近千节点的Redis Cluster高可用集群案例:优酷蓝鲸优化实战(摘自高可用架构)
(原创)2016-07-26 吴建超 高可用架构
导读:Redis Cluster 作者建议的最大集群规模 1,000 节点,目前优酷在蓝鲸项目中管理了超过 700 台节点,积累了 Redis Cluster 大量宝贵经验,本文从 Redis Cluster 的工作原理出发,提出了管理 Redis 超大集群几点行之有效的优化方法。
吴建超,优酷土豆广告基础平台开发工程师,对互联网基础产品及大数据产品有兴趣。
在优酷,我们使用 Redis Cluster 构建了一套内存存储系统,项目代号为蓝鲸。蓝鲸的设计目标是高效读写,所有数据都在内存中。蓝鲸的主要应用场景是 cookie 和大数据团队计算的数据,都具有较强的时效性,因此所有的数据都有过期时间。更准确的说蓝鲸是一个全内存的临时存储系统。
到目前为止集群规模逐渐增长到 700+ 节点,即将达到作者建议的最大集群规模 1,000 节点。我们发现随着集群规模的扩大,带宽压力不断突出,并且响应时间 RT 方面也会略微升高。与一致性哈希构建的 Redis 集群不一样,Redis Cluster 不能做成超大规模的集群,它比较适合作为中等规模集群的解决方案。
运维期间,吞吐量与 RT 一直作为衡量集群稳定性的重要指标,这里在本文中,我们碰到的影响集群吞吐量与 RT 的一些问题与探索记录下来,希望对大家有所帮助。
Redis Cluster 工作原理
Redis 采用单进程模型,除去 bgsave 与 aof rewrite 会另外新建进程外,所有的请求与操作都在主进程内完成。其中比较重量级的请求与操作类型有:
客户端请求
集群通讯
从节同步
AOF 文件
其它定时任务
Redis 服务端采用 Reactor 设计模式,它是一种基于事件的编程模型,主要思想是将请求的处理流程划分成有序的事件序列,比如对于网络请求通常划分为:Accept new connections、Read input to buffer、Process request、 Response 等几个事件。并在一个无限循环的 EventLoop 中不断的处理这些事件。更多关于Reactor,请参考 https://en.wikipedia.org/wiki/Reactor 。
比较特别的是,Redis 中还存在一种时间事件,它其实是定时任务,与请求事件一样,它同样在 EventLoop 中处理。Redis 主线程的主要处理流程如下图:
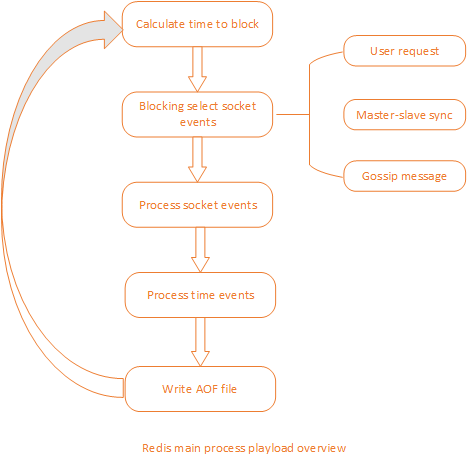
理解了 Redis 的单进程模型与主要负载情况,很容易明白,想要增加 Redis 吞吐量,只需要尽量降低其它任务的负载量就行了,所以提高 Redis 集群吞吐量的方式主要有:
提高 Redis 集群吞吐的方法
1. 适当调大 cluster-node-timeout 参数
我们发现当集群规模达到一定程度时,集群间消息通讯开销的带宽是极其可观的。
集群通信机制
Redis 集群采用无中心的方式,为了维护集群状态统一,节点之间需要互相交换消息。Redis采用交换消息的方式被称为 Gossip ,基本思想是节点之间互相交换信息最终所有节点达到一致,更多关于 Gossip 可参考 https://en.wikipedia.org/wiki/Gossip_protocol 。

总结集群通信机制的一些要点:
- Who:集群中每个节点
- When:定时发送,默认每隔一秒
- What:一个长度为 16,384 的 Bitmap 与集群中其它节点状态的十分之一
如何理解集群中节点状态的十分之一?假如集群中有 700 个节点,十分之一就是 70 个节点状态,节点状态具体数据结构见下边代码:
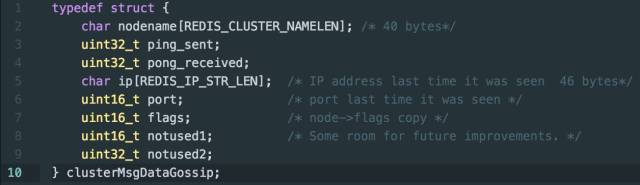
我们将注意力放在数据包大小与流量上,每个节点状态大小为 104 byte,所以对于 700 个节点的集群,这部分消息的大小为 70 * 104 = 7280,大约为 7KB。另外每个 Gossip 消息还需要携带一个长度为 16,384 的 Bitmap,大小为 2KB,所以每个 Gossip 消息大小大约为 9KB。
随着集群规模的不断扩大,每台主机的流量不断增长,我们怀疑集群间通信的流量已经大于前端请求产生的流量,所以做了以下实验以明确集群流量状况。
实验过程
实验环境为:节点 704,物理主机 40 台,每台物理主机有 16 个节点,集群采用一主一从模式,集群中节点 cluster-node-timeout 设置为 30 秒。
实验的大概思路为,分别截取一分钟时间内一个节点,在集群通信端口上,进入方向与出去方向的流量,并统计出消息条数,并最终计算出台主机因为集群间通讯产生的带宽开销。实验具体过程如下:
通过实验能看到进入方向与出去方向在 60s 内收到的数据包数量为 2,700 多个。因为 Redis 规定每个节点每一秒只向一个节点发送数据包,所以正常情况每个节点平均 60s 会收到 60 个数据包,为什么会有这么大的差距?
