RCFile在平台的应用场景中多数用于存储需要“长期留存”的数据文件,在我们的实践过程中,RCFile的数据压缩比通常可以达到8 : 1或者10 : 1,特别适用于存储用户通过Hive(MapReduce)分析的结果。目前平台的计算引擎正逐步由Hadoop MapReduce迁移至Spark,存储方面我们依然想利用RCFile的优势,但是具体实践中遇到那么几个“坑”。
数据分析师使用PySpark构建Spark分析程序,源数据是按行存储的文本文件(可能有压缩),结果数据为Python list,list的元素类型为tuple,而tuple的元素类型为unicode(Python2,为了保持大家对数据认知的一致性,源数据是文本,我们要求用户的处理结果也为文本),可以看出list实际可以理解为一张表(Table),list的元素tuple为行(Row),tuple的元素为列(Column),因此能够很好的利用RCFile的列式存储特性。
RCFile扩展自Hadoop InputFormat、OutputFormat、Writable:
org.apache.hadoop.hive.ql.io.RCFileInputFormat
org.apache.hadoop.hive.ql.io.RCFileOutputFormat
org.apache.hadoop.hive.serde2.columnar.BytesRefArrayWritable
注意:RCFile的使用需要依赖于Hive的Jar。
使用RCFileOutputFormat时我们需要处理tuple => BytesRefArrayWritable(Object[] => BytesRefArrayWritable)的数据类型转换,使用RCFileInputFormat时我们需要处理BytesRefArrayWritable => tuple(BytesRefArrayWritable => Object[])的数据类型转换,也就是说我们需要扩展两个Converter:
ObjectArrayToBytesRefArrayWritableConverter:用于Object[] => BytesRefArrayWritable的数据类型转换;
BytesRefArrayWritableToObjectArrayConverter:用于BytesRefArrayWritable => Object[]的数据类型转换;
(1)ObjectArrayToBytesRefArrayWritableConverter;
convert的参数类型为Object[],返回值类型为BytesRefArrayWritable。
