从es中拉取全部数据/大量数据 使用scroll+scan避免深分页
es一次请求默认返回的数据条数是10条,可以通过设置size参数来控制返回数据的条数:
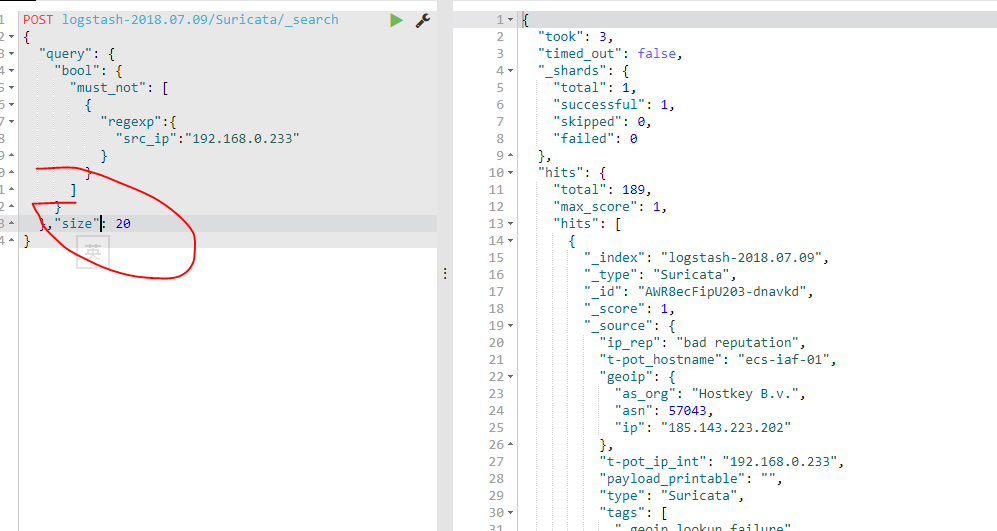
如果要返回很多数据,可以把size设置的很大,不过elastic search默认size最大不能超过1万。
那么如果数据量很大,超过1万,而又想要把所有数据都拉出来怎么办呢?
有三种方法:聚合,修改es的size的默认最大值,scroll+span
这里只讲我认为最好的方法:scroll+span
简单的说就是分页取出
第一次请求:
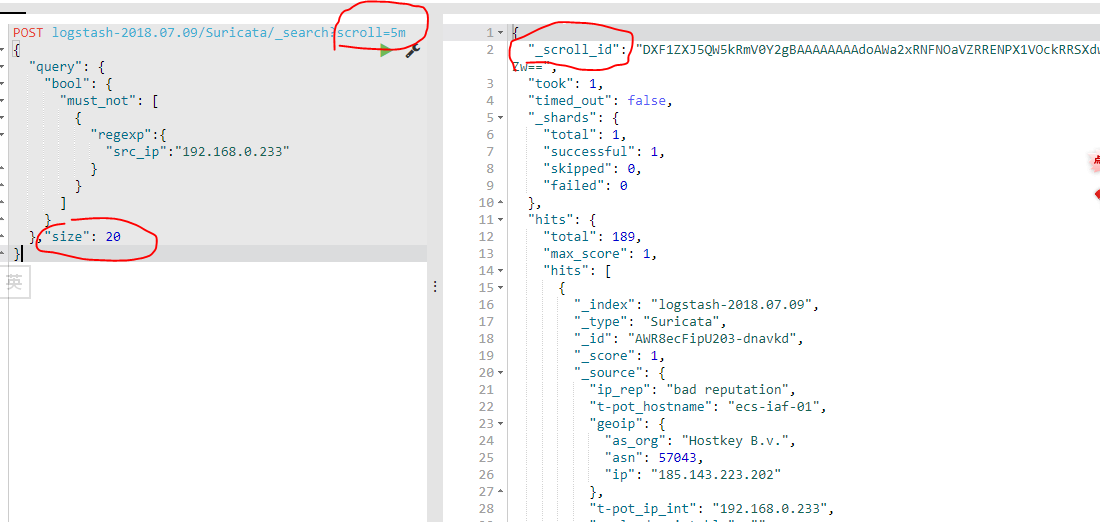
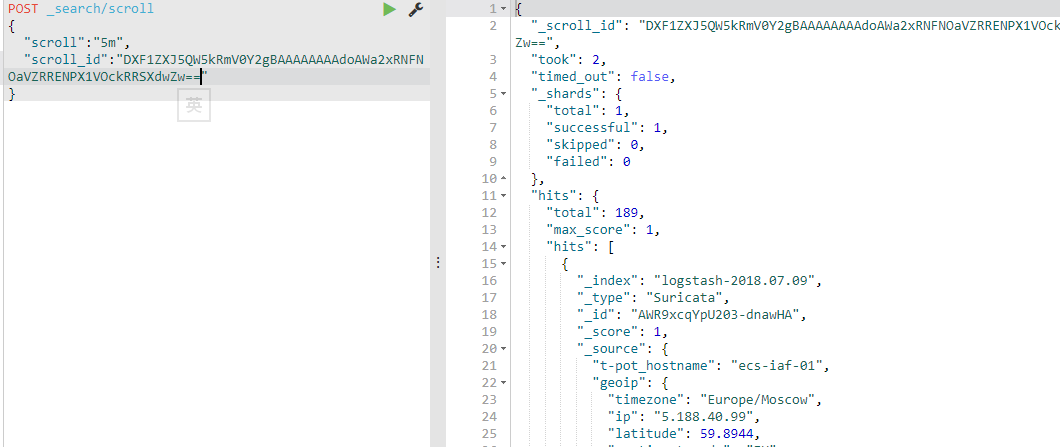
以后的请求(以后的请求默认带着第一次请求的参数):
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-scroll.html
https://blog.csdn.net/wild46cat/article/details/64123353
https://blog.csdn.net/fanxing1964/article/details/79366399
从es中拉取全部数据/大量数据 使用scroll+scan避免深分页的更多相关文章
- webMagic+RabbitMQ+ES爬取京东建材数据
本次爬虫所要爬取的数据为京东建材数据,在爬取京东的过程中,发现京东并没有做反爬虫动作,所以爬取的过程还是比较顺利的. 为什么要用WebMagic: WebMagic作为一款轻量级的Java爬虫框架,可 ...
