如何在FastAPI中玩转GraphQL联邦架构,让数据源手拉手跳探戈?

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
发现1000+提升效率与开发的AI工具和实用程序:https://tools.cmdragon.cn/
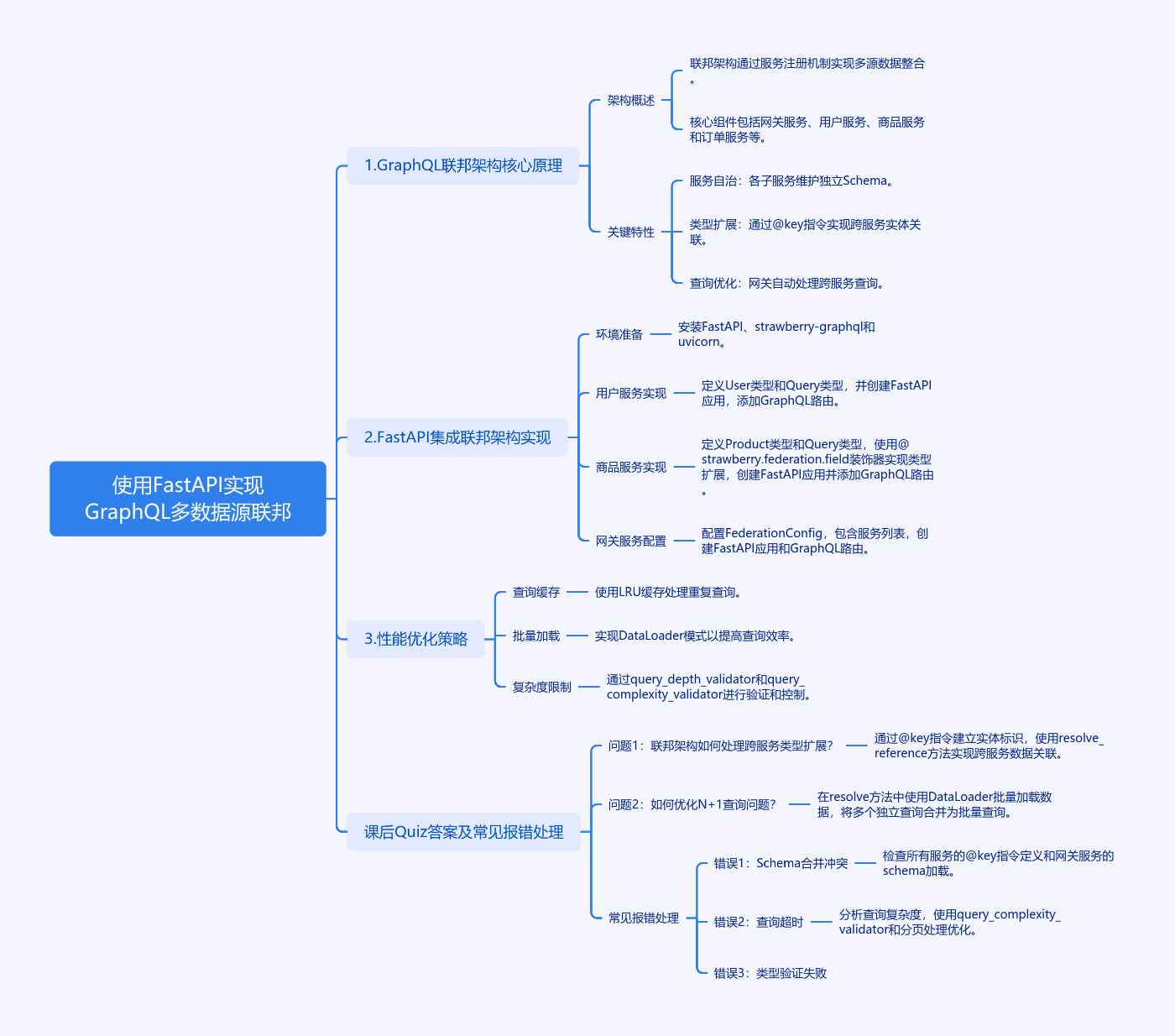
使用FastAPI实现GraphQL多数据源联邦
1. GraphQL联邦架构核心原理
联邦架构(Federation)通过服务注册机制实现多源数据整合,其核心组件包括:
Gateway[网关服务] -->|注册| ServiceA[用户服务]
Gateway -->|注册| ServiceB[商品服务]
Gateway -->|注册| ServiceC[订单服务]
Client[客户端] -->|统一查询| Gateway
Gateway -->|查询分解| ServiceA
Gateway -->|查询分解| ServiceB
Gateway -->|结果合并| Client
关键特性:
- 服务自治:各子服务维护独立Schema
- 类型扩展:通过@key指令实现跨服务实体关联
- 查询优化:网关自动处理跨服务查询
2. FastAPI集成联邦架构实现
2.1 环境准备
pip install fastapi==0.68.0
pip install strawberry-graphql==0.151.0
pip install uvicorn==0.15.0
2.2 用户服务实现
import strawberry
from fastapi import FastAPI
from strawberry.fastapi import GraphQLRouter
@strawberry.type
class User:
id: int
name: str
@strawberry.type
class Query:
@strawberry.field
def user(self, id: int) -> User:
return User(id=id, name=f"User{id}")
schema = strawberry.federation.Schema(
query=Query,
enable_federation_2=True
)
app = FastAPI()
app.add_route("/graphql", GraphQLRouter(schema))
2.3 商品服务实现
@strawberry.type
class Product:
id: int
owner: User = strawberry.federation.field(external=True)
@classmethod
def resolve_reference(cls, id: int):
return Product(id=id, owner=User(id=1))
@strawberry.type
class Query:
@strawberry.field
def product(self, id: int) -> Product:
return Product.resolve_reference(id)
schema = strawberry.federation.Schema(