(2)BytesRefArrayWritableToObjectArrayConverter;
convert的参数类型为BytesRefArrayWritable,返回值类型为Object[]。
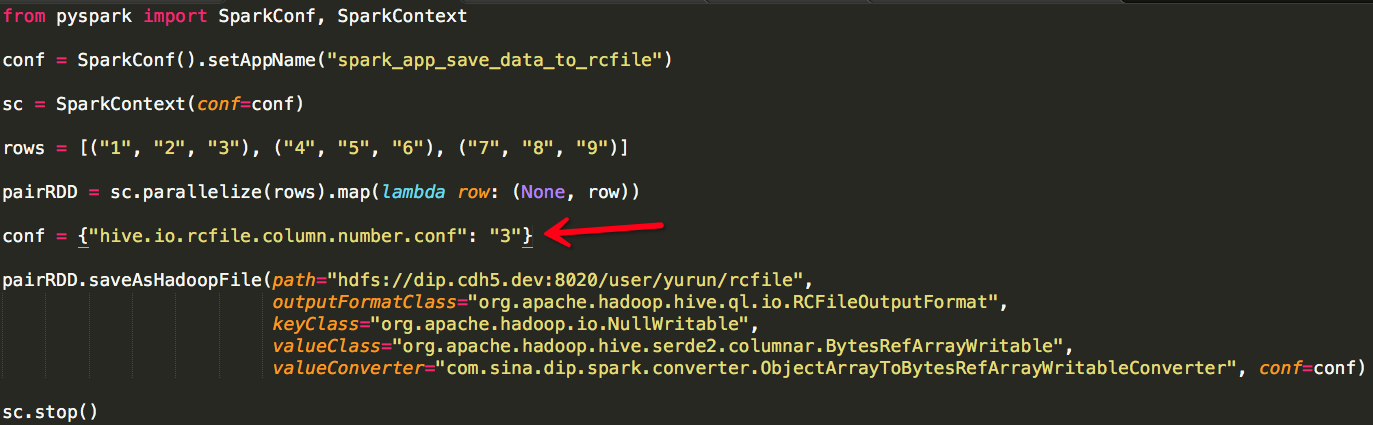
1. 模拟数据(用户分析结果),将其以RCFile的形式保存至HDFS;
我们模拟的数据为三行三列,数据类型均为文本,需要注意的是RCFile在保存数据时需要通过Hadoop Configuration指定“列数”,否则会出现以下异常:
此外RCFileOutputFormat RecordWriter会丢弃“key”:
因此“key”可以是任意值,只要兼容Hadoop Writable即可,此处我们将“key”处理为None,并设置keyClass为org.apache.hadoop.io.NullWritable。
而且运行上述程序之前,还需要将com.sina.dip.spark.converter.ObjectArrayToBytesRefArrayWritableConverter编译打包为独立的Jar:rcfile.jar,运行命令如下:
spark-submit --jars rcfile.jar 1.5.1/examples/app/spark_app_save_data_to_rcfile.py
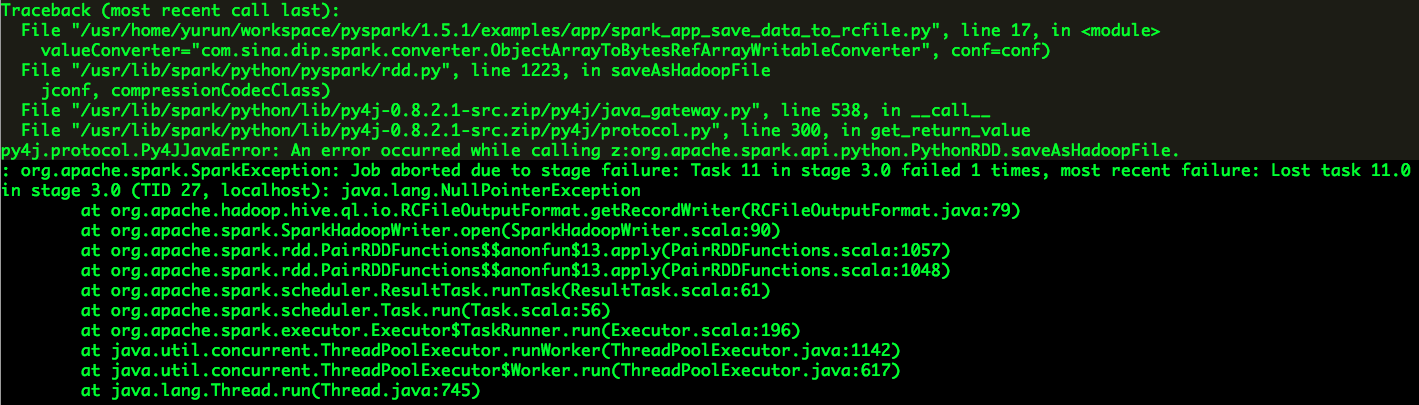
出乎意料,异常信息出现:
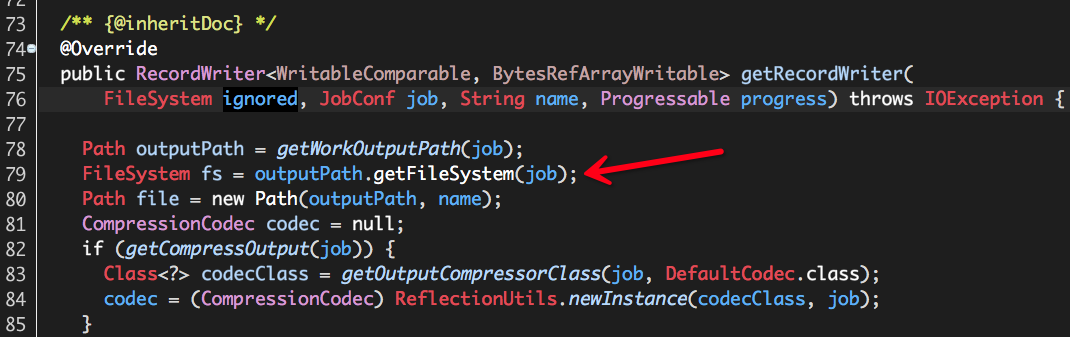
引发异常的代码并不是我们自定义扩展的ObjectArrayToBytesRefArrayWritableConverter,而是RCFileOutputFormat,怎么可能,这不是官方提供的代码么?根据异常堆栈可知,RCFileOutputFormat第79行(不同版本的Hive可能代码行数不同)代码出现空指针异常:
该行可能引发空指针异常的唯一原因就是outputPath == null,而outputPath的值由方法getWorkOutputPath计算而得:
其中JobContext.TASK_OUTPUT_DIR的值为mapreduce.task.output.dir。
熟悉Hadoop的同学可能已经想到,方法getWorkOutputPath是用来计算Map或Reduce Task临时输出目录的,JobContext.TASK_OUTPUT_DIR属性也是以前缀“mapreduce”开头的,“Spark运行时是不会为该属性设置值的”,所以outputPath == null,那么我们应该如何计算outputPath呢?
