Java面试题之HashMap阿里面试必问知识点,你会吗?
面试官Q1:你用过HashMap,你能跟我说说它的数据结构吗?
HashMap作为一种容器类型,无论你是否了解过其内部的实现原理,它的大名已经频频出现在各种互联网Java面试题中了。从基本的使用角度来说,它很简单,但从其内部的实现来看,它又并非想象中那么容易。如果你一定要问了解其内部实现与否对于写程序究竟有多大影响,我不能给出一个确切的答案。但是作为一名合格程序员,对于这种遍地都在谈论的技术不应该不为所动。下面我们将自己实现一个简易版HashMap,然后通过阅读HashMap的源码逐步来认识HashMap的底层数据结构。
简易HashMap V1.0版本
V1.0版本我们需要实现Map的几个重要的功能:
可以存放键值对
可以根据键查找到值
键不能重复
1public class CustomHashMap {
2 CustomEntry[] arr = new CustomEntry[990];
3 int size;
4
5 public void put(Object key, Object value) {
6 CustomEntry e = new CustomEntry(key, value);
7 for (int i = 0; i < size; i++) {
8 if (arr[i].key.equals(key)) {
9 //如果有key值相等,直接覆盖value
10 arr[i].value = value;
11 return;
12 }
13 }
14 arr[size++] = e;
15 }
16
17 public Object get(Object key) {
18 for (int i = 0; i < size; i++) {
19 if (arr[i].key.equals(key)) {
20 return arr[i].value;
21 }
22 }
23 return null;
24 }
25
26 public boolean containsKey(Object key) {
27 for (int i = 0; i < size; i++) {
28 if (arr[i].key.equals(key)) {
29 return true;
30 }
31 }
32 return false;
33 }
34
35 public static void main(String[] args) {
