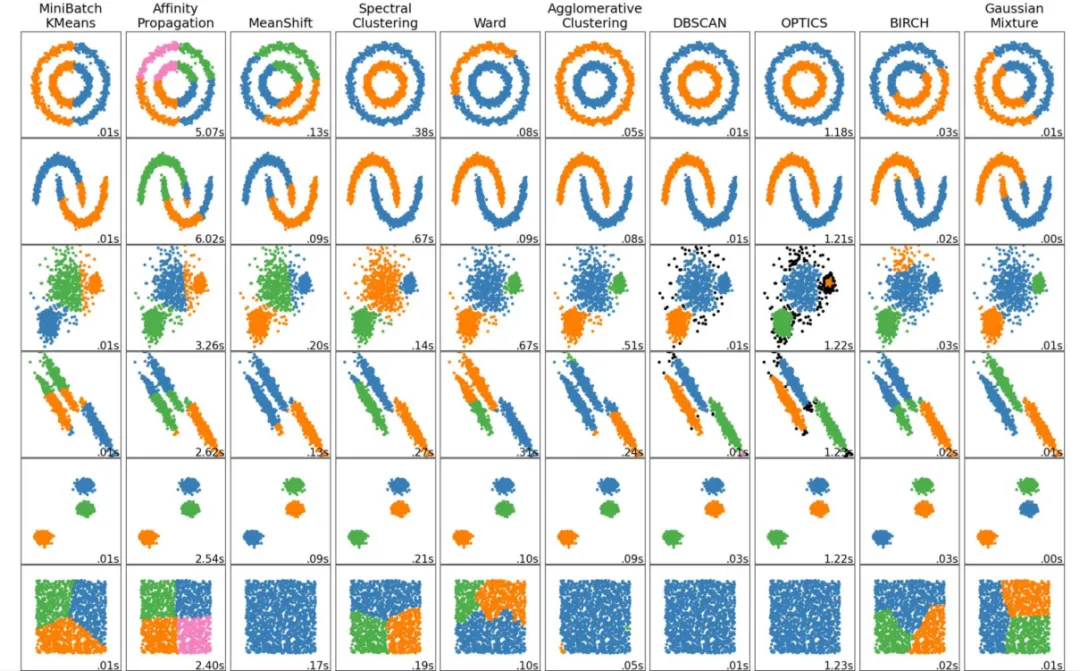
最后,如何选择聚类算法呢?早已经有大佬总结了这么一张图,你可以根据你数据集的分布形状,选择最合适的聚类算法,如下图所示:
电商用户画像聚类案例
问题背景:
某电商系统记录了过去12个月的订单数据
订单数据包括:用户ID、购买物品、金额、时间等
问题目标:
根据历史数据,给用户的消费能力做一个画像
NOTE:和我们之前的第5站做回归分析案例时使用的是同一个数据集,就让我们“一鱼多吃”吧。
用户画像是根据用户社会属性、生活习惯和消费行为等信息而抽象出的一个标签化的用户模型。构建用户画像的核心工作即是给用户贴“标签”,而标签是通过对用户信息分析而来的高度精炼的特征标识。
用户画像聚类代码实战
Step1 读取数据 及 数据预处理
import pandas as pd #导入Pandas
df_sales = pd.read_csv('eshop-orders.csv') #载入数据
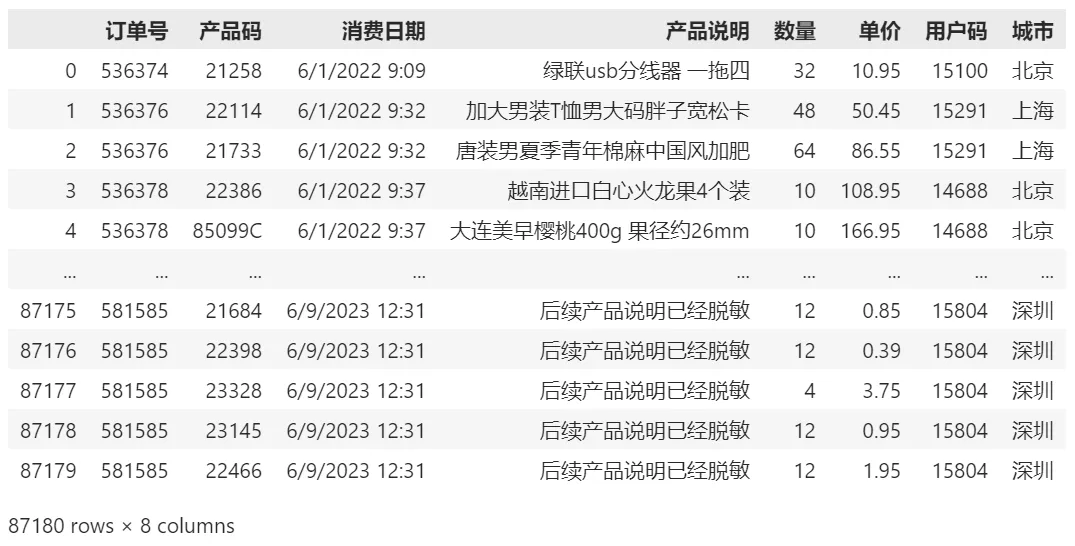
df_sales.head() #显示前5行数据
输出的数据展现成下面的样子:

同时,做一些预处理,清洗掉一些无用数据。
df_sales = df_sales.drop_duplicates() #删除重复的数据行
df_sales = df_sales.loc[df_sales['数量'] > 0] #清洗掉数量小于等于0的数据
计算每个订单的总价:
df_sales['总价'] = df_sales['数量'] * df_sales['单价'] #计算每单的总价
df_sales.head() #显示头几行数据

将用户提取出来形成单独的集合:

Step2 特征工程
这里和第5站一样,我们将原始订单数据转换为每一个用户的R、M、F值,R指Recency(用户的新近度,用来衡量用户是否在近期进行了消费),M指Money(用户共计消费了多少钱),F指Frequency(用户共计进行了多少次交易,即消费的频次)。
# Recency
df_sales['消费日期'] = pd.to_datetime(df_sales['消费日期']) #转化日期格式
df_recent_buy = df_sales.groupby('用户码').消费日期.max().reset_index() #构建消费日期信息
df_recent_buy.columns = ['用户码','最近日期'] #设定字段名
df_recent_buy['R值'] = (df_recent_buy['最近日期'].max() - df_recent_buy['最近日期']).dt.days #计算最新日期与上次消费日期的天数
df_user = pd.merge(df_user, df_recent_buy[['用户码','R值']], on='用户码') #把上次消费距最新日期的天数(R值)合并至df_user结构
# Frequency
df_frequency = df_sales.groupby('用户码').消费日期.count().reset_index() #计算每个用户消费次数,构建df_frequency对象
df_frequency.columns = ['用户码','F值'] #设定字段名称
df_user = pd.merge(df_user, df_frequency, on='用户码') #把消费频率整合至df_user结构
# Revenue
df_revenue = df_sales.groupby('用户码').总价.sum().reset_index() #根据消费总额,构建df_revenue对象