困惑之余,我们联想到当初调研Spark时是以文本为基础进行功能测试的,也就是说在Spark中使用TextInputFormat、TextOutputFormat是没有任何问题的,果断参考一下TextOutputFormat是如何实现的?
FileOutputFormat是一个基础类,这意味着我们可以重写RCFileOutputFormat getRecordWriter,使用FileOutputFormat.getTaskOutputPath替换getWorkOutputPath:
可以看出,重写后的getRecordWriter仅仅是改变了outputPath的计算方式,其它逻辑并没有改变,我们将重写后的类命名为com.sina.dip.spark.output.DipRCFileOutputFormat,并将其一并编译打包为独立的Jar:rcfile.jar。
重新修改Spark代码:
我们作出了两个地方的修改:
(1)parallelize numSlices:1,考虑到模拟的数据量比较小,为了便于查看结果,我们将“分区数”设置为1,这样最终仅有一个数据文件;
(2)outputFormatClass:com.sina.dip.spark.output.DipRCFileOutputFormat;
再次运行命令:
spark-submit --jars rcfile.jar 1.5.1/examples/app/spark_app_save_data_to_rcfile.py
程序执行结果之后,我们通过HDFS FS命令查看目录:hdfs://dip.dev.cdh5:8020/user/yurun/rcfile/:
数据文件已成功生成,为了确认写入的正确性,我们通过Hive RCFileCat命令查看文件:hdfs://dip.dev.cdh5:8020/user/yurun/rcfile/part-00000:
可见写入文件的数据与我们模拟的数据是一致的。
2. 读取上一步写入的数据;
运行上述程序之前,还需要将com.sina.dip.spark.converter.BytesRefArrayWritableToObjectArrayConverter编译打包为独立的Jar:rcfile.jar,运行命令如下:
spark-submit --jars rcfile.jar 1.5.1/examples/app/spark_app_read_data_from_rcfile.py
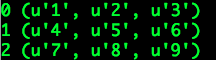
输出结果:
我们使用Hive原生的RCFileInputFormat,以及我们自己扩展的BytesRefArrayWritableToObjectArrayConverter正确完成了RCFile数据的读取,实际上pair[0]可以理解为“行数”(注意keyClass的设置),通常情况下没有实际意义,可以选择忽略。
综上所述,Spark(PySpark)使用RCFile的过程中会遇到三个“坑”:
(1)需要重写RCFileOutputFormat getRecordWriter;
(2)需要扩展Converter支持tuple(Object[]) => BytesRefArrayWritable的数据类型转换;
(3)需要扩展Converter支持BytesRefArrayWritable => tuple (Object[])的数据类型转换。
- ALS部署Spark集群入坑记
[Stage 236:> (0 + 0) / 400]17/12/04 09:45:55 ERROR yarn.ApplicationMaster: User class threw excep ...