36 CustomHashMap map = new CustomHashMap();
37 map.put("k1", "v1");
38 map.put("k2", "v2");
39 map.put("k2", "v4");
40 System.out.println(map.get("k2"));
41 }
42
43}
44
45class CustomEntry {
46 Object key;
47 Object value;
48
49 public CustomEntry(Object key, Object value) {
50 super();
51 this.key = key;
52 this.value = value;
53 }
54
55 public Object getKey() {
56 return key;
57 }
58
59 public void setKey(Object key) {
60 this.key = key;
61 }
62
63 public Object getValue() {
64 return value;
65 }
66
67 public void setValue(Object value) {
68 this.value = value;
69 }
70
71}上面就是我们自定义的简单Map实现,可以完成V1.0提出的几个功能点,但是大家有木有发现,这个Map是基于数组实现的,不管是put还是get方法,每次都要循环去做数据的对比,可想而知效率会很低,现在数组长度只有990,那如果数组的长度很长了,岂不是要循环很多次。既然问题出现了,我们有没有更好的办法做改进,使得效率提升,答案是肯定,下面就是V2.0版本升级。
简易HashMap V2.0版本
V2.0版本需要处理问题如下:
减少遍历次数,提升存取数据效率
在做改进之前,我们先思考一下,有没有什么方式可以在我们放数据的时候,通过一次定位,就能将这个数放到某个位置,而再我们获取数据的时候,直接通过一次定位就能找到我们想要的数据,那样我们就减少了很多迭代遍历次数。
接下来,我们需要介绍一下哈希表的相关知识
在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
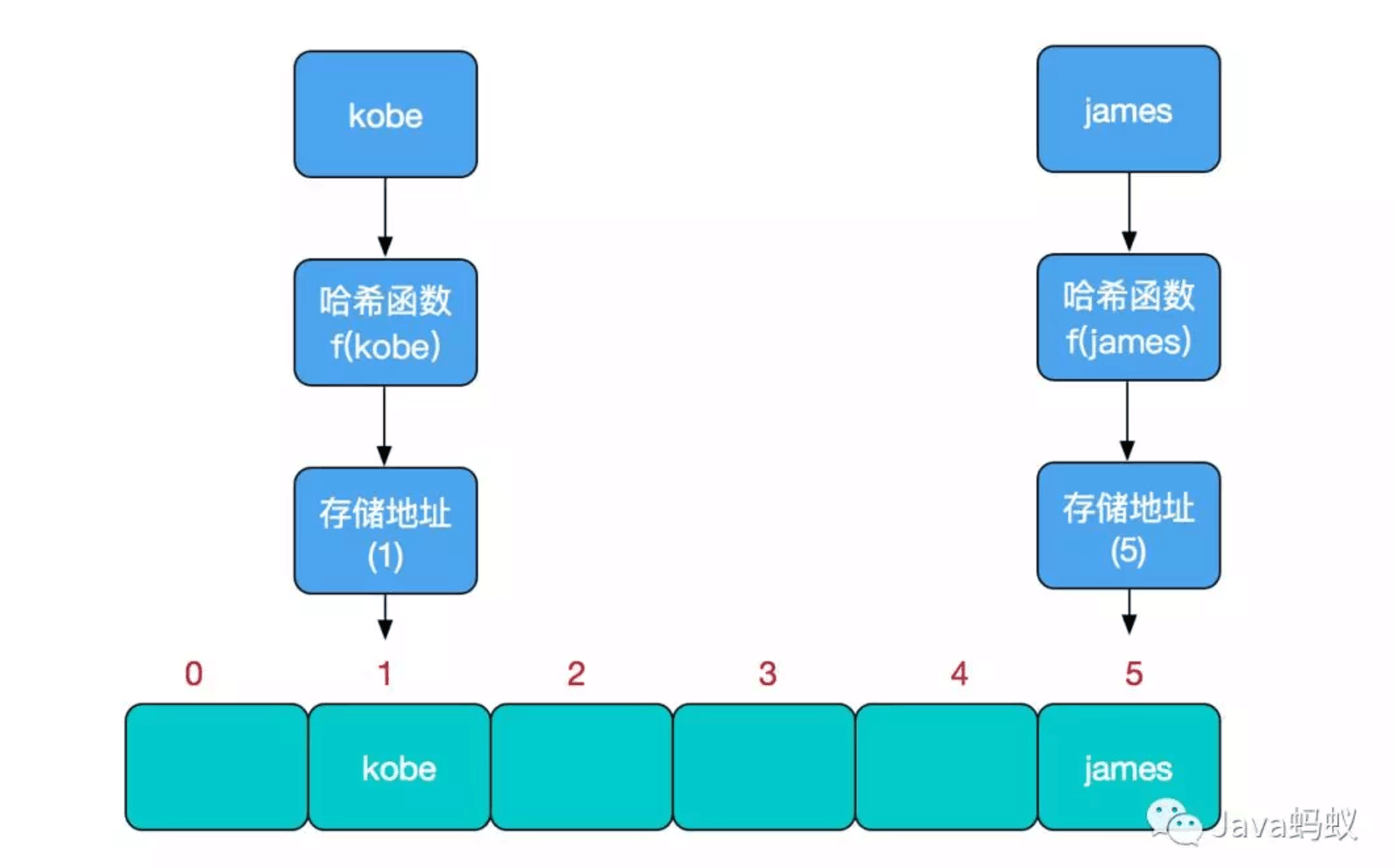
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。既然思路有了,那我们继续改进呗!