query=Query,
enable_federation_2=True,
extend=[User]
)
3. 网关服务配置
from fastapi import FastAPI
from strawberry.fastapi import GraphQLRouter
from strawberry.schema.config import FederationConfig
config = FederationConfig(
service_list=[
{"name": "user", "url": "http://user-service/graphql"},
{"name": "product", "url": "http://product-service/graphql"}
]
)
schema = federated_schema(config=config)
app = FastAPI()
app.add_route("/graphql", GraphQLRouter(schema))
4. 性能优化策略
- 查询缓存:对重复查询使用LRU缓存
- 批量加载:实现DataLoader模式
- 复杂度限制:
schema = strawberry.federation.Schema(
query=Query,
validation_rules=[
query_depth_validator(max_depth=10),
query_complexity_validator(max_complexity=500)
]
)
课后Quiz
问题1:联邦架构如何处理跨服务类型扩展?
答案:通过@key指令建立实体标识,使用resolve_reference方法实现跨服务数据关联。例如用户服务定义@key(fields: "id"),商品服务通过owner字段关联用户ID。
问题2:如何优化N+1查询问题?
解决方案:在resolve方法中使用DataLoader批量加载数据,将多个独立查询合并为批量查询,减少数据库访问次数。
常见报错处理
错误1:Schema合并冲突
Error: Cannot extend type "User" because it is not defined
解决方法:
- 检查所有服务是否正确定义@key指令
- 确认网关服务正确加载所有子服务schema
错误2:查询超时
TimeoutError: Query execution exceeded 5000ms
优化步骤:
- 分析查询复杂度使用query_complexity_validator
- 添加查询深度限制query_depth_validator
- 对复杂查询实施分页处理
错误3:类型验证失败
ValidationError: Field "product" argument "id" of type "Int!" is required
处理流程:
- 检查客户端查询参数是否完整
- 验证GraphQL Schema类型定义
- 使用strawberry.Private字段处理内部类型转换
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:如何在FastAPI中玩转GraphQL联邦架构,让数据源手拉手跳探戈?