原来考虑到 Redis 发送对象节点的选取是随机的,所以存在两个节点很久都没有交换消息的情况,为了保证集群状态能在较短时间内达到一致性,Redis 规定当两个节点超过 cluster-node-timeout 的一半时间没有交换消息时,下次心跳交换消息。
解决了这个疑惑,接下来看带宽情况。先看 Redis Cluster 集群通信端口进入方向每台主机的每秒带宽为:

再看 Redis Cluster 集群通信端口出去方向每台主机的每秒带宽为:

所以每台主机进入方向的带宽为:

为什么需要加和
我们以节点 A 主动与节点 B 发生消息交换为例进行说明,交换过程如下图:
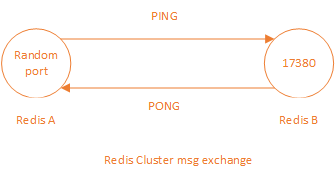
首先 A 随机一个端口向节点 B 的集群通讯端 17,380 发送 PING 消息,之后节点 B 通过 17,380 端口向节点 A 发送 PONG 消息,PONG 消息的内容与 PING 消息的内容相似,每个消息的大小也一样(9KB)。同理当节点 B 主动与节点 A 发生消息交换时也是同样的过程。
可以看出对于节点 A 进入方向的带宽不仅包含集群通讯端口的还包含随机端口的带宽。而对于节点 A 进入方向随机端口的带宽,正是其它节点出去方向的带宽。所以每台主机进入方向的带宽为上边公式计算的加和。同理出去方带宽与进入方带宽一样为 107.5MBit / s。
cluster-node-timeout 对带宽的影响
集群中每台主机的带宽状况如下图:
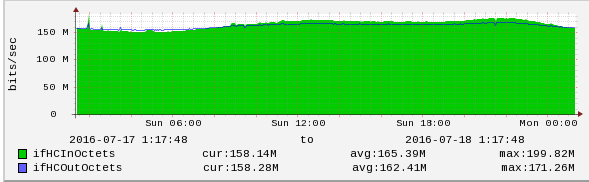
集群带宽图
每台主机的进出口带宽都大概在 150MBit / s 左右,其中集群通信带宽占 107.5MBit / s,所以前端请求的带宽占用大概为 45MBit / s。再来看当把 cluster-node-timeout 从 20s 调整到 30s 时,主机的带宽变化情况:
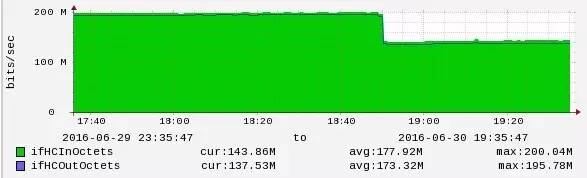
从图中,可以看到带宽下降 50MBit / s,效果非常明显。
经过以上实验我们能得出两个结论:
集群间通信占用大量带宽资源
调整 cluster-node-timeout 参数能有效降低带宽
Redis Cluster 判定节点为 fail 的机制
但是并不是 cluster-node-timeout 越大越好。当 cluster-node-timeou 增大的时候集群判断节点 fail 的时间会增加,从而 failover 的时间窗口会增加。集群判定节点为fail所需时间的计算公式如下:

当节点向失败节点发出 PING 消息,并且在 cluster-node-timeout 时间内还没有收到失败节点的 PONG 消息,此时判定它为 pfail 。pfail 即部分失败,它是一种中间状态,该状态随着集群心跳不断传播。再经过一半 cluster-node-timeout 时间后,所有节点都与失败的节点发生过心跳并且把它标记为 pfail 。当然也可能不需要这么长时间,因为其它节点之间的心跳同样会传递 pfail 状态,这里姑且以最大时间计算。
Redis Cluster 规定当集群中超过一半以上节点认为一个节点为 pfail 状态时,会把它标记为 fail 状态,并广播给其他所有节点。对于每个节点而言平均一秒钟收到一个心跳包,每次心跳都会携带随机的十分之一的节点个数。所以现在问题抽像为经过多长时间一个节点会积累到一半的 pfail 状态数。这是一个概率问题,因为个人并不擅长概率计算,这里直接取了一个较大概率能满足条件的数值 10。
所以上述公式不是达到这么长时间一定会判定节点为 fail,而是经过这么长时间集群有很大概率会判定节点 fail 。
Redis Cluster 默认 cluster-node-timeout 为 15s,我们将它设置成了 30s。也就是说 700 节点的集群,集群间带宽开销为 104.5MBit / s,判定节点失败时间窗口大概为 55s,实际上大多数情况都小于 55s,因为上边的计算都是按照高位时间估算的。
