Spark 宽窄依赖
面试时被问到spark RDD的宽窄依赖,虽然问题很简单,但是答得很不好。还是应该整理一下描述,这样面试才能答得更好。
看到一篇很好的文章,转载过来了。感觉比《spark技术内幕》这本书讲的好多了。
原文链接:https://www.jianshu.com/p/5c2301dfa360
1.窄依赖
窄依赖就是指父RDD的每个分区只被一个子RDD分区使用,子RDD分区通常只对应常数个父RDD分区,如下图所示【其中每个小方块代表一个RDD Partition】
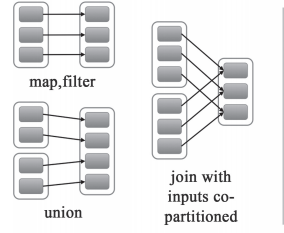
窄依赖有分为两种:
- 一种是一对一的依赖,即OneToOneDependency
- 还有一个是范围的依赖,即RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同
2.宽依赖
宽依赖就是指父RDD的每个分区都有可能被多个子RDD分区使用,子RDD分区通常对应父RDD所有分区,如下图所示【其中每个小方块代表一个RDD Partition】

3.窄依赖与窄依赖比较
- 宽依赖往往对应着shuffle操作,需要在运行的过程中将同一个RDD分区传入到不同的RDD分区中,中间可能涉及到多个节点之间数据的传输,而窄依赖的每个父RDD分区通常只会传入到另一个子RDD分区,通常在一个节点内完成。
- 当RDD分区丢失时,对于窄依赖来说,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重新计算与子RDD分区对应的父RDD分区就行。这个计算对数据的利用是100%的
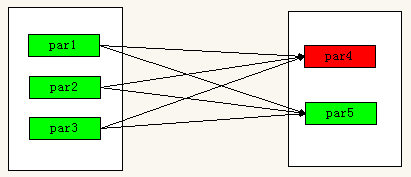
- 当RDD分区丢失时,对于宽依赖来说,重算的父RDD分区只有一部分数据是对应丢失的子RDD分区的,另一部分就造成了多余的计算。宽依赖中的子RDD分区通常来自多个父RDD分区,极端情况下,所有父RDD都有可能重新计算。如下图,par4丢失,则需要重新计算par1,par2,par3,产生了冗余数据par5
4.宽依赖,窄依赖函数
- 窄依赖的函数有:
map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues - 宽依赖的函数有:
groupByKey, join(父RDD不是hash-partitioned ), partitionBy
作者:不圆的石头
链接:https://www.jianshu.com/p/5c2301dfa360
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Spark 宽窄依赖的更多相关文章
- 11、spark内核架构剖析与宽窄依赖
一.内核剖析 1.内核模块 1.Application 2.spark-submit 3.Driver 4.SparkContext 5.Master 6.Worker 7.Executor 8.Jo ...
- Spark RDD基本概念、宽窄依赖、转换行为操作
目录 RDD概述 RDD的内部代码 案例 小总结 转换.行动算子 宽.窄依赖 Reference 本文介绍一下rdd的基本属性概念.rdd的转换/行动操作.rdd的宽/窄依赖. RDD:Resilie ...
- spark rdd 宽窄依赖理解
== 转载 == http://blog.csdn.net/houmou/article/details/52531205 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过 ...
- Spark RDD 宽窄依赖
RDD 宽窄依赖 RDD之间有一系列的依赖关系, 可分为窄依赖和宽依赖 窄依赖 从 RDD 的 parition 角度来看 父 RRD 的 parition 和 子 RDD 的 parition 之间 ...
- 【Spark-core学习之五】 RDD宽窄依赖 & Stage
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark 宽窄依赖和stage的划分
窄依赖 父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的 ...
- 关于spark RDD trans action算子、lineage、宽窄依赖详解
这篇文章想从spark当初设计时为何提出RDD概念,相对于hadoop,RDD真的能给spark带来何等优势.之前本想开篇是想总体介绍spark,以及环境搭建过程,但个人感觉RDD更为重要 铺垫 在h ...
- spark优化——依赖包传入HDFS_spark.yarn.jar和spark.yarn.archive的使用
一.参数说明 启动Spark任务时,在没有配置spark.yarn.archive或者spark.yarn.jars时, 会看到不停地上传jar,非常耗时:使用spark.yarn.archive可以 ...
- 通过 spark.files 传入spark任务依赖的文件源码分析
版本:spak2.3 相关源码:org.apache.spark.SparkContext 在创建spark任务时候,往往会指定一些依赖文件,通常我们可以在spark-submit脚本使用--file ...
随机推荐
- 『浅入浅出』MySQL 和 InnoDB
作为一名开发人员,在日常的工作中会难以避免地接触到数据库,无论是基于文件的 sqlite 还是工程上使用非常广泛的 MySQL.PostgreSQL,但是一直以来也没有对数据库有一个非常清晰并且成体系 ...
- Replay attack 回放攻击
w http://baike.baidu.com/item/重放攻击 重放攻击(Replay Attacks)又称重播攻击.回放攻击或新鲜性攻击(Freshness Attacks),是指攻击者发送一 ...
- Json对象与Json字符串的转化
1.jQuery插件支持的转换方式: $.parseJSON( jsonstr ); //jQuery.parseJSON(jsonstr),可以将json字符串转换成json对象 2.浏览器支持的转 ...
- 第09章—使用Lombok插件
spring boot 系列学习记录:http://www.cnblogs.com/jinxiaohang/p/8111057.html 码云源码地址:https://gitee.com/jinxia ...
- 查找文件路径find
查找文件路径find 1.按照文件名查找 (1)find / -name httpd.conf #在根目录下查找文件httpd.conf,表示在整个硬盘查找 (2)find ...
- 从微观到宏观,遍历网络安全这幅有向图——By Me
“可视化”是网络安全领域的前沿技术与可靠保障.笔者所在的西电捷通是一家领先的网络安全基础技术国际研究机构.一直从事网络安全基础技术研发与技术转移.笔者在2011年底入职典型技术之上的西电捷通公司,那时 ...
- Mysql学习笔记—视图
1.什么是视图 视图(View)是一种虚拟存在的表.其内容与真实的表相似,包含一系列带有名称的列和行数据.但是视图并不在数据库中以存储的数据的形式存在.行和列的数据来自定义视图时查询所引用的基本表,并 ...
- java反射基础知识(四)反射应用实践
反射基础 p.s: 本文需要读者对反射机制的API有一定程度的了解,如果之前没有接触过的话,建议先看一下官方文档的Quick Start. 在应用反射机制之前,首先我们先来看一下如何获取一个对象对应的 ...
- Python(面向对象编程——2 继承、派生、组合、抽象类)
继承与派生 ''' 继承:属于 组合:包含 一. 在OOP程序设计中,当我们定义一个class的时候,可以从某个现有的class继承,新的class称为子类(Subclass),而被继承的class称 ...
- List集合的ForEach扩展
public static void ForEach<T>(this IEnumerable<T> enumerableSource, Action<T&g ...