往期文章归档:
- GraphQL批量查询优化:DataLoader如何让数据库访问速度飞起来? - cmdragon's Blog
- 如何在FastAPI中整合GraphQL的复杂度与限流? - cmdragon's Blog
- GraphQL错误处理为何让你又爱又恨?FastAPI中间件能否成为你的救星? - cmdragon's Blog
- FastAPI遇上GraphQL:异步解析器如何让API性能飙升? - cmdragon's Blog
- GraphQL的N+1问题如何被DataLoader巧妙化解? - cmdragon's Blog
- FastAPI与GraphQL的完美邂逅:如何打造高效API? - cmdragon's Blog
- GraphQL类型系统如何让FastAPI开发更高效? - cmdragon's Blog
- REST和GraphQL究竟谁才是API设计的终极赢家? - cmdragon's Blog
- IoT设备的OTA升级是如何通过MQTT协议实现无缝对接的? - cmdragon's Blog
- 如何在FastAPI中玩转STOMP协议升级,让你的消息传递更高效? - cmdragon's Blog
- 如何用WebSocket打造毫秒级实时协作系统? - cmdragon's Blog
- 如何用WebSocket打造毫秒级实时协作系统? - cmdragon's Blog
- 如何让你的WebSocket连接既安全又高效?
- 如何让多客户端会话管理不再成为你的技术噩梦? - cmdragon's Blog
- 如何在FastAPI中玩转WebSocket消息处理?
- 如何在FastAPI中玩转WebSocket,让实时通信不再烦恼? - cmdragon's Blog
- WebSocket与HTTP协议究竟有何不同?FastAPI如何让长连接变得如此简单? - cmdragon's Blog
- FastAPI如何玩转安全防护,让黑客望而却步?
- 如何用三层防护体系打造坚不可摧的 API 安全堡垒? - cmdragon's Blog
- FastAPI安全加固:密钥轮换、限流策略与安全头部如何实现三重防护? - cmdragon's Blog
- 如何在FastAPI中巧妙玩转数据脱敏,让敏感信息安全无忧? - cmdragon's Blog
- RBAC权限模型如何让API访问控制既安全又灵活? - cmdragon's Blog
- FastAPI中的敏感数据如何在不泄露的情况下翩翩起舞?
- FastAPI安全认证的终极秘籍:OAuth2与JWT如何完美融合? - cmdragon's Blog
- 如何在FastAPI中打造坚不可摧的Web安全防线? - cmdragon's Blog
- 如何用 FastAPI 和 RBAC 打造坚不可摧的安全堡垒? - cmdragon's Blog
- FastAPI权限配置:你的系统真的安全吗? - cmdragon's Blog
- FastAPI权限缓存:你的性能瓶颈是否藏在这只“看不见的手”里? | cmdragon's Blog
- FastAPI日志审计:你的权限系统是否真的安全无虞? | cmdragon's Blog
- 如何在FastAPI中打造坚不可摧的安全防线? | cmdragon's Blog
- 如何在FastAPI中实现权限隔离并让用户乖乖听话? | cmdragon's Blog
- 如何在FastAPI中玩转权限控制与测试,让代码安全又优雅? | cmdragon's Blog
- 如何在FastAPI中打造一个既安全又灵活的权限管理系统? | cmdragon's Blog
- FastAPI访问令牌的权限声明与作用域管理:你的API安全真的无懈可击吗? | cmdragon's Blog
- 如何在FastAPI中构建一个既安全又灵活的多层级权限系统? | cmdragon's Blog
- FastAPI如何用角色权限让Web应用安全又灵活? | cmdragon's Blog
- FastAPI权限验证依赖项究竟藏着什么秘密? | cmdragon's Blog
免费好用的热门在线工具
- ASCII字符画生成器 - 应用商店 | By cmdragon
- JSON Web Tokens 工具 - 应用商店 | By cmdragon
- Bcrypt 密码工具 - 应用商店 | By cmdragon
- GIF 合成器 - 应用商店 | By cmdragon
- GIF 分解器 - 应用商店 | By cmdragon
