Spark 宽窄依赖
面试时被问到spark RDD的宽窄依赖,虽然问题很简单,但是答得很不好。还是应该整理一下描述,这样面试才能答得更好。
看到一篇很好的文章,转载过来了。感觉比《spark技术内幕》这本书讲的好多了。
原文链接:https://www.jianshu.com/p/5c2301dfa360
1.窄依赖
窄依赖就是指父RDD的每个分区只被一个子RDD分区使用,子RDD分区通常只对应常数个父RDD分区,如下图所示【其中每个小方块代表一个RDD Partition】
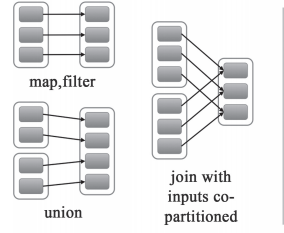
窄依赖有分为两种:
- 一种是一对一的依赖,即OneToOneDependency
- 还有一个是范围的依赖,即RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同
2.宽依赖
宽依赖就是指父RDD的每个分区都有可能被多个子RDD分区使用,子RDD分区通常对应父RDD所有分区,如下图所示【其中每个小方块代表一个RDD Partition】

3.窄依赖与窄依赖比较
- 宽依赖往往对应着shuffle操作,需要在运行的过程中将同一个RDD分区传入到不同的RDD分区中,中间可能涉及到多个节点之间数据的传输,而窄依赖的每个父RDD分区通常只会传入到另一个子RDD分区,通常在一个节点内完成。
- 当RDD分区丢失时,对于窄依赖来说,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重新计算与子RDD分区对应的父RDD分区就行。这个计算对数据的利用是100%的
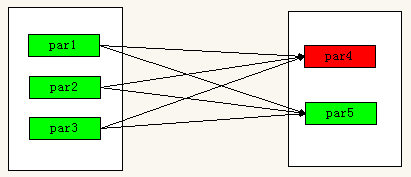
- 当RDD分区丢失时,对于宽依赖来说,重算的父RDD分区只有一部分数据是对应丢失的子RDD分区的,另一部分就造成了多余的计算。宽依赖中的子RDD分区通常来自多个父RDD分区,极端情况下,所有父RDD都有可能重新计算。如下图,par4丢失,则需要重新计算par1,par2,par3,产生了冗余数据par5
4.宽依赖,窄依赖函数
- 窄依赖的函数有:
map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues - 宽依赖的函数有:
groupByKey, join(父RDD不是hash-partitioned ), partitionBy
作者:不圆的石头
链接:https://www.jianshu.com/p/5c2301dfa360
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Spark 宽窄依赖的更多相关文章
- 11、spark内核架构剖析与宽窄依赖
一.内核剖析 1.内核模块 1.Application 2.spark-submit 3.Driver 4.SparkContext 5.Master 6.Worker 7.Executor 8.Jo ...
- Spark RDD基本概念、宽窄依赖、转换行为操作
目录 RDD概述 RDD的内部代码 案例 小总结 转换.行动算子 宽.窄依赖 Reference 本文介绍一下rdd的基本属性概念.rdd的转换/行动操作.rdd的宽/窄依赖. RDD:Resilie ...
- spark rdd 宽窄依赖理解
== 转载 == http://blog.csdn.net/houmou/article/details/52531205 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过 ...
- Spark RDD 宽窄依赖
RDD 宽窄依赖 RDD之间有一系列的依赖关系, 可分为窄依赖和宽依赖 窄依赖 从 RDD 的 parition 角度来看 父 RRD 的 parition 和 子 RDD 的 parition 之间 ...
- 【Spark-core学习之五】 RDD宽窄依赖 & Stage
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark 宽窄依赖和stage的划分
窄依赖 父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的 ...
- 关于spark RDD trans action算子、lineage、宽窄依赖详解
这篇文章想从spark当初设计时为何提出RDD概念,相对于hadoop,RDD真的能给spark带来何等优势.之前本想开篇是想总体介绍spark,以及环境搭建过程,但个人感觉RDD更为重要 铺垫 在h ...
- spark优化——依赖包传入HDFS_spark.yarn.jar和spark.yarn.archive的使用
一.参数说明 启动Spark任务时,在没有配置spark.yarn.archive或者spark.yarn.jars时, 会看到不停地上传jar,非常耗时:使用spark.yarn.archive可以 ...
- 通过 spark.files 传入spark任务依赖的文件源码分析
版本:spak2.3 相关源码:org.apache.spark.SparkContext 在创建spark任务时候,往往会指定一些依赖文件,通常我们可以在spark-submit脚本使用--file ...
随机推荐
- 巨蟒python全栈开发数据库前端1:HTML基础
1.HTML介绍 什么是前端? 前端就是我们打开浏览器的页面.,很多公司都有自己的浏览器的页面,这个阶段学习的就是浏览器界面 比如京东的界面:https://www.jd.com/ 引子 例1 soc ...
- 解决ajax post json数据 后端无法收到的问题
如图,想把input框中的文字以json格式post出去,结果后端收不到 使用wireshark抓包,根本没有抓到发往服务器的包,说明错误在前端. 后来发现ajax post json数据的时候key ...
- settings配置与model优化
settings配置与model优化 settings: 项目基本配置(settings.py, models.py, admin.py, templates...).数据库操作.中间件 http: ...
- 深入Redis内部-Redis 源码讲解(转)
Redis作为 NoSQL 数据库的杰出代表,一直广受关注,其轻量级的敏捷架构,向来有存储中的瑞士军刀之称.下面推荐的一篇文章,从源码的角度讲解了Redis 的整个工作流程,是了解 Redis 流程的 ...
- 3 TensorFlow入门之识别手写数字
------------------------------------ 写在开头:此文参照莫烦python教程(墙裂推荐!!!) ---------------------------------- ...
- HTML 块级元素与行内元素
1.块元素一般都从新行开始,它可以容纳内联元素和其他块元素,常见块元素是段落标签'P".“form"这个块元素比较特殊,它只能用来容纳其他块元素. 2.如果没有css的作用,块元素 ...
- go——变量
在数学概念中,变量(variable)表示没有固定值且可以改变的数.但从计算机系统实现角度来看,变量是一段或多段用来存储数据的内存.作为静态类型语言,Go语言总是有固定的数据类型,类型决定了变量内存的 ...
- PySpider HTTP 599: SSL certificate problem错误的解决方法(转)
前言 最近发现许多小伙伴在用 PySpider 爬取 https 开头的网站的时候遇到了 HTTP 599: SSL certificate problem: self signed certific ...
- 微信小程序组件checkbox
表单组件checkbox:官方文档 Demo Code: JS Page({ data:{ items:[ {name: 'USA', value: '美国'}, {name: 'CHN', valu ...
- nginx3
Yum安装更简单.安装并启动keepalived,表示安装成功.有3个进程. etc\keepalived\keepalived.conf: 备的keepalived配置文件: ! Configura ...