1public class CustomHashMap {
2 CustomEntry[] arr = new CustomEntry[999];
3
4 public void put(Object key, Object value) {
5 CustomEntry entry = new CustomEntry(key, value);
6 //使用Hash码对999取余数,那么余数的范围肯定在0到998之间
7 //你可能也发现了,不管怎么取余数,余数也会有冲突的时候(暂时先不考虑,后面慢慢道来)
8 //至少现在我们存数据的效率明显提升了,key.hashCode() % 999 相同的key算出来的结果肯定是一样的
9 int a = key.hashCode() % 999;
10 arr[a] = entry;
11 }
12
13 public Object get(Object key) {
14 //取数的时候也通过一次定位就找到了数据,效率明显得到提升
15 return arr[key.hashCode() % 999].value;
16 }
17
18 public static void main(String[] args) {
19 CustomHashMap map = new CustomHashMap();
20 map.put("k1", "v1");
21 map.put("k2", "v2");
22 System.out.println(map.get("k2"));
23 }
24
25}
26
27class CustomEntry {
28 Object key;
29 Object value;
30
31 public CustomEntry(Object key, Object value) {
32 super();
33 this.key = key;
34 this.value = value;
35 }
36
37 public Object getKey() {
38 return key;
39 }
40
41 public void setKey(Object key) {
42 this.key = key;
43 }
44
45 public Object getValue() {
46 return value;
47 }
48
49 public void setValue(Object value) {
50 this.value = value;
51 }
52}通过上面的代码,我们知道余数也有冲突的时候,不一样的key计算出相同的地址,那么这个时候我们又要怎么处理呢?
哈希冲突
如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
通过上面的说明知道,HashMap的底层是基于数组+链表的方式,此时,我们需要再对V2.0的Map再次升级
简易HashMap V3.0版本
V3.0版本需要处理问题如下:
存取数据的结构改进
代码如下:
1public class CustomHashMap {
2 LinkedList[] arr = new LinkedList[999];
3
4 public void put(Object key, Object value) {
5 CustomEntry entry = new CustomEntry(key, value);
6 int a = key.hashCode() % arr.length;
7 if (arr[a] == null) {
8 LinkedList list = new LinkedList();
9 list.add(entry);
10 arr[a] = list;
11 } else {
12 LinkedList list = arr[a];
13 for (int i = 0; i < list.size(); i++) {
14 CustomEntry e = (CustomEntry) list.get(i);
15 if (entry.key.equals(key)) {
16 e.value = value;// 键值重复需要覆盖
17 return;
18 }
19 }
20 arr[a].add(entry);
21 }
22 }
23
24 public Object get(Object key) {
25 int a = key.hashCode() % arr.length;
26 if (arr[a] != null) {
27 LinkedList list = arr[a];
28 for (int i = 0; i < list.size(); i++) {
29 CustomEntry entry = (CustomEntry) list.get(i);
30 if (entry.key.equals(key)) {
31 return entry.value;
32 }
33 }
34 }
35 return null;
36 }
37
38 public static void main(String[] args) {
39 CustomHashMap map = new CustomHashMap();
40 map.put("k1", "v1");
41 map.put("k2", "v2");
42 map.put("k2", "v3");
43 System.out.println(map.get("k2"));
44 }
45
46}
47
48class CustomEntry {
49 Object key;
50 Object value;
51
52 public CustomEntry(Object key, Object value) {
53 super();
54 this.key = key;
55 this.value = value;
56 }
57
58 public Object getKey() {
59 return key;
60 }
61
62 public void setKey(Object key) {
63 this.key = key;
64 }
65
66 public Object getValue() {
67 return value;
68 }
69
70 public void setValue(Object value) {
71 this.value = value;
72 }
73
74}最终的数据结构如下:

简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
HashMap源码
从上面的推导过程,我们逐渐清晰的认识了HashMap的实现原理,下面我们通过阅读部分源码,来看看HashMap(基于JDK1.7版本)
1transient Entry[] table;
2
3static class Entry<K,V> implements Map.Entry<K,V> {
4 final K key;
5 V value;
6 Entry<K,V> next;
7 final int hash;
8 ...
