Python3+pdfminer+jieba+wordcloud+matplotlib生成词云(以深圳十三五规划纲要为例)
一、各库功能说明
pdfminer----用于读取pdf文件的内容,python3安装pdfminer3k
jieba----用于中文分词
wordcloud----用于生成词云
matplotlib----用于将词云可视化
这几个库的顺序也对应程序的顺序:
生使用pdfminer读取pdf文件的内容,然后使用jieba对内容进行中文分词,再然后使用wordcloud基于分词生成词云,最后使用matplotlib将词云可视化
二、程序源码
from urllib.request import urlopen
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import process_pdf, PDFResourceManager
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from io import StringIO class MyWordCloud():
def __init__(self):
pass #此函数用于读取和返回pdf文件的内容
def getPdfText(self,pdf_url):
pdf_file_obj = urlopen(pdf_url) pdf_rm = PDFResourceManager()
ret_str = StringIO()
lap = LAParams()
tc = TextConverter(pdf_rm, ret_str, laparams=lap) process_pdf(pdf_rm, tc, pdf_file_obj)
tc.close()
pdf_text = ret_str.getvalue()
ret_str.close()
return pdf_text def genWordCloud(self,pdf_url):
pdf_text = self.getPdfText(pdf_url) # WordCloud(按英文习惯)以空格分词,中文不用空格所以WordCloud不能正确对中文进行分词
# 为了使用WordCloud我们就需要先自己自己想办法完成分词,并将所有分词以空格隔开
# 我们的方法是先用结巴生成中文序列,然后使用join方法使用空格拼接所有序列
jieba_cut_seq = jieba.cut(pdf_text)
pdf_cut_text = " ".join(jieba_cut_seq) # 默认字体不支中文,需要指定要使用的中文字体路径;可从自己电脑已安装的字体中选,目录C:\Windows\Fonts
font_path = "C:\\Windows\\Fonts\\simfang.ttf"
wc = WordCloud(font_path,width=1000, height=880).generate(pdf_cut_text) plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show() def __del__(self):
pass if __name__ == '__main__':
# 深圳十三五规划纲要文件的URL链接,要生成其他pdf文件的词云修改成该文件的URL即可
pdf_url = 'http://www.sz.gov.cn/fzggj/home/zwgk/ghjh/fzgh/201604/P020160412518770846515.pdf'
mwc = MyWordCloud()
mwc.genWordCloud(pdf_url)
运行程序,生成词云如下:
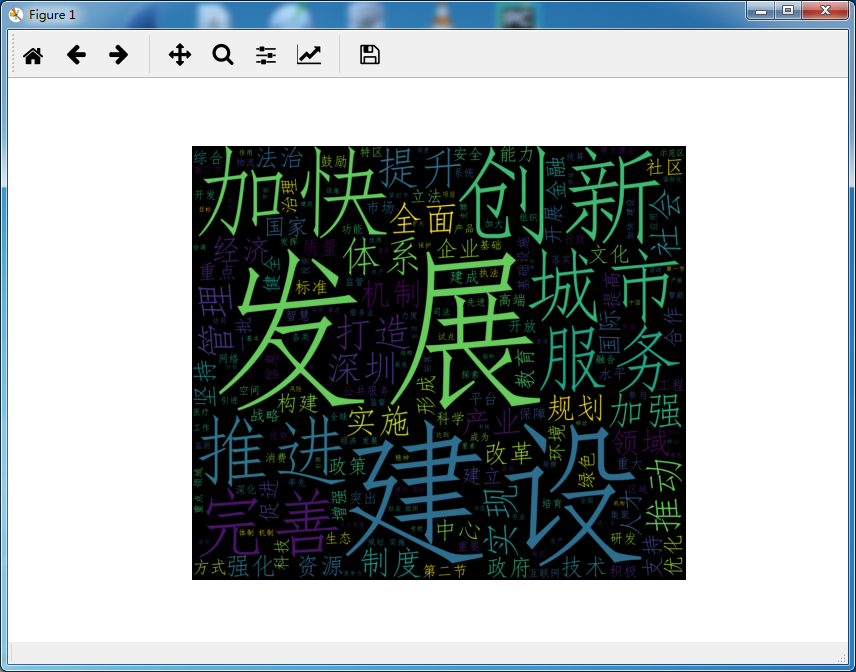
参考:
https://www.cnblogs.com/gooseeker/p/5527519.html
http://www.unixuser.org/~euske/python/pdfminer/programming.html
https://www.cnblogs.com/delav/p/7845539.html
Python3+pdfminer+jieba+wordcloud+matplotlib生成词云(以深圳十三五规划纲要为例)的更多相关文章
- python 基于 wordcloud + jieba + matplotlib 生成词云
词云 词云是啥?词云突出一个数据可视化,酷炫.以前以为很复杂,不想python已经有成熟的工具来做词云.而我们要做的就是准备关键词数据,挑一款字体,挑一张模板图片,非常非常无脑.准备好了吗,快跟我一起 ...