- 文本隐写术 - 应用商店 | By cmdragon
- CMDragon 在线工具 - 高级AI工具箱与开发者套件 | 免费好用的在线工具
- 应用商店 - 发现1000+提升效率与开发的AI工具和实用程序 | 免费好用的在线工具
- CMDragon 更新日志 - 最新更新、功能与改进 | 免费好用的在线工具
- 支持我们 - 成为赞助者 | 免费好用的在线工具
- AI文本生成图像 - 应用商店 | 免费好用的在线工具
- 临时邮箱 - 应用商店 | 免费好用的在线工具
- 二维码解析器 - 应用商店 | 免费好用的在线工具
- 文本转思维导图 - 应用商店 | 免费好用的在线工具
- 正则表达式可视化工具 - 应用商店 | 免费好用的在线工具
- 文件隐写工具 - 应用商店 | 免费好用的在线工具
- IPTV 频道探索器 - 应用商店 | 免费好用的在线工具
- 快传 - 应用商店 | 免费好用的在线工具
- 随机抽奖工具 - 应用商店 | 免费好用的在线工具
- 动漫场景查找器 - 应用商店 | 免费好用的在线工具
- 时间工具箱 - 应用商店 | 免费好用的在线工具
- 网速测试 - 应用商店 | 免费好用的在线工具
- AI 智能抠图工具 - 应用商店 | 免费好用的在线工具
- 背景替换工具 - 应用商店 | 免费好用的在线工具
- 艺术二维码生成器 - 应用商店 | 免费好用的在线工具
- Open Graph 元标签生成器 - 应用商店 | 免费好用的在线工具
- 图像对比工具 - 应用商店 | 免费好用的在线工具
- 图片压缩专业版 - 应用商店 | 免费好用的在线工具
- 密码生成器 - 应用商店 | 免费好用的在线工具
- SVG优化器 - 应用商店 | 免费好用的在线工具
- 调色板生成器 - 应用商店 | 免费好用的在线工具
- 在线节拍器 - 应用商店 | 免费好用的在线工具
- IP归属地查询 - 应用商店 | 免费好用的在线工具
- CSS网格布局生成器 - 应用商店 | 免费好用的在线工具
- 邮箱验证工具 - 应用商店 | 免费好用的在线工具
- 书法练习字帖 - 应用商店 | 免费好用的在线工具
- 金融计算器套件 - 应用商店 | 免费好用的在线工具
- 中国亲戚关系计算器 - 应用商店 | 免费好用的在线工具
- Protocol Buffer 工具箱 - 应用商店 | 免费好用的在线工具
- IP归属地查询 - 应用商店 | 免费好用的在线工具
- 图片无损放大 - 应用商店 | 免费好用的在线工具
- 文本比较工具 - 应用商店 | 免费好用的在线工具
- IP批量查询工具 - 应用商店 | 免费好用的在线工具
- 域名查询工具 - 应用商店 | 免费好用的在线工具
- DNS工具箱 - 应用商店 | 免费好用的在线工具
- 网站图标生成器 - 应用商店 | 免费好用的在线工具
- XML Sitemap
如何在FastAPI中玩转GraphQL联邦架构,让数据源手拉手跳探戈?的更多相关文章
- 如何在 Kubernetes 集群中玩转 Fluid + JuiceFS
作者简介: 吕冬冬,云知声超算平台架构师, 负责大规模分布式机器学习平台架构设计与功能研发,负责深度学习算法应用的优化与 AI 模型加速.研究领域包括高性能计算.分布式文件存储.分布式缓存等. 朱唯唯 ...
- 我是如何在SQLServer中处理每天四亿三千万记录的
首先声明,我只是个程序员,不是专业的DBA,以下这篇文章是从一个问题的解决过程去写的,而不是一开始就给大家一个正确的结果,如果文中有不对的地方,请各位数据库大牛给予指正,以便我能够更好的处理此次业务. ...
- 【转】我是如何在SQLServer中处理每天四亿三千万记录的
原文转自:http://blog.jobbole.com/80395/ 首先声明,我只是个程序员,不是专业的DBA,以下这篇文章是从一个问题的解决过程去写的,而不是一开始就给大家一个正确的结果,如果文 ...
- 如何在SQLServer中处理每天四亿三千万记录
首先声明,我只是个程序员,不是专业的DBA,以下这篇文章是从一个问题的解决过程去写的,而不是一开始就给大家一个正确的结果,如果文中有不对的地方,请各位数据库大牛给予指正,以便我能够更好的处理此次业务. ...
- (转)我是如何在SQLServer中处理每天四亿三千万记录的
首先声明,我只是个程序员,不是专业的DBA,以下这篇文章是从一个问题的解决过程去写的,而不是一开始就给大家一个正确的结果,如果文中有不对的地方,请各位数据库大牛给予指正,以便我能够更好的处理此次业务. ...
