原文 http://m635674608.iteye.com/blog/2360095
kubernetes中如何发现服务
如何发现pod提供的服务
如何使用kube-dns发现服务
service:服务,是一个虚拟概念,逻辑上代理后端pod。众所周知,pod生命周期短,状态不稳定,pod异常后新生成的pod ip会发生变化,之前pod的访问方式均不可达。通过service对pod做代理,service有固定的ip和port,ip:port组合自动关联后端pod,即使pod发生改变,kubernetes内部更新这组关联关系,使得service能够匹配到新的pod。这样,通过service提供的固定ip,用户再也不用关心需要访问哪个pod,以及pod是否发生改变,大大提高了服务质量。如果pod使用rc创建了多个副本,那么service就能代理多个相同的pod,通过kube-proxy,实现负载均衡
service 模版
{ "kind": "Service”,
"apiVersion": "v1”,
"metadata”:
{ "name": "my-service" },
"spec": { "selector”:
{ "app": "MyApp" },
"ports": [
{ "protocol": "TCP”,
"port": 80,
"targetPort": 9376 } ] }}
其中这个service代理了所有具有app:MyApp标签的pod,服务对外端口是80,服务ip(clusterip)在创建service的时候生成,也可以指定,这组ip:port在service的周期里保持固定。访问ip:port的流量会被重定向到后端pod的9376端口上,就是targetport指定的。
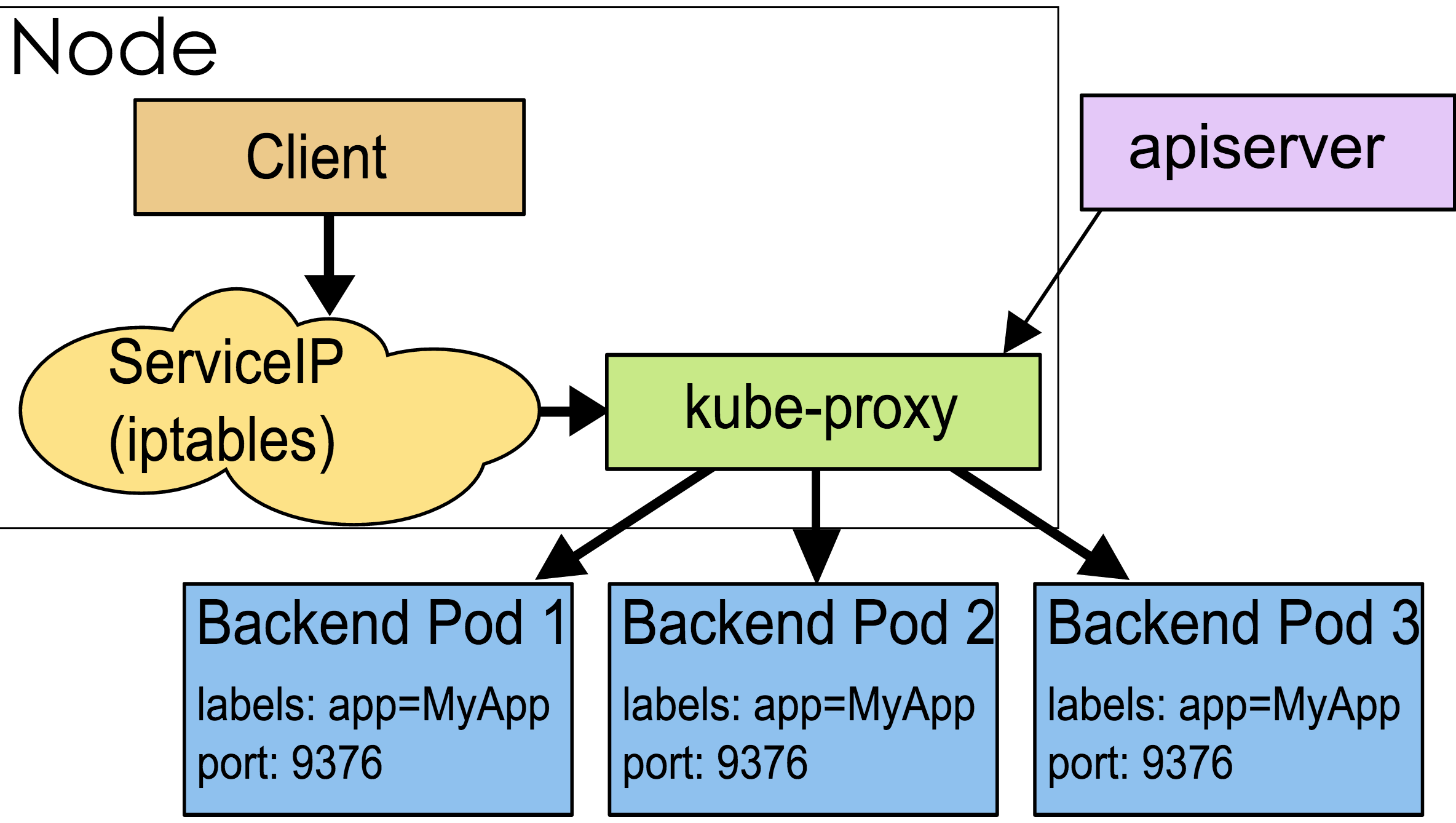
每个节点都有一个组件kube-proxy,实际上是为service服务的,通过kube-proxy,实现流量从service到pod的转发,kube-proxy也可以实现简单的负载均衡功能。
kube-proxy代理模式:userspace方式:kube-proxy 在节点上为每一个服务创建一个临时端口,service的IP:port 过来的流量转发到这个临时端口上,kube-proxy会用内部的负载均衡机制(轮询),选择一个后端pod,然后建立iptables,把流量导入这个pod里面
服务发现
服务发现在微服务架构里,服务之间经常进行通信,服务发现就是解决不同服务之间通信的问题。比如一个nginx的pod,要访问一个mysql服务,就需要知道mysql服务的ip和port,获取ip和port的过程就是服务发现。
kubernetes 支持两种服务发现模式
1.环境变量:
Pod创建的时候,服务的ip和port会以环境变量的形式注入到pod里,比如pod创建时有一个redis-master服务,服务ip地址是10.0.0.11,port是6379,则会把下面一系列环境变量注入到pod里,通过这些环境变量访问redis-master服务。 REDIS_MASTER_SERVICE_HOST=10.0.0.11REDIS_MASTER_SERVICE_PORT=6379REDIS_MASTER_PORT=tcp://10.0.0.11:6379
2.dns:
K8s集群会内置一个dns服务器,service创建成功后,会在dns服务器里导入一些记录,想要访问某个服务,通过dns服务器解析出对应的ip和port,从而实现服务访问
service 是微服务架构中的微服务。service 定义了一个服务的访问入口地址,前端的应用(pod)通过这个入口访问其背后的一组由pod副本组成的集群实例,service与其后端pod副本集群之间是通过label seletor 实现无缝对接的。而rc的功能实际上是保证servic的服务能力和服务质量处于预期的标准