总而言之,对于大的 Redis 集群 cluster-node-timeout 参数的需要谨慎设定。
提高 Redis 集群吞吐的方法
2. 控制主节点写命令传播
Redis 中主节点的每个写命令传播到以下三个地方:
本地 AOF 文件,以持久化持数据
主节点的所有从节点,以保持主从数据同步
本节点的 repl_backlog 缓存,主要为了支持部分同步功能,详见官网 Replcation 文档 Partial resynchronization 部分:http://redis.io/topics/replication
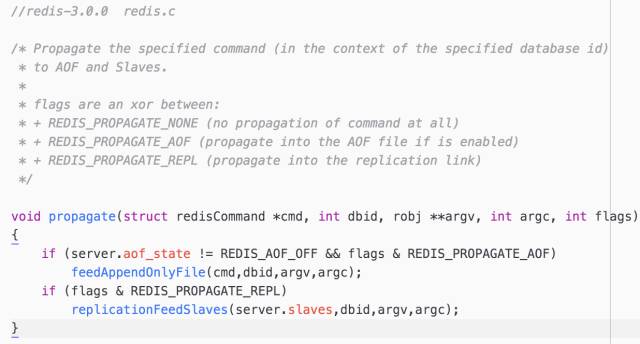
其中 repl_backlog 部分传播在 replicationFeedSlaves 函数中完成。
减少从节点的数量
高可用的集群不应该出现单点,所以 Redis 集群一般都会是主从模式。Redis 的主从同步机制是所有的主节点的写请求,会同步到所有的从节点。如果没有从节点,对于主节点来说,它只需要处理该请求即可。但对于有 N 个从节点的主节点来说,它需要额外的将请求传播给 N 个从节点。请注意这里是对于每个写请求都会这样处理。显而易见从节点的数量对主节点的吞吐量的影响是比较大的,我们采用的是一主一从模式。
因为从节点不需要同步数据,生产环境中观察主节点的 CPU 占用率要比从节点机器要高,这对这条结论起到了佐证的作用。
关闭 AOF 功能
如果开启 AOF 功能,每个写请求都会 Append 到本地 AOF 文件中,虽然 Linux 中写文件操作会利用到操作系统缓存机制,但是如果关闭 AOF 功能主线程中省去了写 AOF 文件的操作,显然会对吞吐量的增加有帮助。
AOF 是 Redis 的一种持久化方式,如果关闭了 AOF 功能怎么保证数据的安全性。我们的做法是定时在从节点 BGSAVE。当然具体采用何种策略需要结合具体情况来决定。
去掉频繁的 Cluster nodes 命令
在运维过程中发现前端请求的平均 RT 增加不少,大概 50% 左右。通过一番调研,发现是频繁的 cluster nodes 命令导致。
当时集群规模为 500+ 节点,cluster nodes 命令返回的结果大小有 103KB。cluster nodes 命令的频率为:每隔 20s 向集群所有节点发送。
提高 Redis 集群吞吐的方法
3. 调优 hz 参数
Redis 会定时做一些任务,任务频率由 hz 参数规定,定时任务主要包含:
主动清除过期数据
对数据库进行渐式Rehash
处理客户端超时
更新请求统计信息
发送集群心跳包
发送主从心跳
以下是作者对于 hz 参数的介绍:

我们没有修改 hz 参数的经验,由于其复杂性,并且在 hz 默认值 10 的情况下,理论上不会对 Redis 吞吐量产生太大影响,建议没有经验的情况下不要修改该参数。
参考资料
关于 Redis Cluster 可以参考官方的两篇文档:
Redis cluster tutorial: http://www.redis.io/topics/cluster-tutorial
Redis Cluster specification: http://www.redis.io/topics/cluster-spec
近千节点的Redis Cluster高可用集群案例:优酷蓝鲸优化实战(摘自高可用架构)的更多相关文章
- 部署Redis Cluster 6.0 集群并开启密码认证 和 Redis-cluster-proxy负载
部署Redis Cluster集群并开启密码认证 如果只想简单的搭建Redis Cluster,不需要设置密码和公网访问,可以参考官方文档. 节点介绍 Cluster模式推荐最少有6个节点,本次实验搭 ...