- 如何在Unity中分别实现Flat Shading(平面着色)、Gouraud Shading(高洛德着色)、Phong Shading(冯氏着色)
写在前面: 先说一下为什么决定写这篇文章,我也是这两年开始学习3D物体的光照还有着色方式的,对这个特别感兴趣,在Wiki还有NVIDIA官网看了相关资料后,基本掌握了渲染物体时的渲染管道(The re ...
- (转)我是如何在SQLServer中处理每天四亿三千万记录的
首先声明,我只是个程序员,不是专业的DBA,以下这篇文章是从一个问题的解决过程去写的,而不是一开始就给大家一个正确的结果,如果文中有不对的地方,请各位数据库大牛给予指正,以便我能够更好的处理此次业务. ...
- 我是如何在SQLServer中处理每天四亿三千万记录的(转)
出处:http://www.cnblogs.com/marvin/p/HowCanIHandleBigDataBySQLServer.html 首先声明,我只是个程序员,不是专业的DBA,以下这篇文章 ...
- 如何在SQLServer中处理每天四亿三千万记录的(数据库大数据处理)
首先声明,我只是个程序员,不是专业的DBA,以下这篇文章是从一个问题的解决过程去写的,而不是一开始就给大家一个正确的结果,如果文中有不对的地方,请各位数据库大牛给予指正,以便我能够更好的处理此次业务. ...
- 如何在SQLServer中处理每天四亿三千万记录的
项目背景 这是给某数据中心做的一个项目,项目难度之大令人发指,这个项目真正的让我感觉到了,商场如战场,而我只是其中的一个小兵,太多的战术,太多的高层之间的较量,太多的内幕了.具体这个项目的情况,我有空 ...
随机推荐
- 后缀数组(SA)
后缀数组 P3809 [模板]后缀排序 定义: 对给定字符串的所有后缀排序后得到的sa.rk数组 sa[i]->排名为i的后缀的位置 rk[i]->位置为i的后缀的排名 容易发现,sa与r ...
- Typora中markdown文件无法识别行内公式(内联公式)
行内公式属于LaTeX扩展语法,而不属于Markdown的通用标准.为了使Typora予以解析,需要在Typora的"文件"-"偏好设置"中,勾选"内 ...
- System.Runtime.Serialization.SerializationException:“二进制流“0”不包含有效的 BinaryHeader。这可能是由于无效流,或由于在序列化和反序列化之间的对象版本更改。
var buffer = new byte[1024]; using (var ms = new MemoryStream(buffer)) { //xxx } 原因是buffer的长度过短,当接受到 ...
- QQ会员首页HTML+CSS
作为一个穷人,唯一一次逛这么久的会员首页还是因为要写最头大的web~苦涩 效果图 源码 <!DOCTYPE html> <html> <head> <meta ...
- Spring扩展接口-BeanFactoryPostProcessor
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- 从数组和List中随机抽取若干不重复的元素
一.从数组中随机抽取若干不重复元素 /** * @function:从数组中随机抽取若干不重复元素 * * @param paramArray:被抽取数组 * @param count:抽取元素的个数 ...
- 袋鼠云思枢:数驹DTengine,助力企业构建高效的流批一体数据湖计算平台
7月28日,以"数智进化,现在即未来"为主题的袋鼠云2022产品发布会于线上正式开幕.发布会上,袋鼠云宣布将集团进行全新升级:从"数字化基础设施供应商",升级为 ...
- 程序与用户交互(input、print)
程序与用户交互 [1]输入(input) (1)input 输入一些内容后,按下回车键后,input函数会返回用户输入的内容 input接受的所有数据类型都是str类型 username = inpu ...
- Nuclear - 基于流媒体的隐私优先音乐播放器
Nuclear - 基于流媒体的隐私优先音乐播放器 项目描述 Nuclear是一款专注于从免费来源流媒体播放音乐的桌面应用,具有以下核心特点: 隐私优先设计,不进行用户追踪或数据分析 无广告干扰的纯净 ...
- 利用DNSLOG测试Fastjson远程命令执行漏洞
由于内容比较简单,我直接贴图,怕我自己忘了. 测试Fastjson版本号:1.2.15 直接发送用burpsuite发送payload,将dataSourceName改成dnslog获取到的域名. p ...