实验六:分析Linux内核创建一个新进程的过程
原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
题目自拟,内容围绕对Linux系统如何创建一个新进程进行;
可以结合实验截图、绘制堆栈状态执行流程图等;
博客内容中需要仔细分析新进程的执行起点及对应的堆栈状态等。
总结部分需要阐明自己对“Linux系统创建一个新进程”的理解
上课提问:
1.进程由哪些部分构成?
pid,state,task_struct,
用户堆栈,内核堆栈,地址空间,代码段,数据段
2.进程是如何被创建?
0号进程手工创建
其他进程调用do_frok
3.新创建的进程从哪里开始执行?
ret_from_fork
实验报告:
阅读理解task_struct数据结构http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235;
- state:运行状态
- stack:内核堆栈
- tasks:进程链表
- mm:内存管理
- task_state:任务的状态
- pid:进程PID
- real_parent children:进程的父子关系
- files:文件描述符列表
- signal:信号处理相关
- splice_pipe:管道相关
分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构;
- fork、vfork和clone三个系统调用都可以创建一个新进程,都是通过调用do_fork来实现进程的创建
- 创建新进程需要先复制一个PCB:task_struct
- 再给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈 - 再修改复制过来的进程数据,比如pid、进程链表等等,见copy_process内部
- 从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次
1 *childregs = *current_pt_regs(); //复制内核堆栈
2 childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因!
3
4 p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
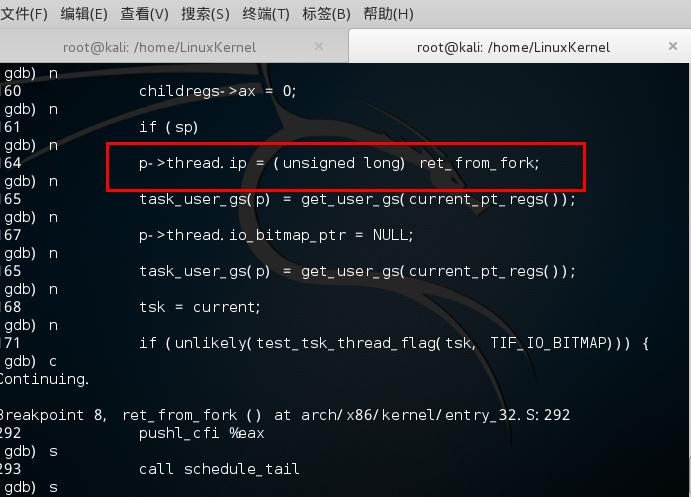
5 p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址 do_fork完成了创建中的大部分工作,该函数调用copy_process()函数,然后让进程开始运行。copy_process()函数工作如下:
- 1、调用dup_task_struct()为新进程创建一个内核栈、thread_info结构和task_struct,这些值与当前进程的值相同
- 2、检查
- 3、子进程着手使自己与父进程区别开来。进程描述符内的许多成员被清0或设为初始值。
- 4、子进程状态被设为TASK_UNINTERRUPTIBLE,以保证它不会投入运行
- 5、copy_process()调用copy_flags()以更新task_struct的flags成员。表明进程是否拥有超级用户权限的PF_SUPERPRIV标志被清0。表明进程还没有调用exec()函数的PF_FORKNOEXEC标志被设置
- 6、调用alloc_pid()为新进程分配一个有效的PID
- 7、根据传递给clone()的参数标志,copy_process()拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等
- 8、最后,copy_process()做扫尾工作并返回一个指向子进程的指针
使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone ,验证您对Linux系统创建一个新进程的理解
- 下断点的函数:sys_clone do_fork dup_task_struct copy_process copy_thread ret_from_fork
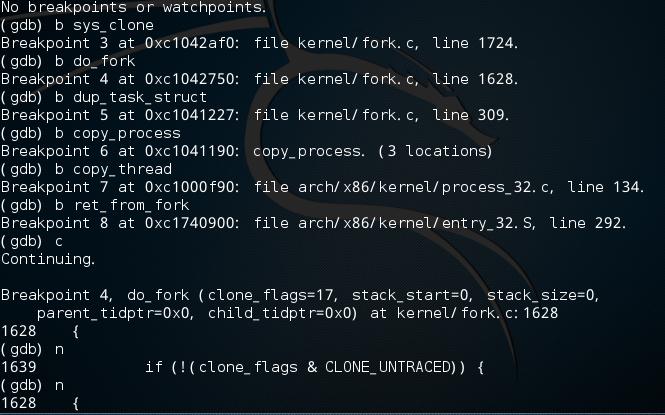




- dup_task_struct()为新进程创建一个内核栈
copy_process()主要完成进程数据结构,各种资源的初始化
- 下断点的函数:sys_clone do_fork dup_task_struct copy_process copy_thread ret_from_fork
特别关注新进程是从哪里开始执行的?为什么从哪里能顺利执行下去?即执行起点与内核堆栈如何保证一致。
ret_from_fork;决定了新进程的第一条指令地址- copy_thread()函数中的语句
p->thread.ip = (unsigned long) ret_from_fork;决定了新进程的第一条指令地址 - 在ret_from_fork之前,也就是在copy_thread()函数中
*childregs = *current_pt_regs();该句将父进程的regs参数赋值到子进程的内核堆栈 - *childregs的类型为pt_regs,里面存放了SAVE ALL中压入栈的参数 故在之后的RESTORE ALL中能顺利执行下去
实验六:分析Linux内核创建一个新进程的过程的更多相关文章
- 第六周分析Linux内核创建一个新进程的过程
潘恒 原创作品转载请注明出处<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 task_struct结构: ...