- 爬虫之使用requests爬取某条标签并生成词云
一.爬虫前准备 1.工具:pychram(python3.7) 2.库:random,requests,fake-useragent,json,re,bs4,matplotlib,worldcloud ...
- wordcloud + jieba 生成词云
利用jieba库和wordcloud生成中文词云. jieba库:中文分词第三方库 分词原理: 利用中文词库,确定汉字之间的关联概率,关联概率大的生成词组 三种分词模式: 1.精确模式:把文本精确的切 ...
- 【python3】爬取简书评论生成词云
一.起因: 昨天在简书上看到这么一篇文章<中国的父母,大都有毛病>,看完之后个人是比较认同作者的观点. 不过,翻了下评论,发现评论区争议颇大,基本两极化.好奇,想看看整体的评论是个什么样, ...
- 已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小. 写在前面: 用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述. 但是对于根据generate_from_f ...
- 作业练习P194,jieba应用,读取,分词,存储,生成词云,排序,保存
import jieba #第一题 txt='Python是最有意思的编程语言' words=jieba.lcut(txt) #精确分词 words_all=jieba.lcut(txt,cut_al ...
- 根据词频生成词云(Python wordcloud实现)
网上大多数词云的代码都是基于原始文本生成,这里写一个根据词频生成词云的小例子,都是基于现成的函数. 另外有个在线制作词云的网站也很不错,推荐使用:WordArt 安装词云与画图包 pip3 insta ...
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- Python统计excel表格中文本的词频,生成词云图片
import xlrd import jieba import pymysql import matplotlib.pylab as plt from wordcloud import WordClo ...
随机推荐
- SpringLog4j日志体系实现方式
1.通过web.xml读取log4j配置文件内容 2.通过不同的配置信息,来实现不同的业务输出,注意:log4j可以写入tomcat容器,也可以写入缓存,通过第三方平台读取 #输入规则#log4j.r ...
- burp suite 的intruder 四种攻击方式
一:sniper[狙击手] 这种攻击基于原始的请求内容,需要一个字典,每次用字典里的一个值去代替一个待攻击的原始值. 攻击次数=参数个数X字典内元素个数 例如:原始请求中 name=aa , pass ...
- 在JAVA中返回类型使用泛型T和Object有什么区别?
最近在读jackson源码的时候发现有段代码返回类型写的是<T> T,而我自己一般写的是Object.上网搜了下这个语法糖,在stackoverflow上找到一个比较简单易懂的解释,搬运过 ...
- python (协程)生产者,消费者
#coding=utf- import gevent from gevent.queue import Queue, Empty import time tasks = Queue(maxsize=) ...
- 给大一新生学习c程序的一些建议的一些建议
这是一篇给刚学习c程序的学弟们的一篇日志.如果想学好c程序,以及不想走太多弯路,希望能看一下这篇文章,如果说基础较好,或者说已经是大二,大三,这篇文章不会有什么帮助. 刚转到软件工程系,加了几个新生群 ...
- C#连接数据库open函数失败
错误信息:在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误.未找到或无法访问服务器.请验证实例名称是否正确并且 SQL Server 已配置为允许远程连接. (provider ...
- Grunt、Gulp区别 webpack、 requirejs区别
1. 书写方式 grunt 运用配置的思想来写打包脚本,一切皆配置,所以会出现比较多的配置项,诸如option,src,dest等等.而且不同的插件可能会有自己扩展字段,导致认知成本的提高,运用的时候 ...
- EditText取消焦点
EditText取消焦点: 在父容器添加: android:focusable="true" android:focusableInTouchMode="true&quo ...
- R语言多层绘图
#########################################################第一种实现方法close.screen(all.screens = T)split.s ...
- 力扣(LeetCode) 217. 存在重复元素
给定一个整数数组,判断是否存在重复元素. 如果任何值在数组中出现至少两次,函数返回 true.如果数组中每个元素都不相同,则返回 false. 示例 1: 输入: [1,2,3,1] 输出: true ...