Spark实际项目中调节并行度
实际项目中调节并行度
并行度概述
其实就是指的是,Spark作业中,各个stage的task数量,也就代表了Spark作业的在各个阶段(stage)的并行度
spark架构一览
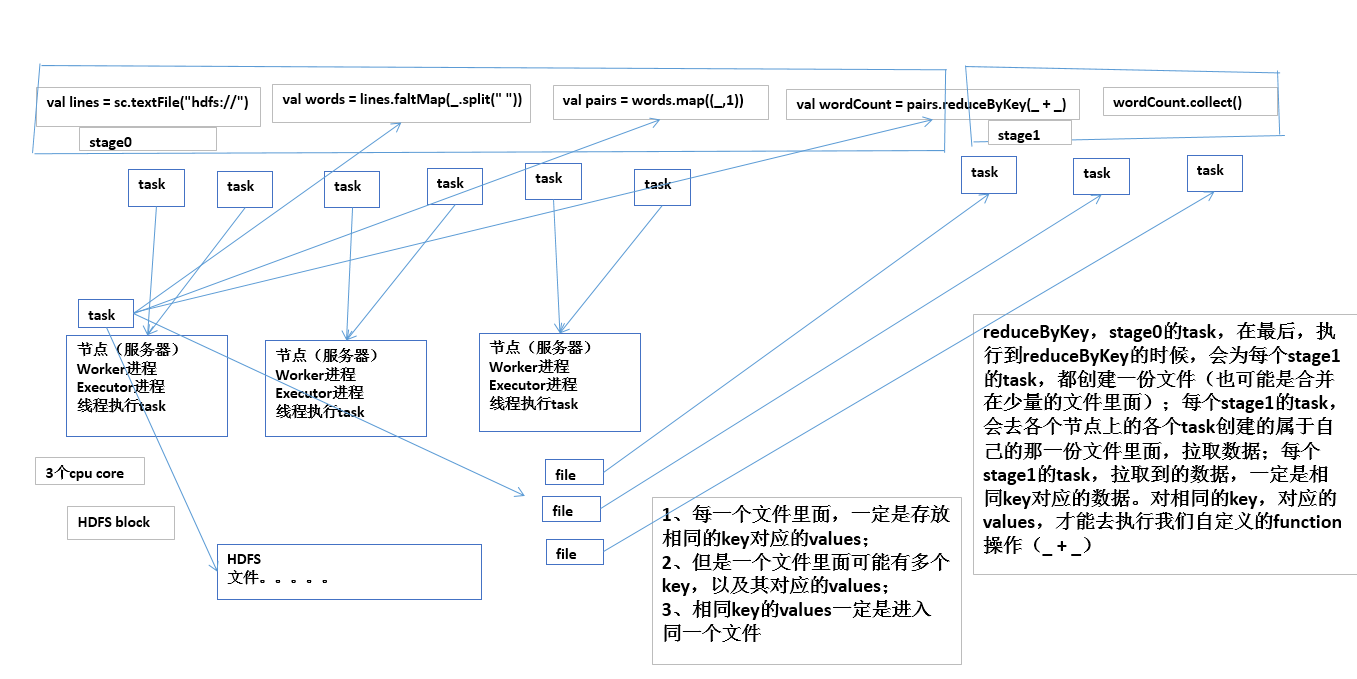
如果不调节并行度,导致并行度过低,会怎么样?
假设,现在已经在spark-submit脚本里面,给我们的spark作业分配了足够多的资源,比如50个executor,每个executor有10G内存,每个executor有3个cpu core。基本已经达到了集群或者yarn队列的资源上限。
task没有设置,或者设置的很少,比如就设置了,100个task。50个executor,每个executor有3个cpu core,也就是说,你的Application任何一个stage运行的时候,都有总数在150个cpu core,可以并行运行。但是你现在,只有100个task,平均分配一下,每个executor分配到2个task,ok,那么同时在运行的task,只有100个,每个executor只会并行运行2个task。每个executor剩下的一个cpu core,就浪费掉了。
资源虽然分配足够了,但是问题是,并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。
合理的并行度的设置,应该是要设置的足够大,大到可以完全合理的利用你的集群资源;比如上面的图例,总共集群有150个cpu core,可以并行运行150个task。那么就应该将Application的并行度,至少设置成150,才能完全有效的利用你的集群资源,让150个task,并行执行;而且task增加到150个以后,即可以同时并行运行,还可以让每个task要处理的数据量变少;比如总共150G的数据要处理,如果是100个task,每个task计算1.5G的数据;现在增加到150个task,可以并行运行,而且每个task主要处理1G的数据就可以。
很简单的道理,只要合理设置并行度,就可以完全充分利用你的集群计算资源,并且减少每个task要处理的数据量,最终,就是提升你的整个Spark作业的性能和运行速度
设置spark作业并行度
task数量,至少设置成与Spark application的总cpu core数量相同(最理想情况,比如总共150个cpu core,分配了150个task,一起运行,差不多同一时间运行完毕)
官方是推荐,task数量,设置成spark application总cpu core数量的2~3倍,比如150个cpu core,基本要设置task数量为300~500;
实际情况,与理想情况不同的,有些task会运行的快一点,比如50s就完了,有些task,可能会慢一点,要1分半才运行完,所以如果你的task数量,刚好设置的跟cpu core数量相同,可能还是会导致资源的浪费,因为,比如150个task,10个先运行完了,剩余140个还在运行,但是这个时候,有10个cpu core就空闲出来了,就导致了浪费。那如果task数量设置成cpu core总数的2~3倍,那么一个task运行完了以后,另一个task马上可以补上来,就尽量让cpu core不要空闲,同时也是尽量提升spark作业运行的效率和速度,提升性能
设置一个Spark Application的并行度
spark.default.parallelism
SparkConf conf = new SparkConf()
.set("spark.default.parallelism", "500")
小结
越平凡的技术点越是重中之重,看起来没有那么“炫酷”,但是其实是你每次写完一个spark作业,进入性能调优阶段的时候,应该优先调节的事情,就是这些(大部分时候,可能资源和并行度到位了,spark作业就很快了,几分钟就跑完了)
Spark实际项目中调节并行度的更多相关文章
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
- Spark在实际项目中分配更多资源
Spark在实际项目中分配更多资源 Spark在实际项目中分配更多资源 性能调优概述 分配更多资源 性能调优问题 解决思路 为什么调节了资源以后,性能可以提升? 性能调优概述 分配更多资源 性能调优的 ...