9}
可以看出,HashMap中维护了一个Entry为元素的table,transient修饰表示不参与序列化。每个Entry元素存储了指向下一个元素的引用,构成了链表。
put方法实现
1public V put(K key, V value) {
2 // HashMap允许存放null键和null值。
3 // 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
4 if (key == null)
5 return putForNullKey(value);
6 // 根据key的keyCode重新计算hash值。
7 int hash = hash(key.hashCode());
8 // 搜索指定hash值在对应table中的索引。
9 int i = indexFor(hash, table.length);
10 // 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
11 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
12 Object k;
13 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
14 V oldValue = e.value;
15 e.value = value;
16 e.recordAccess(this);
17 return oldValue;
18 }
19 }
20 // 如果i索引处的Entry为null,表明此处还没有Entry。
21 modCount++;
22 // 将key、value添加到i索引处。
23 addEntry(hash, key, value, i);
24 return null;
25}
从源码可以看出,大致过程是,当我们向HashMap中put一个元素时,首先判断key是否为null,不为null则根据key的hashCode,重新获得hash值,根据hash值通过indexFor方法获取元素对应哈希桶的索引,遍历哈希桶中的元素,如果存在元素与key的hash值相同以及key相同,则更新原entry的value值;如果不存在相同的key,则将新元素从头部插入。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
看一下重hash的方法:
1static int hash(int h) {
2 h ^= (h >>> 20) ^ (h >>> 12);
3 return h ^ (h >>> 7) ^ (h >>> 4);
4}
此算法加入了高位计算,防止低位不变,高位变化时,造成的hash冲突。在HashMap中,我们希望元素尽可能的离散均匀的分布到每一个hash桶中,因此,这边给出了一个indexFor方法:
1static int indexFor(int h, int length) {
2 return h & (length-1);
3}
这段代码使用 & 运算代替取模(上面我们自己实现的方式就是取模),效率更高。
再来看一眼addEntry方法:
1void addEntry(int hash, K key, V value, int bucketIndex) {
2 // 获取指定 bucketIndex 索引处的 Entry
3 Entry<K,V> e = table[bucketIndex];
4 // 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
5 table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
6 // 如果 Map 中的 key-value 对的数量超过了极限
7 if (size++ >= threshold)
8 // 把 table 对象的长度扩充到原来的2倍。
9 resize(2 * table.length);
10}
很明显,这边代码做的事情就是从头插入新元素;如果size超过了阈值threshold,就调用resize方法扩容两倍,至于,为什么要扩容成原来的2倍,请参考,此节不是我们要说的重点。
get方法实现
1public V get(Object key) {
2 if (key == null)
3 return getForNullKey();
4 int hash = hash(key.hashCode());
5 for (Entry<K,V> e = table[indexFor(hash, table.length)];
6 e != null;
7 e = e.next) {
8 Object k;
9 if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
10 return e.value;
11 }
12 return null;
13}
这段代码很容易理解,首先根据key的hashCode计算hash值,根据hash值确定桶的位置,然后遍历。
现在,大家都应该对HashMap的底层结构有了更深刻的认识吧,下面笔者对于面试时可能出现的关于HashMap相关的面试题,做了一下梳理,大致如下:
你了解HashMap的底层数据结构吗?(本文已做梳理)
为何HashMap的数组长度一定是2的次幂?
HashMap何时扩容以及它的扩容机制?
HashMap的键一般使用的String类型,还可以用别的对象吗?
HashMap是线程安全的吗,如何实现线程安全?
Java面试题之HashMap阿里面试必问知识点,你会吗?的更多相关文章
- linux驱动工程面试必问知识点
linux内核原理面试必问(由易到难) 简单型 1:linux中内核空间及用户空间的区别?用户空间与内核通信方式有哪些? 2:linux中内存划分及如何使用?虚拟地址及物理地址的概念及彼此之间的转化, ...
- 一万三千字的HashMap面试必问知识点详解
目录 概论 Hasmap 的继承关系 hashmap 的原理 解决Hash冲突的方法 开放定址法 再哈希法 链地址法 建立公共溢出区 hashmap 最终的形态 Hashmap 的返回值 HashMa ...
- java基础(十七)----- 浅谈Java中的深拷贝和浅拷贝 —— 面试必问
假如说你想复制一个简单变量.很简单: int apples = 5; int pears = apples; 不仅仅是int类型,其它七种原始数据类型(boolean,char,byte,short, ...