- 20135202闫佳歆--week6 分析Linux内核创建一个新进程的过程——实验及总结
week 6 实验:分析Linux内核创建一个新进程的过程 1.使用gdb跟踪创建新进程的过程 准备工作: rm menu -rf git clone https://github.com/mengn ...
- linux内核分析作业6:分析Linux内核创建一个新进程的过程
task_struct结构: struct task_struct { volatile long state;进程状态 void *stack; 堆栈 pid_t pid; 进程标识符 u ...
- 实验 六:分析linux内核创建一个新进程的过程
实验六:分析Linux内核创建一个新进程的过程 作者:王朝宪 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029 ...
- Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
Linux内核分析第六周学习笔记--分析Linux内核创建一个新进程的过程 zl + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/U ...
- 作业六:分析Linux内核创建一个新进程的过程
分析Linux内核创建一个新进程的过程 进程描述符PCB----task_struct数据结构 操作系统:1.进程管理 2.内存管理 3 文件系统 一.新进程如何创建和修改task_struct数据结 ...
- 《Linux内核--分析Linux内核创建一个新进程的过程 》 20135311傅冬菁
20135311傅冬菁 分析Linux内核创建一个新进程的过程 一.学习内容 进程控制块——PCB task_struct数据结构 PCB task_struct中包含: 进程状态.进程打开的文件. ...
- Linux内核分析-分析Linux内核创建一个新进程的过程
作者:江军 ID:fuchen1994 实验题目:分析Linux内核创建一个新进程的过程 阅读理解task_struct数据结构http://codelab.shiyanlou.com/xref/li ...
- 第六周——分析Linux内核创建一个新进程的过程
"万子恵 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 &q ...
随机推荐
- poj 3608 旋转卡壳求不相交凸包最近距离;
题目链接:http://poj.org/problem?id=3608 #include<cstdio> #include<cstring> #include<cmath ...
- poj 3084 最小割
题目链接:http://poj.org/problem?id=3084 本题主要在构图上,我采用的是把要保护的房间与源点相连,有intruder的与汇点相连,相对麻烦. #include <cs ...
- Selenium webdriver 操作chrome 浏览器
Step1: 下载chromedriver. 下载路径: http://chromedriver.storage.googleapis.com/index.html 选择一个合适的下载即可.我下载的是 ...
- 菜鸟成长日记之新手备忘录-IOS开发第一个项目总结
2013年5月3号,开始找IOS开发工作(自学了大半年,做了一个功能不全的Demo,该出去见见世面了!),5月4号面试了第一家公司(是家刚成立一段时间的外包公司),5月5号第一家公司已二轮电话面试,5 ...
- 【java基础】--(3)javaIO详细阐释
1.总的4类 字符:Reader 和Writer 字节:InputStream和OutputStream 2.Reader 六个子类BufferedReader, CharArrayReader, F ...
- Excel导入数据库(三)——SqlBulkCopy
上篇博客中介绍了批量导入数据库的方法:下面介绍一下批量导入过程的核心——SqlBulkCopy类. 下面先介绍一些原理性的东西:SQLBulkCopy类,通常用于数据库之间大批量的数据传递.即使表结构 ...
- 【iOS】3D Touch
文章内容来源于Apple的开发者文档:https://developer.apple.com/library/content/documentation/UserExperience/Conceptu ...
- Android(java)学习笔记228:服务(service)之绑定服务调用服务里面的方法
1.绑定服务调用服务里面的方法,图解: 步骤: (1)在Activity代码里面绑定 bindService(),以bind的方式开启服务 : bindServ ...
- fluentd结合kibana、elasticsearch实时搜索分析hadoop集群日志<转>
转自 http://blog.csdn.net/jiedushi/article/details/12003171 Fluentd是一个开源收集事件和日志系统,它目前提供150+扩展插件让你存储大数据 ...
- 关于git的一些常用命令
1.git init 把目录变成Git可以管理的仓库 2.git add 把文件添加到仓库 3.git commit -m "" 把文件提交到仓库,-m后面是提交说明 4.git ...