通常我们的系统是由多个提供不同业务能力而又彼此独立的微服务单元所组成,服务之间通过tcp/ip进行通信,从而形成了强大而又灵活的弹性网络,拥有了强大的分布式能力,弹性扩展能力,容错能力。
nodeip:是k8s集群中每个节点的物理网卡的ip地址,是真实存在的物理地址,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个集群,这也表明集群之外的节点访问k8s集群之内的某个节点或者tcp/ip服务的时候,必须通过nodeip进行通信
podip:是每个pod的ip地址,是docker engine根据docker0网桥的ip地址段进行分配的,是一个虚拟的二层网络,k8s里面的一个pod里面的容器访问另外一个容器,就是通过podip所在的虚拟二层网络进行通信的。
每个会被分配一个单独的ip,每个pod都提供了一个独立的Endpoint( Pod ip + Container port )以被客户端访问
clusterip:全局的唯一的虚拟ip,在整个service的声明周期内,一旦创建,就不会改变
仅仅作用于service对象,由k8s管理和分配ip地址
无法被ping,没有实体网络对象来响应
必须结合service port 组成一个具体的通信端口,单独的clusterip不具备tcp/ip通信协议
在k8s内部,nodeip网、podip网和clusterip网之间的通信,采用的是k8s自己设计的一种编程方式的特殊路由规则
外部访问集群内部容器服务
外部服务对于一些前端应用,需要暴露服务给外网,而其他应用只能运行在内部。service的types字段可以指定服务类型。默认是clusterip类型,这是集群内部的服务类型,服务ip(clutserip)是一个内部ip;
外部服务类型:
1.nodeip + nodeport
为每个节点暴露一个端口,通过nodeip + nodeport可以访问这个服务,同时服务依然会有cluster类型的ip+port,内部通过clusterip方式访问,外部通过nodeport方式访问
2.loadbalance
如果k8s集群运行在第三方云平台上,比如openstack,那么可以通过外部的loadbalance来暴露服务,还能借用第三方的负载均衡机制实现负载均衡。以openstack为例,借助neutron的lbaas,访问服务的流量会被直接转发到后端的pod,跳过了内置的kube-proxy负载均衡。
cluster ip 属于k8s集群内部的地址,无法在外部使用这个地址,若要外部可以进行访问,需要进行扩展
type:NodePort
ports:
Nodeport:31002
然后nodeip + nodeport 进行访问
NodePort的实现方式是在k8s集群里的每个node上为需要外部访问的service开启一个对应的tcp监听端口,外部系统只要任意一个node的ip地址+nodeport端口即可访问服务
service如何进行服务发现
service可以将pod ip封装起来,即使pod发生重建,依然可以通过service来访问pod提供的服务,service还解决了负载均衡的问题
运行在每个node上的kube-proxy进程其实就是一个智能的软件负载均衡器,他负责把service的请求转发到后端的某个pod实例。
kube-dns可以解决Service的发现问题,k8s将Service的名称当做域名注册到kube-dns中,通过Service的名称就可以访问其提供的服务
- 从零开始入门 | Kubernetes 中的服务发现与负载均衡
作者 | 阿里巴巴技术专家 溪恒 一.需求来源 为什么需要服务发现 在 K8s 集群里面会通过 pod 去部署应用,与传统的应用部署不同,传统应用部署在给定的机器上面去部署,我们知道怎么去调用别的机 ...