df_revenue.columns = ['用户码','M值'] #设定字段名称
df_user = pd.merge(df_user, df_revenue, on='用户码') #把消费金额整合至df_user结构 df_user.head() #显示头几行数据
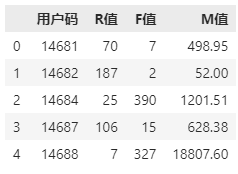
用户的RMF值如下图所示:
Step3 使用K-Means初次聚类找K值
这里使用了手肘法先粗略地做一下,目的并不是做聚类本身,而是通过循环9次聚类看看误差值,进而辅助选择一些K值。
import matplotlib.pyplot as plt #导入Matplotlib的pyplot模块
# 设置字体为SimHei,以正常显示中文标签
plt.rcParams["font.family"]=['SimHei']
plt.rcParams['font.sans-serif']=['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False from sklearn.cluster import KMeans #导入KMeans模块
def show_elbow(df, ax, title):
distance_list = []
K = range(1,9)
for k in K:
kmeans = KMeans(n_clusters=k, max_iter=100)
kmeans = kmeans.fit(df)
distance_list.append(kmeans.inertia_)
ax.plot(K, distance_list, 'bx-')
ax.set_xlabel('k')
ax.set_ylabel('距离均方误差')
ax.set_title(title) fig, axes = plt.subplots(1, 3, figsize=(18, 6)) show_elbow(df_user[['R值']], axes[0], 'R值聚类K值手肘图')
show_elbow(df_user[['F值']], axes[1], 'F值聚类K值手肘图')
show_elbow(df_user[['M值']], axes[2], 'M值聚类K值手肘图') plt.tight_layout()
plt.show()
显示的K值手肘图如下:
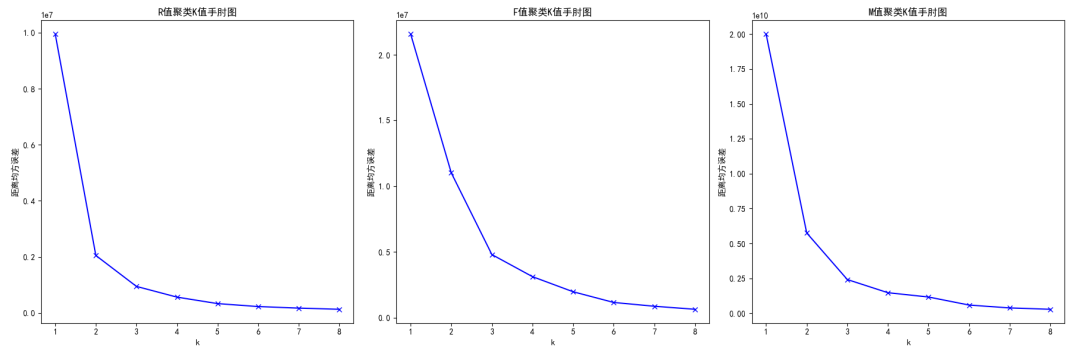
例如,这里最终显示的图中,2-4都是可以选择的K值。
关于手肘法:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。
Step4 使用K-Means创建和训练模型
这里我们选择K=3给R值 和 K=4给M和F值:
from sklearn.cluster import KMeans #导入KMeans模块
kmeans_R = KMeans(n_clusters=3) #设定K=3
kmeans_F = KMeans(n_clusters=4) #设定K=4
kmeans_M = KMeans(n_clusters=4) #设定K=4 kmeans_R.fit(df_user[['R值']]) #拟合模型
kmeans_F.fit(df_user[['F值']]) #拟合模型
kmeans_M.fit(df_user[['M值']]) #拟合模型 df_user['R值层级'] = kmeans_R.predict(df_user[['R值']]) #通过聚类模型求出R值的层级