- redis cluster 设置密码做集群时gem下client.rb文件修改
redis节点有设置密码,然后在创建集群的时候没有设置密码的命令 ./redis-trib.rb create --replicas 1 127.0.0.1:6381 127.0.0.1:6382 1 ...
- 【docker】【redis】2.docker上设置redis集群---Redis Cluster部署【集群服务】【解决在docker中redis启动后,状态为Restarting,日志报错:Configured to not listen anywhere, exiting.问题】【Waiting for the cluster to join...问题】
参考地址:https://www.cnblogs.com/zhoujinyi/p/6477133.html https://www.cnblogs.com/cxbhakim/p/9151720.htm ...
- redis cluster 6.2集群
redis最新版本:redis-6.2.1.tar.gz 安装的版本是redis-6.0.3 采用的主机: djz-server-001 192.168.2.163 7001,7002,Admin@1 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- SpringCloud(四):服务注册中心Eureka Eureka高可用集群搭建 Eureka自我保护机制
第四章:服务注册中心 Eureka 4-1. Eureka 注册中心高可用集群概述在微服务架构的这种分布式系统中,我们要充分考虑各个微服务组件的高可用性 问题,不能有单点故障,由于注册中心 eurek ...
- Redis Cluster高可用集群在线迁移操作记录【转】
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Redis Cluster 4.0高可用集群安装、在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Redis Cluster高可用集群在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
随机推荐
- Java定时任务:利用java Timer类实现定时执行任务的功能
一.概述 在java中实现定时执行任务的功能,主要用到两个类,Timer和TimerTask类.其中Timer是用来在一个后台线程按指定的计划来执行指定的任务. TimerTask一个抽象类,它的子类 ...
- 分布式服务框架:Zookeeper简介
分布式服务框架:Zookeeper(分布式系统的可靠协调系统) 本文导读: 1 Zookeeper概述 2 Zookeeper总体结构 ——逻辑图.运转流程.特点.优点.数据结构 3 Zookeepe ...
- [LintCode] 合并排序数组
A subroutine of merge sort. class Solution { public: /** * @param A and B: sorted integer array A an ...
- 创建TPL自定义模板
文件布局 <!--1d7c7a527b6335cc7a623305ca940e1findex.tpl.html--> <!DOCTYPE html PUBLIC "-//W ...
- Xenu Link Sleuth
Xenu Link Sleuth 是一款检查网站死链接的软件,可以通过它打开一个本地的网页文件来检查它的链接,也可以输入任何网址来检查. 具体使用如下: 1,下载,并安装. 2,打开软件,出现 Tip ...
- Redis 教程
http://www.runoob.com/redis/redis-tutorial.html Redis系列(一)--安装.helloworld以及读懂配置文件 再开个redis系列,本系列打算不详 ...
- python中counter()记数
一:定义一个list数组,求数组中每个元素出现的次数 如果用Java来实现,是一个比较复杂的,需要遍历数组list. 但是Python很简单:看代码 a = [1,4,2,3,2,3,4,2] fro ...
- MyBatis 映射文件详解
1. MyBatis 映射文件之<select>标签 <select>用来定义查询操作; "id": 唯一标识符,需要和接口中的方法名一致; paramet ...
- Qt 打印机支持模块
Qt 打印支持 Qt为打印提供广泛的跨平台支持.使用每个平台上的打印系统,Qt应用程序可以打印到连接的打印机,并通过网络打印到远程打印机.Qt的打印系统还支持PDF文件生成,为基本的报告生成设施奠定了 ...
- String trim 坑 对于ascii码为160的去不掉
大家在使用string 的trim去除空格的时候,要注意一个坑呀,对于ascii码为160的去不掉 import java.util.Arrays; /** * Created by bjchen ...