- filebeat收集日志传输到Redis集群,logstash从Redis集群中拉取数据
前提:已配置好Redis集群,并设置的有统一的访问密码 架构是filebeat-->redis集群-->logstash->elasticsearch,需要修改filebeat的输出 ...
- logstash7.3版本不支持从redis集群中拉取数据
filebeat可以把收集到的日志传输到redis集群中,但是logstash如何从从redis集群中拉取数据的呢? ogstash使用的是7.3版本 经过查看官网文档,发现logstash7.3版本 ...
- 爬虫黑科技,我是怎么爬取indeed的职位数据的
最近在学习nodejs爬虫技术,学了request模块,所以想着写一个自己的爬虫项目,研究了半天,最后选定indeed作为目标网站,通过爬取indeed的职位数据,然后开发一个自己的职位搜索引擎,目前 ...
- [Elasticsearch] ES聚合场景下部分结果数据未返回问题分析
背景 在对ES某个筛选字段聚合查询,类似groupBy操作后,发现该字段新增的数据,聚合结果没有展示出来,但是用户在全文检索新增的筛选数据后,又可以查询出来, 针对该问题进行了相关排查. 排查思路 首 ...
- 使用python抓取婚恋网用户数据并用决策树生成自己择偶观
最近在看<机器学习实战>的时候萌生了一个想法,自己去网上爬一些数据按照书上的方法处理一下,不仅可以加深自己对书本的理解,顺便还可以在github拉拉人气.刚好在看决策树这一章,书里面的理论 ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
- 抓取Js动态生成数据且以滚动页面方式分页的网页
代码也可以从我的开源项目HtmlExtractor中获取. 当我们在进行数据抓取的时候,如果目标网站是以Js的方式动态生成数据且以滚动页面的方式进行分页,那么我们该如何抓取呢? 如类似今日头条这样的网 ...
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
随机推荐
- atitit.浏览器web gui操作类库 和 操作chrome浏览器的类库使用总结
atitit.浏览器web gui操作类库 和 操作chrome浏览器的类库使用总结 1. 常见标准 1 1.1. 录制重放 1 1.2. 一个窗体一个proxy cookie 1 1.3. exec ...
- 爱国者布局智能硬件,空探系列PM2.5检測仪“嗅霾狗”大曝光
随着6月1日史上最严禁烟令的正式实施,国内包含北京.上海.成都等大中型城市已经在公共场所全面禁烟.众所周知,实施禁烟令的根本在于促进空气的净化,实现环境的改善,要达到这个目的,光有禁烟令是远远 ...
- makefile之伪目标
伪目标 1. 伪目标的语法: 在书写伪目标时,首先需要声明伪目标,然后再定义伪目标规则. 1.1 声明伪目标: .PHONY clean (这里声明clean是伪目标) 1.2 定义伪目标规则: cl ...
- 兼容IE getElementsByClassName取标签
function getElementsByClassName(className,root,tagName) { //root:父节点,tagName:该节点的标签名. 这两个参数均可有可无 if( ...
- CentOS6.2下安装Qt5.1.0
因为要将程序实现跨平台,所以只能在CentOS6.2上再安装一次Qt,为了保证一致性,我使用了和windows下版本一样的Qt5.1.0,可以到此处下载. 下载好,复制到虚拟机上后,直接双击运行,一切 ...
- ubuntu MySQL数据库输入中文乱码 解决方案
一.登录MySQL查看用SHOW VARIABLES LIKE ‘character%’;下字符集,显示如下:+--------------------------+----------------- ...
- ecshop3.0.0 release0518 SQL注入
bugscan上的漏洞,自己复现了一下 注入在根目录下的flow.php elseif ($_REQUEST['step'] == 'repurchase') { include_once('incl ...
- (译)Getting Started——1.1.1 Start Developing IOS Today(开始IOS开发)
安装 本课程对于创建运行在iPad.iPhone和iPod触摸屏上的应用来说,是一个完美的起点.该向导的四个板块可以作为构建你第一个应用的简单向导——内容包括了你需要使用的工具,主要的理念 ...
- VM克隆之后启动eth0找不到eth0:unknown interface:no such device
问题出现:VMware 克隆之后,ifconfig命令执行找不到eth0,报错 eth0:unknown interface:no such device 是因为/etc/sysconf/networ ...
- 解密.net
一直疑惑与几个专业的名词,今天好不easy看完了.net视频,能够好好总结一下了. 一.关于.net中的几个概念 ①..NET Framework用来保证应用程序的安全的.详细的百度上有解说. wat ...