df_user['F值层级'] = kmeans_F.predict(df_user[['F值']]) #通过聚类模型求出F值的层级
df_user['M值层级'] = kmeans_M.predict(df_user[['M值']]) #通过聚类模型求出M值的层级
df_user.head() #显示头几行数据
聚类后的R、F、M值的层级值如下所示:
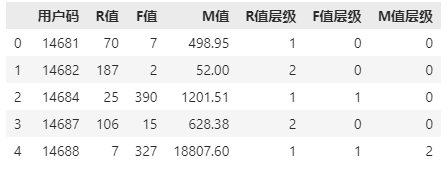
But,聚类后的层级自己是不知道哪个更重要或者优先级更高的,所以我们需要根据我们期望的重要性指标对其进行排序,才能满足我们的需求。
#定义一个order_cluster函数为聚类排序
def order_cluster(cluster_name, target_name,df,ascending=False):
new_cluster_name = 'new_' + cluster_name #新的聚类名称
df_new = df.groupby(cluster_name)[target_name].mean().reset_index() #按聚类结果分组,创建df_new对象
df_new = df_new.sort_values(by=target_name,ascending=ascending).reset_index(drop=True) #排序
df_new['index'] = df_new.index #创建索引字段
df_new = pd.merge(df,df_new[[cluster_name,'index']], on=cluster_name) #基于聚类名称把df_new还原为df对象,并添加索引字段
df_new = df_new.drop([cluster_name],axis=1) #删除聚类名称
df_new = df_new.rename(columns={"index":cluster_name}) #将索引字段重命名为聚类名称字段
return df_new #返回排序后的df_new对象 df_user = order_cluster('R值层级', 'R值', df_user, False) #调用簇排序函数,降序排列
df_user = order_cluster('F值层级', 'F值', df_user, True) #调用簇排序函数,升序排列
df_user = order_cluster('M值层级', 'M值', df_user, True) #调用簇排序函数,升序排列
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
df_user.head() #显示头几行数据
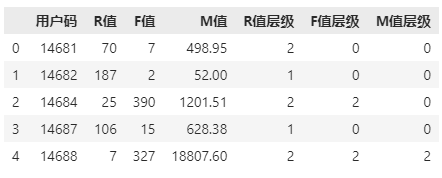
这里我们针对R值层级降序排列,针对F和M值层级升序排列:可以看到,如果三个层级的总分越高,那么对系统平台的价值也就越高。
Step5 可视化:为用户整体分组画像
现在为止,我们已经得到了RMF的层级的分数,可以根据总分进行一个分组,这里我们暂且将其定义为低价值(0<=总分<=2)、中价值(3<=总分<=4) 和 高价值(5<=总分<=8):
df_user['总分'] = df_user['R值层级'] + df_user['F值层级'] + df_user['M值层级'] #求出每个用户RFM总分
#在df_user对象中添加总体价值这个字段
df_user.loc[(df_user['总分']<=2) & (df_user['总分']>=0), '总体价值'] = '低价值'