- Kubernetes 中的服务发现与负载均衡
原文:https://www.infoq.cn/article/rEzx9X598W60svbli9aK (本文转载自阿里巴巴云原生微信公众号(ID:Alicloudnative)) 一.需求来源 为 ...
- kubernetes云平台管理实战: 服务发现和负载均衡(五)
一.rc控制器常用命令 1.rc控制器信息查看 [root@k8s-master ~]# kubectl get replicationcontroller NAME DESIRED CURRENT ...
- Consul + fabio 实现自动服务发现、负载均衡 - DockOne.io
Consul + fabio 实现自动服务发现.负载均衡 - DockOne.io http://dockone.io/article/1567
- 服务发现与负载均衡 dubbo zk原理
服务发现与负载均衡 拓展阅读 : dubbo 原理概念图 2016-03-03 杜亦舒 性能与架构 性能与架构 性能与架构 微信号 yogoup 功能介绍 网站性能提升与架构设计 内容整理自文章“实施 ...
- (转) Docker - Docker1.12服务发现,负载均衡和Routing Mesh
看到一篇介绍 Docker swarm以及如何编排的好文章,挪放到这里,自己学习的同时也分享出来. 原文链接: http://wwwbuild.net/dockerone/414200.html -- ...
- 【云计算】mesos+marathon 服务发现、负载均衡、监控告警方案
Mesos-dns 和 Marathon-lb 是mesosphere 官网提供的两种服务发现和负载均衡工具.官方的文档主要针对DCOS,针对其它系统的相关中文文档不多,下面是我在Centos7上的安 ...
- grpc服务发现与负载均衡
前言 在后台服务开发中,高可用性是构建中核心且重要的一环.服务发现(Service discovery)和负载均衡(Load Balance)一直都是我关注的话题.今天来谈一下我在实际中是如何理解及落 ...
- marathon的高可用服务自动发现和负载均衡
上一篇我们说谈了docker+zookeeper+mesos+marathon集群,本篇我们来谈谈marathon的集群和自动发现服务. marathon的服务自动发现和负载均衡有两种,1是mesos ...
随机推荐
- oracle 数据库相关名词--图解
通过下图,我们可以更好的理解oracle的结构关系. 知识拓展: 知识点及常用的命令如下: 1)通常情况我们称的“数据库”,并不仅指物理的数据集合,他包含物理数据.数据库管理系统.也即物理数据.内存 ...
- Spring 注解bean默认名称规则
在使用@Component.@Repository.@Service.@Controller等注解创建bean时,如果不指定bean名称,bean名称的默认规则是类名的首字母小写,如SysConfig ...
- Go Example--闭包
package main import "fmt" func main() { //这里需要将闭包函数当作一个类理解,这里是实例化 nextInt := intSeq() fmt. ...
- BZOJ1494 [NOI2007]生成树计数
题意 F.A.Qs Home Discuss ProblemSet Status Ranklist Contest 入门OJ ModifyUser autoint Logout 捐赠本站 Probl ...
- 收集的dubbo博客
1.http://shiyanjun.cn/archives/category/opensource/dubbo 2.https://blog.csdn.net/hellozpc/article/de ...
- Scala中的Map使用例子
Map结构是一种非常常见的结构,在各种程序语言都有对应的api,由于Spark的底层语言是Scala,所以有必要来了解下Scala中的Map使用方法. (1)不可变Map特点: api不太丰富 如果是 ...
- mongo之 ReadConcern 与 Read Preference
一.读取关注(readConcern) 官方文档 3.2版本以后支持读取关注 读取关注允许您控制从副本集和副本集分片读取的数据的实时性,一致性和隔离性. 通过有效使用写入关注和读取关注,可以适当调整一 ...
- Percona XtraDB Cluster 的一些使用限制(PXC 5.7)
Percona XtraDB Cluster有众多的优秀特性,使得mysql集群得以轻松实现.但是不要忽略了它的一些限制.如果你无法接受,或者你的应用程序或数据库(比如使用了memory引擎)对限制无 ...
- 单节点 Elasticsearch 出现 unassigned shards 原因及解决办法
根本原因: 是因为集群存在没有启用的副本分片,我们先来看一下官网给出的副本分片的介绍: 副本分片的主要目的就是为了故障转移,正如在 集群内的原理 中讨论的:如果持有主分片的节点挂掉了,一个副本分片就会 ...
- python2核心类库:urllib、urllib2的区别和使用
urllib/urllib2都是接受URL请求的相关模块区别:1.urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL.这意味着,你不可以伪装 ...