卓越的目标检测器Pelee
Densenet的改良—PeleeNET
Pelee: A Real-Time Object Detection System on Mobile Devices
论文地址:https://arxiv.org/abs/1804.06882
Peleenet专注于优化小型网络,针对densenet的结构做出了改良,达到了目前最先进的水准。在已有的在移动设备上执行的深度学习模型例如 MobileNet、 ShuffleNet 等都严重依赖于在深度上可分离的卷积运算,而缺乏有效的实现。在本文中,来自加拿大西安大略大学的研究者提出了称为 PeleeNet 的有效架构,它没有使用传统的卷积来实现。PeleeNet 实现了比目前最先进的 MobileNet 更高的图像分类准确率,并降低了计算成本。研究者进一步开发了实时目标检测系统 Pelee,以更低的成本超越了 YOLOv2 的目标检测性能,并能流畅地在 iPhone6s、iPhone8 上运行。
PeleeNET是DenseNet (Huang et al. (2016a)) 的一个变体。专门用于移动设备。PeleeNet 遵循 DenseNet 的创新连接模式和一些关键设计原则。它也被设计来满足严格的内存和计算预算。在 Stanford Dogs (Khosla et al.(2011)) 数据集上的实验结果表明:PeleeNet 的准确率要比 DenseNet 的原始结构高 5.05%,比 MobileNet (Howard et al. (2017)) 高 6.53%。PeleeNet 在 ImageNet ILSVRC 2012 (Deng et al. (2009)) 上也有极具竞争力的
结果。PeleeNet 的 top-1 准确率要比 MobileNet 高 0.6%。需要指出的是,PeleeNet 的模型大小是 MobileNet 的 66%。
PeleeNET的主题架构如下:
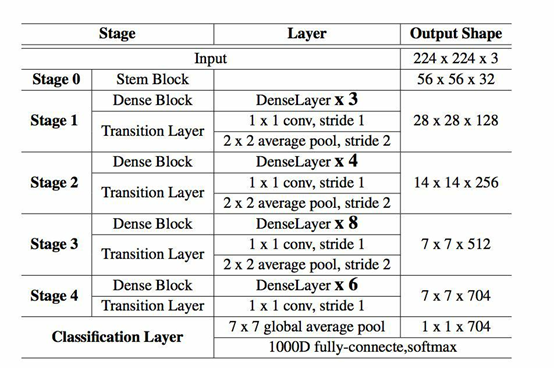
在输出的部分,对接了一个stem block 然后接了改良版的dense block 获取图像的特征。接着用transition layer来进行将维。在经过这些一系列的特征提取之后,使用全局平均池化接全连阶层分类。
下面来讲解每个部分:
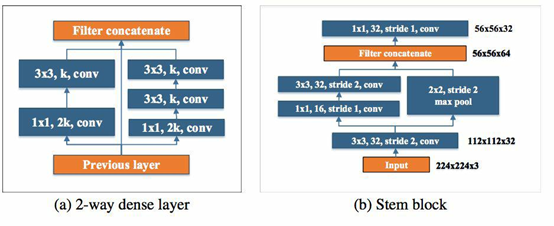
stem block由图中结构组成。受到inceptionV4的启发,作者设计了更有效率的stem block 如图(b)所示,这个模块可以有效的提升模型的特征表达能力。而不会添加特别多的额外计算量,比其他的扩张模型表现更好。比如提升第一层卷积层的通道数,或提升增长率。
两路稠密层:受 GoogLeNet (Szegedy et al. (2015)) 的两路稠密层的激发,研究者使用了一个两路密集层来得到不同尺度的感受野。其中一路使用一个 3×3 的较小卷积核,它能够较好地捕捉小尺度的目标。另一路使用两个 3×3 的卷积核来学习大尺度目标的视觉特征。该结构如图(a) 所示。K是卷积核的数量。瓶颈层通道的动态数量:另一个亮点就是瓶颈层通道数目会随着输入维度的变化而变化,以保证输出通道的数目不会超过输出通道。与原始的 DenseNet 结构相比,实验表明这种方法在节省 28.5% 的计算资源的同时仅仅会对准确率有很小的影响。
没有压缩的转换层:实验表明,DenseNet 提出的压缩因子会损坏特征表达,PeleeNet 在转换层中也维持了与输入通道相同的输出通道数目。复合函数:为了提升实际的速度,采用后激活的传统智慧(Convolution - Batch Normalization (Ioffe & Szegedy (2015)) -