df_user.loc[(df_user['总分']<=4) & (df_user['总分']>=3), '总体价值'] = '中价值'
df_user.loc[(df_user['总分']<=8) & (df_user['总分']>=5), '总体价值'] = '高价值'
df_user #显示df_user
显示的分组如下所示:
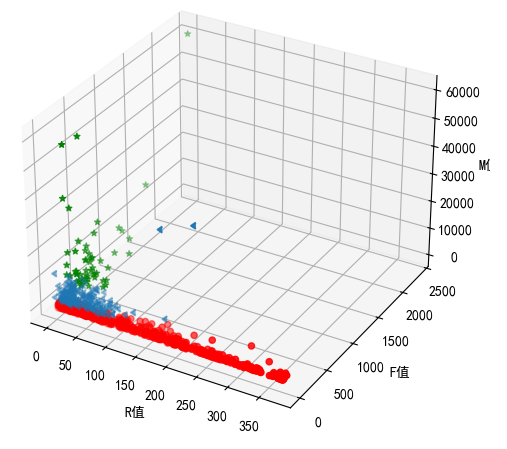
然后,我们可以进行一个可视化,由于有RMF三个特征,因此可以画一个三维散点图展示:
# 画三维图像,将RMF值都显示出来
plt.figure(figsize=(6,6)) # 图片大小
ax = plt.subplot(111, projection='3d') # 坐标系
ax.scatter(df_user.query("总体价值 == '高价值'")['R值'], # 散点图
df_user.query("总体价值 == '高价值'")['F值'],
df_user.query("总体价值 == '高价值'")['M值'], c='g',marker='*')
ax.scatter(df_user.query("总体价值 == '中价值'")['R值'],
df_user.query("总体价值 == '中价值'")['F值'],
df_user.query("总体价值 == '中价值'")['M值'], marker=8)
ax.scatter(df_user.query("总体价值 == '低价值'")['R值'],
df_user.query("总体价值 == '低价值'")['F值'],
df_user.query("总体价值 == '低价值'")['M值'], c='r')
ax.set_xlabel('R值') # 坐标轴
ax.set_ylabel('F值') # 坐标轴
ax.set_zlabel('M值') # 坐标轴
plt.show() # 输出
得到的三维散点图如下所示:三种类别的用户使用了不同的颜色表示,绿色的为高价值用户的数据散点分布,可以看到其RMF值总分都是较高的。而蓝色的为中价值用户,他们大多都是“偏科“用户,即可能单个特征比较高,但是总分不高。而红色的低价值用户的数据分布说明,他们可能偶尔来一次购物就再也不来了。
小结
本文介绍了机器学习中的聚类场景问题,常用的聚类算法 以及 分类和聚类的简单对比,最后再次通过电商订单数据做用户画像的案例做了一次聚类实战,相信对你理解聚类应用应该有所帮助。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

AI应用实战课学习总结(7)聚类算法分析实战的更多相关文章
- DDD实战课--学习笔记
目录 学好了DDD,你能做什么? 领域驱动设计:微服务设计为什么要选择DDD? 领域.子域.核心域.通用域和支撑域:傻傻分不清? 限界上下文:定义领域边界的利器 实体和值对象:从领域模型的基础单元看系 ...
- 《Angular4从入门到实战》学习笔记
<Angular4从入门到实战>学习笔记 腾讯课堂:米斯特吴 视频讲座 二〇一九年二月十三日星期三14时14分 What Is Angular?(简介) 前端最流行的主流JavaScrip ...
- SparkMLlib聚类学习之KMeans聚类
SparkMLlib聚类学习之KMeans聚类 (一),KMeans聚类 k均值算法的计算过程非常直观: 1.从D中随机取k个元素,作为k个簇的各自的中心. 2.分别计算剩下的元素到k个簇中心的相异度 ...