- SparkSQL项目中的应用
Spark是一个通用的大规模数据快速处理引擎.可以简单理解为Spark就是一个大数据分布式处理框架.基于内存计算的Spark的计算速度要比Hadoop的MapReduce快上100倍以上,基于磁盘的计 ...
- spark在idea中本地如何运行?(处理问题NoSuchFieldException: SHUTDOWN_HOOK_PRIORITY)
spark在idea中本地如何运行? 前几天尝试使用idea在本地运行spark+scala的程序,出现了问题,http://www.cnblogs.com/yjf512/p/7662105.html ...
- JAVA项目中常用的异常处理情况总结
JAVA项目中常用的异常知识点总结 1. java.lang.nullpointerexception这个异常大家肯定都经常遇到,异常的解释是"程序遇上了空指针",简单地说就是调用 ...
- JAVA项目中常用的异常知识点总结
JAVA项目中常用的异常知识点总结 1. java.lang.nullpointerexception这个异常大家肯定都经常遇到,异常的解释是"程序遇上了空指针",简单地说就是调用 ...
- 解决Maven项目中jar包依赖冲突问题
版本冲突的解决方案 [1]调节原则 [1]路径最短者优先原则 [2]路径相同时,先声明者优先原则 [2]排除原则:用于排除某项依赖的依赖jar包 <dependency> <grou ...
- Spark读取HDFS中的Zip文件
1. 任务背景 近日有个项目任务,要求读取压缩在Zip中的百科HTML文件,经分析发现,提供的Zip文件有如下特点(=>指代对应解决方案): (1) 压缩为分卷文件 => 只需将解压缩在同 ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
随机推荐
- C#中的多线程 - 多线程的使用 z
原文:http://www.albahari.com/threading/part3.aspx 专题:C#中的多线程 1基于事件的异步模式Permalink 基于事件的异步模式(event-based ...
- RuntimeBroker ClipboardBroker EoP
datetime: 2017.04.28 漏洞简介 随着沙箱技术的普及,现在主流的操作系统及软件都开始支持沙箱,以此来缓解层出不穷的远程代码执行漏洞对系统造成的危害.AppContainer是自Win ...
- mongodb---js脚本操作速记
之前写一些mongodb的同步或操作程序,往往使用perl,甚至c实现,这样程序很繁琐,而且逻辑不好控制,甚至一些功能和命令什么的,在这些语言的mongo驱动中就没有实现.后来发现mongodb 的s ...
- 分享一个SqliteHelper类
分享一个SqliteHelper类 SQLite作为一个本地文件数据库相当好用,小巧.快速.支持事务.关系型,甚至可以运行在Android上.在很久以前的一个项目中,我们用过它来将接收到的数据做本地统 ...
- ListView实现分页加载(三)实现分页加载
在上一篇中,我们实现了底部布局(即带上了进度条).没有读过的朋友可以点击下面的链接: http://www.cnblogs.com/fuly550871915/p/4866966.html 但是进度条 ...
- yaml 配置文件
https://www.cnblogs.com/xinjing-jingxin/p/9128293.html ---文件开始 - 列表 key: val 字典 注意:字典里面可以嵌套字典,列表等.(举 ...
- Codeforces Round #533 (Div. 2) B. Zuhair and Strings 【模拟】
传送门:http://codeforces.com/contest/1105/problem/B B. Zuhair and Strings time limit per test 1 second ...
- Css3 实现关键帧动画
<div class="person"> </div> <script> var str1 = "@keyframes move{&q ...
- Linux环境进程间通信: 共享内存
Linux环境进程间通信: 共享内存 第一部分 共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式.两个不同进程A.B共享内存的意思是,同一块物理内存被映射到进程A.B各自的进程地址空间.进 ...
- Non-Nullable Types vs C#: Fixing the Billion Dollar Mistake (转载)
One of the top suggestions (currently #15 on uservoice) for improving C# is the addition of non-null ...