【系统设计】432. 全 O(1) 的数据结构
题目:
使用栈实现队列的下列操作: push(x) -- 将一个元素放入队列的尾部。
pop() -- 从队列首部移除元素。
peek() -- 返回队列首部的元素。
empty() -- 返回队列是否为空。
注意: 你只能使用标准的栈操作-- 也就是只有push to top, peek/pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque (双端队列) 来模拟一个栈,只要是标准的栈操作即可。
假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
本题解题思路:
思考过程中考虑到可以用两个map来解决该问题,但发现比较麻烦,后自己写了一个解决方案:
核心数据结构:
struct DoubleListNode{
void * val;
DoubleListNode * pre;
DoubleListNode * next;
DoubleListNode(void * x):val(x){
pre = NULL;
next = NULL;
}
};
struct StrToken{
int counter;
set<string> strs;
};
用一个排序的双向链表来存储所有的key和key的计数,数列的计数从小到大。
如果返回最小计数的key,则返回队列中的头元素,如果返回最大计数的key,则返回队列的最末位的元素;
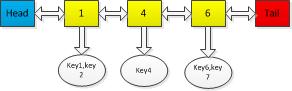
插入元素:
如果发现该key已经存在map中,则找到该节点,将该key插入到其计算加1的链表节点中去,同时更新map映射;如果发现该key不存在,则将该key插入到计算为1的节点中去,同时更新map映射。
删除元素:
如果发现该key已经存在map中,则找到该节点,将该key插入到其计算减一的链表节点中去同时更新MAP映射。
返回最大值:
由于链表是按照计算的大小排列的,返回链表中的最后端的元素即可。
返回最小值:
由于链表是按照计算的大小排列的,返回链表中的最前端的元素即可。
源代码如下,leetcode执行时间为40ms
struct DoubleListNode{
void * val;
DoubleListNode * pre;
DoubleListNode * next;
DoubleListNode(void * x):val(x){
pre = NULL;
next = NULL;
}
};
struct StrToken{
int counter;
set<string> strs;
};
class DoubleLinkList{
public:
DoubleLinkList(){
head = new DoubleListNode(NULL);
tail = new DoubleListNode(NULL);
head->next = tail;
tail->pre = head;
cnt = ;
}
bool insertHead(DoubleListNode * node){
if(NULL == node || NULL == head){
return false;
}
node->next = head->next;
node->pre = head;
head->next->pre = node;
head->next = node;
cnt++;
return true;
}
bool insertTail(DoubleListNode * node){
if(NULL == node || NULL == tail){
return false;
}
node->next = tail;
node->pre = tail->pre;
tail->pre->next = node;
tail->pre = node;
cnt++;
return true;
}
DoubleListNode * getHead(){
return this->head;
}
DoubleListNode * getTail(){
return this->tail;
}
DoubleListNode * getNext(const DoubleListNode * target){
if(NULL == target){
return NULL;
}
return target->next;
}
DoubleListNode * getPrev(const DoubleListNode * target){
if(NULL == target){
return NULL;
}
return target->pre;
}
bool isHead(const DoubleListNode * target){
if(head == target){
return true;
}else{
return false;
}
}
bool isTail(const DoubleListNode * target){
if(tail == target){
return true;
}else{
return false;
}
}
bool deleteTarget(DoubleListNode * node){
if(NULL == node || node == head || node == tail){
return false;
}
if(!node->pre || !node->next){
return false;
}
node->pre->next = node->next;
node->next->pre = node->pre;
node->next = NULL;
node->pre = NULL;
if(node->val){
delete node->val;
node->val = NULL;
}
delete node;
node = NULL;
return true;
}
bool insertBefore(DoubleListNode * target,DoubleListNode * node){
if(NULL == target || NULL == node){
return false;
}
node->pre = target->pre;
node->next = target;
target->pre->next = node;
target->pre = node;
cnt++;
return true;
}
bool insertAfter(DoubleListNode * target,DoubleListNode * node){
if(NULL == target || NULL == node){
return false;
}
node->pre = target;
node->next = target->next;
target->next->pre = node;
target->next = node;
cnt++;
return true;
}
int length(){
return cnt;
}
bool isEmpty(){
if(head->next == tail){
return true;
}else{
return false;
}
}
private:
struct DoubleListNode * head;
struct DoubleListNode * tail;
int cnt;
};
class AllOne {
public:
/** Initialize your data structure here. */
AllOne() {
}
/** Inserts a new key <Key> with value 1. Or increments an existing key by 1. */
void inc(string key) {
if(keyMap.find(key) == keyMap.end()){
/*we wiil insert the first node*/
DoubleListNode * head = keyList.getHead();
DoubleListNode * next = keyList.getNext(head);
StrToken * toke = (StrToken *)(next->val);
/*we will add a new node in to the linklist*/
if(keyList.isEmpty() || (toke != NULL && toke->counter > )){
StrToken * newToke = new StrToken();
newToke->counter = ;
newToke->strs.insert(key);