Relu))作为我们的复合函数,而不是 DenseNet 中所用的预激活。对于后激活而言,所有的批正则化层可以在推理阶段与卷积层相结合,这可以很好地加快速度。为了补偿这种变化给准确率带来的不良影响,研究者使用一个浅层的、较宽的网络结构。在最后一个密集块之后还增加了一个 1×1 的卷积层,以得到更强的表征能力。
作者使用自己的PeleeNet作为前端,后接Single
Shot MultiBox Detector,SSD)的后端组合而成的pelee在 PASCAL VOC (Everingham et al. (2010))
2007 数据集上达到了 76.4% 的准确率,在 COCO 数据集上达到了 22.4% 的准确率。在准确率、速度和模型大小方面,Pelee 系统都优于YOLOv2 (Redmon & Farhadi (2016))。为了平衡速度和准确率所做的增强设置如下。
SSD论文讲解如下:https://www.cnblogs.com/ansang/p/9361631.html
特征图选择:以不同于原始 SSD 的方式构建目标检测网络,原始 SSD 仔细地选择了 5 个尺度的特征图 (19 x 19、10
x 10、5 x 5、3 x 3、1 x 1)。为了减少计算成本,没有使用 38×38 的特征图。在pelee上面,作者使用残差预测块进行预测:遵循 Lee 等人提出的设计思想(2017),即:使特征沿着特征提取网络传递。对于每一个用于检测的特征图,在实施预测之前构建了一个残差 (He et al.(2016)) 块(ResBlock)。ResBlock 的结构如图 2 所示:
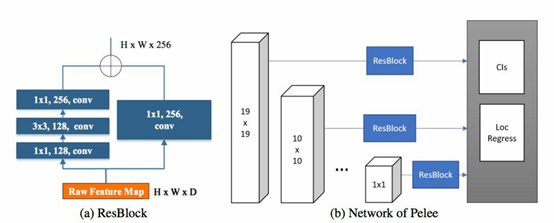
1x1 的核将计算成本减少了 21.5%。
用于预测的小型卷积核:残差预测块让我们应用 1×1 的卷积核来预测类别分数和边界框设置成为可能。实验表明:使用 1×1 卷积核的模型的准确率和使用 3×3 的卷积核所达到的准确率几乎相同。研究者在 iOS 上提供了 SSD 算法的实现。他们已经成功地将 SSD 移植到了 iOS 上,并且提供了优化的代码实现。该系统在 iPhone 6s 上以 17.1 FPS 的速度运行,在 iPhone8 上以 23.6 FPS的速度运行。在 iPhone 6s(2015 年发布的手机)上的速度要比在 Intel i7-6700K@4.00GHz CPU 上的官方算法实现还要快 2.6 倍。
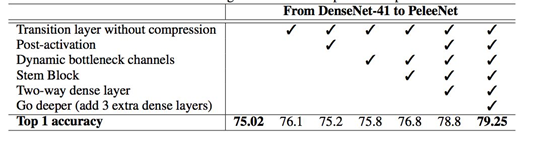
表 1:不同的设计选择的效果得到的性能
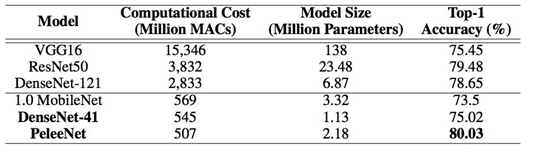
表 2:在
Stanford Dogs 数据集上的结果。MACs:乘法累加的次数,用于度量融合乘法和加法运算次数
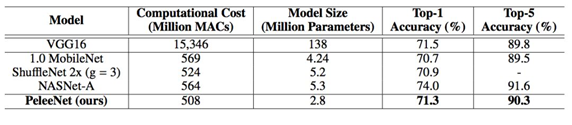
表 3:在 ImageNet ILSVRC 2012 数据集上的结果
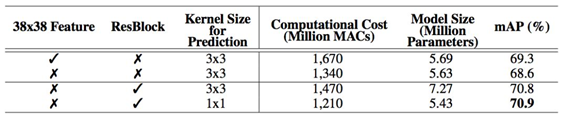
表 4:不同设计选择上的性能结果
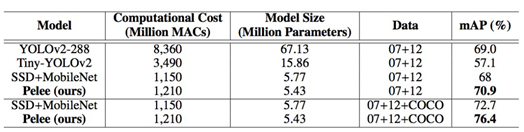
表 5:在 PASCAL VOC 2007 数据集上的结果。数据:07+12,VOC2007
和
VOC2012 联合训练;07+12+COCO,先在
COOC 数据集上训练
35000 次,然后在
07+12 上继续微调。
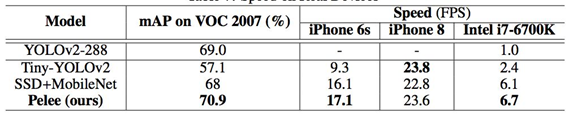
表6:实际设备上的速度

表 7: COCO test-dev2015 数据集上的结果
卓越的目标检测器Pelee的更多相关文章
- 单次目标检测器-YOLO简介
YOLO 在卷积层之后使用了 DarkNet 来做特征检测. 然而,它并没有使用多尺度特征图来做独立的检测.相反,它将特征图部分平滑化,并将其和另一个较低分辨率的特征图拼接.例如,YOLO 将一个 2 ...
