Python 爬起数据时 'gbk' codec can't encode character '\xa0' 的问题

1、被这个问题折腾了一上午终于解决了,再网上看到有用 string.replace(u'\xa0',u' ') 替换成空格的,方法试了没用。
后来发现 要在open的时候加utf-8才解决问题。

以为就这样万事大吉了,运行又出现新问题了,爬去的内容是乱码,而源码是正常的,这不是怪了嘛,想想肯定是页面没用utf-8
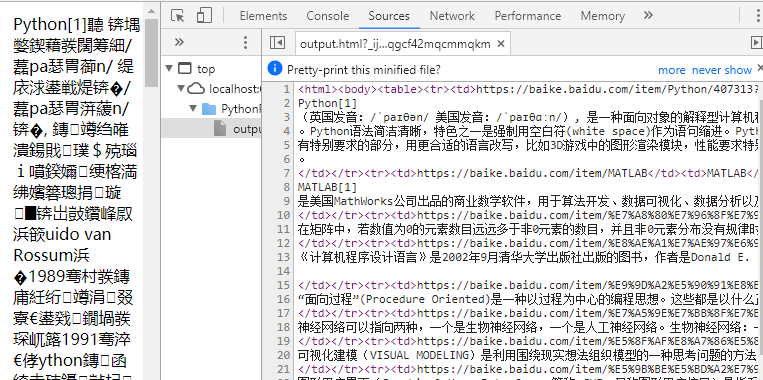
把utf-8 加上之后,问题完美解决

Python 爬起数据时 'gbk' codec can't encode character '\xa0' 的问题的更多相关文章
- Python报错:UnicodeEncodeError 'gbk' codec can't encode character
今天在使用Python文件处理写网络上爬取的文件的时候,遇到了错误:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa0’ in p ...
- UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 1987: illegal multibyte sequence
在爬取 url = "http://stats.meizhou.gov.cn/show/index/1543/1689" 时出现了问题: UnicodeEncodeError: ' ...
- 报错处理(UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 2: ill egal multibyte sequence)
参照文[https://blog.csdn.net/Dillon2015/article/details/53204955]的说法, 第一个错 [UnicodeEncodeError:'gbk' co ...
- UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 263: i llegal multibyte sequence
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 263: illegal multibyte seq ...
- day1 UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 2490: illegal multibyte sequence 错误提示
get方式得到网页的信息 #coding=utf-8 #pip install requests #直接get到网页的信息 import requests from bs4 import Beauti ...
- python3 UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 30: illegal multibyte sequence
昨天用用python3写个日志文件,结果报错UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 30: ...
- python基础===解决python3 UnicodeEncodeError: 'gbk' codec can't encode character '\xXX' in position XX(转载)
本文转自:解决python3 UnicodeEncodeError: 'gbk' codec can't encode character '\xXX' in position XX 从网上抓了一些字 ...
- UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 46:illegal multibyte sequence
一. 最近使用python写入文件时,出现了如下的错误: 但是content的内容是unicode编码,不知道怎么和gbk扯上了关系,对content使用encode()和decode(),用gbk, ...
- bs4 UnicodeEncodeError: 'gbk' codec can't encode character '\xa0'
Problem: 写爬虫时,出现了以下错误: 意思是Unicode编码错误,gbk编解码器不能编码\xa0字符. 爬取信息包含中文,使用BeautifulSoup库解析网页,用get_text()方法 ...
随机推荐
- Hadoop学习笔记之三:DataNode
DataNode对ClientDatanodeProtocol.InterDatanodeProtocol两个协议接口进行了实现,通过ipc::Server向Client.其它DN提供RPC服务(参见 ...
- 分页的模块layui
//调用分页模块 var laypage = layui.laypage; //分页的配置项 laypage.render({ elem:"page",//(指向存放分页的容器,值 ...
- Jquery部分小结
window.onload 必须等待网页中所有的内容加载完毕后(包括图片)才能执行,如果多个,只会执行最后一个;$(document).ready() 网页中所有DOM结构绘制完毕后就执行,可能DOM ...
- K8S学习笔记之修改K8S的api-server证书
K8S的api-server证书包含很多IP和域名,有时候后期才发现证书内有错误,需要重新生成该证书. 修改server-csr.json,修改后基于原来的ca证书重新生成server.perm s ...
- 让bat批处理后台运行,不显示cmd窗口(完全静化)
背景:由于我有某云的服务器(win server), 上面挂有好几个程序, 为了更好的监控他们, 我使用了一个最笨的方法, 就是下面的方法. 实现:我要监控的程序有三个, 成为ABC吧, 下面先把三个 ...
- java常用类-String类
* 字符串:就是由多个字符组成的一串数据.也可以看成是一个字符数组. * 通过查看API,我们可以知道 * A:字符串字面值"abc"也可以看成是一个字符串对象. * B:字符串是 ...
- centos6.9 svn提交更新到网站根目录
一.首先创建网站根目录 ~] # mkdir -pv /export/home/cms/www_dyrs ~] # svn co svn://127.0.0.1/svn1 /export/home/c ...
- python使用pip下载模块
举例下载串口模块pyserial: 下载安装了python之后,打开cmd,在python的安装目录里,搜索pip,把pip3.7.exe拖进cmd,然后输入pip3.7.exe install py ...
- topcoder srm 686 div1
problem1 link 左括号和右括号较少的一种不会大于20.假设左括号少.设$f[i][mask][k]$表示处理了前$i$个字符,其中留下的字符以$k$开头($k=0$表示'(',$k=1$表 ...
- Linux使用——Linux命令——CentOS7防火墙使用
注意:设置防火墙需要使用具有root权限的用户进入: CentOS 7.0默认使用的是firewall作为防火墙: CentOS 7.0使用systemctl来管理服务和程序,包括了service和c ...