- spark推测执行的坑
1.spark推测执行开启 设置 spark.speculation=true即可 2.spark开启推测执行的好处 推测执行是指对于一个Stage里面运行慢的Task,会在其他节点的Executor ...
- Spark DateType cast 踩坑
前言 在平时的 Spark 处理中常常会有把一个如 2012-12-12 这样的 date 类型转换成一个 long 的 Unix time 然后进行计算的需求.下面是一段示例代码: val sche ...
- Spark踩坑记——从RDD看集群调度
[TOC] 前言 在Spark的使用中,性能的调优配置过程中,查阅了很多资料,之前自己总结过两篇小博文Spark踩坑记--初试和Spark踩坑记--数据库(Hbase+Mysql),第一篇概况的归纳了 ...
- hive on spark的坑
原文地址:http://www.cnblogs.com/breg/p/5552342.html 装了一个多星期的hive on spark 遇到了许多坑.还是写一篇随笔,免得以后自己忘记了.同事也给我 ...
- [Big Data]从Hadoop到Spark的架构实践
摘要:本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过程. 当下,Spark已经在国内得到了广泛的 ...
- [转载] 从Hadoop到Spark的架构实践
转载自http://www.csdn.net/article/2015-06-08/2824889 http://www.zhihu.com/question/26568496 当下,Spark已经在 ...
- 从Hadoop到Spark的架构实践
当下,Spark已经在国内得到了广泛的认可和支持:2014年,Spark Summit China在北京召开,场面火爆:同年,Spark Meetup在北京.上海.深圳和杭州四个城市举办,其中仅北京就 ...
- 利用SparkSQL(java版)将离线数据或实时流数据写入hive的用法及坑点
1. 通常利用SparkSQL将离线或实时流数据的SparkRDD数据写入Hive,一般有两种方法.第一种是利用org.apache.spark.sql.types.StructType和org.ap ...
随机推荐
- volatile用处说明
在JDK1.2之前,Java的内存模型实现总是从主存(即共享内存)读取变量,是不需要进行特别的注意的.而随着JVM的成熟和优化,现在在多线程环境下volatile关键字的使用变得非常重要. 在当前 ...
- JAVA 循环在一个数字前面填充0.小例子
输入结果 00000000000567 String bala="567"; 固定长度是14位,怎么循环在bala前面填充00000000000 System.out.printl ...
- [Cookie] C#CookieHelper--C#操作Cookie的帮助类 (转载)
点击下载 CookieHelper.rar 下面是代码大家看一下 /// <summary> /// 类说明:CookieHelper /// 联系方式:361983679 /// 更新网 ...
- SQL使用存儲過程訪問不同服務器
用openrowset连接远程SQL或插入数据 --如果只是临时访问,可以直接用openrowset --查询示例 select * from openrowset('SQLOLEDB', 'sql服 ...
- iOS程序员的自我修养之道
新技术的了解渠道 WWDC开发者大会视频 官方文档 General -> Guides -> iOS x.x API Diffs 程序员的学习 iOS技术的学习 官当文档 Sample C ...
- [转]toString()方法
文章转自:http://blog.sina.com.cn/s/blog_85c1dc100101bxgg.html 今天看JS学习资料,看到一个toString()方法,在JS中,定义的所有对象都具有 ...
- HDU 1114 Piggy-Bank(完全背包)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1114 题目大意:根据储钱罐的重量,求出里面钱最少有多少.给定储钱罐的初始重量,装硬币后重量,和每个对应 ...
- 配置Struts2的异常处理
最好的方式是通过声明管理异常处理 1Action里面的execute()方法抛出所有异常:public String execute() throws Exception{} 2声明异常捕捉 ...
- In Place Upgrade of CentOS 6 to CentOS 7
Note: This is not the most highly recommended method to move from CentOS 6 to CentOS 7 ... but it ca ...
- 在oj平台上练习的一些总结【转】
程序书写过程中的一些小技巧:1. freopen(“1.txt”,”r”,stdin); //程序运行后系统自动输入此文档里面的内容(不需要进行手动输入)freopen(“1.txt”,”w”,std ...