- 深入理解微服务架构spring的各个知识点(面试必问知识点)
什么是spring spring是一个开源框架,spring为简化企业级开发而生,使用spring可以使简单的java bean 实现以前只有EJG才能实现的功能. Spring是一个轻量级的控制反转 ...
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
- 一线大厂Java面试必问的2大类Tomcat调优
一.前言 最近整理了 Tomcat 调优这块,基本上面试必问,于是就花了点时间去搜集一下 Tomcat 调优都调了些什么,先记录一下调优手段,更多详细的原理和实现以后用到时候再来补充记录,下面就来介绍 ...
- 高级测试工程师面试必问面试基础整理——python基础(一)(首发公众号:子安之路)
现在深圳市场行情,高级测试工程师因为都需要对编程语言有较高的要求,但是大部分又没有python笔试机试题,所以面试必问python基础,这里我整理一下python基本概念,陆续收集到面试中python ...
- 互联网公司面试必问的mysql题目(下)
这是mysql系列的下篇,上篇文章地址我附在文末. 什么是数据库索引?索引有哪几种类型?什么是最左前缀原则?索引算法有哪些?有什么区别? 索引是对数据库表中一列或多列的值进行排序的一种结构.一个非常恰 ...
- 互联网公司面试必问的mysql题目(上)
又到了招聘的旺季,被要求准备些社招.校招的题库.(如果你是应届生,尤其是东北的某大学,绝对福利哦) 介绍:MySQL是一个关系型数据库管理系统,目前属于 Oracle 旗下产品.虽然单机性能比不上or ...
随机推荐
- jquery鼠标经过水平180度翻转效果
Html代码: <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN""http://www.w3.org/TR/htm ...
- javascript 判断对象的内置类型
判断某个对象值属于哪种内置类型,最靠谱的做法就是通过Object.prototype.toString方法.在toString方法被调用时,会执行下面的操作步骤:1. 获取this对象的[[Class ...
- Linux一些常用的基础命令,总结的很好,收藏了
原文地址:https://www.cnblogs.com/yjd_hycf_space/p/7730690.html
- [BZOJ 5158][Tjoi2014]Alice and Bob
传送门 \(\color{green}{solution}\) 贪心 /************************************************************** P ...
- Win10远程连接,出现身份验证错误。远程计算机要求的函数不受支持 这可能是由于CredSSP加密Oracle修正 。
问题: 升级至win10 最新版本10.0.17134,安装最新补丁后无法远程win server 2016服务器,报错信息如下: 出现身份验证错误,要求的函数不正确,这可能是由于CredSSP加密O ...
- sql语句之group_concat函数
MySQL中group_concat函数 完整的语法如下: group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔 ...
- $bzoj1016-JSOI2008$ 最小生成树计数 最小生成树 $dfs/matrix-tree$定理
题面描述 现在给出了一个简单无向加权图.你不满足于求出这个图的最小生成树,而希望知道这个图中有多少个不同的最小生成树.(如果两颗最小生成树中至少有一条边不同,则这两个最小生成树就是不同的).由于不同的 ...
- J15W-J45W黄铜截止阀厂家,J15W-J45W黄铜截止阀价格 - 专题栏目 - 无极资讯网
无极资讯网 首页 最新资讯 最新图集 最新标签 搜索 J15W-J45W黄铜截止阀 无极资讯网精心为您挑选了(J15W-J45W黄铜截止阀)信息,其中包含了(J15W-J45W黄铜截止阀)厂家,( ...
- (转)合格linux运维人员必会的30道shell编程面试题及讲解
超深度讲解shell高级编程实战,截至目前shell编程课程国内培训机构最细的课程,不信请看学员表现的水平. 课程牛不牛,不是看老师.课表,而是看培养的的学生水平,目前全免费中伙伴们赶紧看啊. htt ...
- Oracle 通过数据字典查询系统信息
简介:数据字典记录了数据库系统的信息,他是只读表和视图的集合,数据字典的所有者是sys用户.注:用户只能在数据字典上执行查询操作,而维护和修改是由系统自己完成的. 1.数据字典的组成:数据字典包括数据 ...