- 单次目标检测器-SSD简介
SSD 是使用 VGG19 网络作为特征提取器(和 Faster R-CNN 中使用的 CNN 一样)的单次检测器.我们在该网络之后添加自定义卷积层(蓝色),并使用卷积核(绿色)执行预测. 同时对类别 ...
- SSD-Tensorflow: 3 步运行 TensorFlow 单图片多盒目标检测器
昨天类似的 YOLO: https://www.v2ex.com/t/392671#reply0 下载这个项目 https://github.com/balancap/SSD-Tensorflow 解 ...
- CVPR2020:三维实例分割与目标检测
CVPR2020:三维实例分割与目标检测 Joint 3D Instance Segmentation and Object Detection for Autonomous Driving 论文地址 ...
- KCF目标跟踪方法分析与总结
KCF目标跟踪方法分析与总结 correlation filter Kernelized correlation filter tracking 读"J. F. Henriques, R. ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 【深度学习】目标检测算法总结(R-CNN、Fast R-CNN、Faster R-CNN、FPN、YOLO、SSD、RetinaNet)
目标检测是很多计算机视觉任务的基础,不论我们需要实现图像与文字的交互还是需要识别精细类别,它都提供了可靠的信息.本文对目标检测进行了整体回顾,第一部分从RCNN开始介绍基于候选区域的目标检测器,包括F ...
- 10分钟学会使用YOLO及Opencv实现目标检测(下)|附源码
将YOLO应用于视频流对象检测 首先打开 yolo_video.py文件并插入以下代码: # import the necessary packages import numpy as np impo ...
- 一文带你学会使用YOLO及Opencv完成图像及视频流目标检测(上)|附源码
计算机视觉领域中,目标检测一直是工业应用上比较热门且成熟的应用领域,比如人脸识别.行人检测等,国内的旷视科技.商汤科技等公司在该领域占据行业领先地位.相对于图像分类任务而言,目标检测会更加复杂一些,不 ...
随机推荐
- MATLAB:图像减法运算(imsubtract函数)
图像减法运行涉及到imsubtract函数 实现代码如下: clear all; %关闭当前所有图形窗口,清空工作空间变量,清除工作空间所有变量 clc close all; A=imread('ca ...
- linux 空间释放,mysql数据库空间释放
测试告急,服务器不行了.down了…… 1.linux如何查看磁盘剩余空间: [root@XXX~]# df -lhFilesystem Size Used Avai ...
- mui dtpicker 时间的设置 以及MUI的弹窗
1)引入mui.min.css,然后引入mui.picker.min.css 注意这个mui.picker.min.css 与 mui.picker.css 不一样 2)引入 ...
- CentOS6.7下Ansible部署
Ansible是一种集成IT系统的配置管理, 应用部署, 执行特定任务的开源平台. 它基于Python语言实现, 部署只需在主控端部署Ansible环境, 被控端无需安装代理工具, 只需打开SSH, ...
- ElasticSearch文档操作介绍三
ElasticSearch文档的操作 文档存储位置的计算公式: shard = hash(routing) % number_of_primary_shards 上面公式中,routing 是一个可变 ...
- Scala进阶之路-Spark底层通信小案例
Scala进阶之路-Spark底层通信小案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark Master和worker通信过程简介 1>.Worker会向ma ...
- 微信接口开发之高级篇系列【微信JS-SDK】
PHP微信公众平台开发高级篇—微信JS-SDK 第一步.绑定域名: 第二步.引入JS文件: 第三部.通过Config接口注入权限验证配置 第四部.通过Read接口处理成功验证 第五部.通过Error接 ...
- 使用 Parallel LINQ 进行数据分页
a) 第一种[耗时11~18s],这种查询方式并不是很优化,但是目前也没有想到更好的方式,除了创建一张中间表,是不是可以使用[全文索引]? SELECT * FROM ( SELECT ROW_ ...
- json 不能 dumps datetime 解决办法
backend.myviews.json_time.py from datetime import date import json from datetime import datetime cla ...
- python技巧 switch case语句
不同于C语言和SHELL,python中没有switch case语句,关于为什么没有,官方的解释是这样的 使用Python模拟实现的方法: def switch_if(fun, x, y): ...