- [AI开发]将深度学习技术应用到实际项目
本文介绍如何将基于深度学习的目标检测算法应用到具体的项目开发中,体现深度学习技术在实际生产中的价值,算是AI算法的一个落地实现.本文算法部分可以参见前面几篇博客: [AI开发]Python+Tenso ...
- Python第十课学习
Python第十课学习 www.cnblogs.com/yuanchenqi/articles/5828233.html 函数: 1 减少代码的重复 2 更易扩展,弹性更强:便于日后文件功能的修改 3 ...
- Python第九课学习
Python第九课学习 数据结构: 深浅拷贝 集合set 函数: 概念 创建 参数 return 定义域 www.cnblogs.com/yuanchenqi/articles/5782764.htm ...
- Python第八课学习
Python第八课学习 www.cnblogs.com/resn/p/5800922.html 1 Ubuntu学习 根 / /: 所有目录都在 /boot : boot配置文件,内核和其他 linu ...
- python聚类算法实战详细笔记 (python3.6+(win10、Linux))
python聚类算法实战详细笔记 (python3.6+(win10.Linux)) 一.基本概念: 1.计算TF-DIF TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库 ...
- jQuery框架学习第十一天:实战jQuery表单验证及jQuery自动完成提示插件
jQuery框架学习第一天:开始认识jQueryjQuery框架学习第二天:jQuery中万能的选择器jQuery框架学习第三天:如何管理jQuery包装集 jQuery框架学习第四天:使用jQuer ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
随机推荐
- 3D Gaussian 三维视觉重建
论文资料 论文 https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/3d_gaussian_splatting_low.pdf 资料网站 ...
- Clion配置Fortran环境
1.安装CLion 下载链接:https://www.jetbrains.com/ 下载好后安装到指定目录即可 2.安装Fortran插件 3.编写程序 1)打开CLion,新建一个Fortran项目 ...
- 基于Redission实现分布式调度任务选主
在Spring Cloud微服务架构中,基于Redisson实现分布式调度任务的选主和心跳监听,可以通过以下完整方案实现.该方案结合了Redisson的分布式锁和发布/订阅功能,确保高可靠性和实时性: ...
- 康谋分享 | 数据隐私和匿名化:PIPL与GDPR下,如何确保数据合规?(二)
在上期数据隐私和匿名化系列文章中,我们主要分享了<中国个人信息保护法>(PIPL)和<欧盟通用数据保护条例>(GDPR)在涵盖范围.定义.敏感信息等方面的异同点,今天,我们将重 ...
- 数据处理与任务调度的双引擎:ETL工具PDI与DPDI调度管理工具的全面剖析
ETL工具PDI及调度DPDI ETL流程解析 数据抽取(Extract) 抽取是ETL的起点,需连接多种数据源获取原始数据.如从关系型数据库提取销售记录,或从文本文件读取客户信息,为后续处理奠定基础 ...
- Nacos源码—1.Nacos服务注册发现分析一
大纲 1.客户端如何发起服务注册 + 发送服务心跳 2.服务端如何处理客户端的服务注册请求 3.注册服务-如何实现高并发支撑上百万服务注册 4.内存注册表-如何处理注册表的高并发读写冲突 1.客户端如 ...
- mybatis—— 一个空格引发的血案
环境描述: 我在使用SSM做项目的时候需要一个需求:一个用户有多个角色,一个角色有多个权限,我需要根据用户的id找到用户的所有角色,及其对应的权限. 数据库是这个样子,users_role表记录了用户 ...
- 【BUG】C语言|左移之后,最高位的数字还在吗?(整型提升)
文章目录 问题概述 应用 怀旧 问题概述 这个错是刚学c语言的时候碰到的,突然好想我的c语言老师,所以在此记录一下. #include<stdio.h> void main(){ unsi ...
- 【HUST】论于渊《Orange‘s:一个操作系统的实现》第三章中PagingDemoProc的必要性,是否可以直接调用LinearAddrDemo?
相关代码如下(第三章pmtest9a.asm改写): LinearAddrDemo equ 00401000h ProcHust equ 00401000h ProcIS19 equ 00501000 ...
- 【MOOC】华中科技大学操作系统慕课答案-单元作业+第1~2章开放性思考题
单元作业答案如果没大问题的话,多半是直接摘抄自PPT. 文章目录 第一章 操作系统概述 单元作业(1) 开放性思考题 第二章 操作系统逻辑结构 单元作业 开放性思考题 第三章 操作系统用户界面 单元作 ...