DoubleListNode * newNode = new DoubleListNode(newToke);
keyList.insertHead(newNode);
keyMap[key] = newNode;
}else{/*we add the key in to the token*/
if( NULL != toke && toke->counter == ){
toke->strs.insert(key);
keyMap[key] = next;
}
}
}else{
map<string,DoubleListNode *>::iterator it = keyMap.find(key);
DoubleListNode * node = it->second;
StrToken * toke = (StrToken *)(node->val);
toke->strs.erase(key);
DoubleListNode * next = keyList.getNext(node);
StrToken * nextToke = NULL;
if(next != keyList.getTail()){
nextToke = (StrToken *)(next->val);
}
if(next == keyList.getTail() ||
(nextToke!=NULL && nextToke->counter > (toke->counter+))){
StrToken * newToke = new StrToken();
newToke->counter = toke->counter+;
newToke->strs.insert(key);
DoubleListNode * newNode = new DoubleListNode(newToke);
keyList.insertAfter(node,newNode);
keyMap[key] = newNode;
}else{
if(nextToke){
nextToke->strs.insert(key);
keyMap[key] = next;
}
}
if(toke->strs.empty()){
keyList.deleteTarget(node);
}
}
//debug();
}
/** Decrements an existing key by 1. If Key's value is 1, remove it from the data structure. */
void dec(string key) {
if(keyMap.find(key) == keyMap.end()){
return;
}
map<string,DoubleListNode *>::iterator it = keyMap.find(key);
DoubleListNode * node = it->second;
StrToken * toke = (StrToken *)(node->val);
toke->strs.erase(key);
DoubleListNode * prev = keyList.getPrev(node);
StrToken * prevToke = NULL;
if(prev != keyList.getHead()){
prevToke = (StrToken *)(prev->val);
}
if(toke->counter > ){
if(prev == keyList.getHead() ||
(prevToke!=NULL && prevToke->counter < (toke->counter - ))){
StrToken * newToke = new StrToken();
newToke->counter = toke->counter - ;
newToke->strs.insert(key);
DoubleListNode * newNode = new DoubleListNode(newToke);
keyList.insertBefore(node,newNode);
keyMap[key] = newNode;
}else{
if(prevToke){
prevToke->strs.insert(key);
keyMap[key] = prev;
}
}
}else{
keyMap.erase(key);
}
if(toke->strs.empty()){
keyList.deleteTarget(node);
}
//debug();
}
/** Returns one of the keys with maximal value. */
string getMaxKey() {
string res;
if(keyList.isEmpty()){
return res;
}
DoubleListNode * node = keyList.getPrev(keyList.getTail());
StrToken * toke = (StrToken *)(node->val);
return *(toke->strs.begin());
}
/** Returns one of the keys with Minimal value. */
string getMinKey() {
string res;
if(keyList.isEmpty()){
return res;
}
DoubleListNode * node = keyList.getNext(keyList.getHead());
StrToken * toke = (StrToken *)(node->val);
return *(toke->strs.begin());
}
void debug(){
cout<<endl;
DoubleListNode * node = keyList.getNext(keyList.getHead());
for(;node!=keyList.getTail();node = keyList.getNext(node)){
StrToken * toke = (StrToken *)(node->val);
cout<<"cnt:"<<toke->counter<<endl;
set<string>::iterator it = toke->strs.begin();
for(;it!=toke->strs.end();++it){
cout<<*it<<" ";
}
cout<<endl;
}
}
private:
map<string,DoubleListNode *> keyMap;
DoubleLinkList keyList;
};
/**
* Your AllOne object will be instantiated and called as such:
* AllOne obj = new AllOne();
* obj.inc(key);
* obj.dec(key);
* string param_3 = obj.getMaxKey();
* string param_4 = obj.getMinKey();
*/
【系统设计】432. 全 O(1) 的数据结构的更多相关文章
- Java实现 LeetCode 432 全 O(1) 的数据结构
432. 全 O(1) 的数据结构 实现一个数据结构支持以下操作: Inc(key) - 插入一个新的值为 1 的 key.或者使一个存在的 key 增加一,保证 key 不为空字符串. Dec(ke ...
- [LeetCode] All O`one Data Structure 全O(1)的数据结构
Implement a data structure supporting the following operations: Inc(Key) - Inserts a new key with va ...
- leetcode难题
4 寻找两个有序数组的中位数 35.9% 困难 10 正则表达式匹配 24.6% 困难 23 合并K个排序链表 47.4% 困难 25 K ...
- C#LeetCode刷题-设计
设计篇 # 题名 刷题 通过率 难度 146 LRU缓存机制 33.1% 困难 155 最小栈 C#LeetCode刷题之#155-最小栈(Min Stack) 44.9% 简单 173 二叉搜索 ...
- Pandas_基础_全
Pandas基础(全) 引言 Pandas是基于Numpy的库,但功能更加强大,Numpy专注于数值型数据的操作,而Pandas对数值型,字符串型等多种格式的表格数据都有很好的支持. 关于Numpy的 ...
- Python全栈之路----目录
Module1 Python基本语法 Python全栈之路----编程基本情况介绍 Python全栈之路----常用数据类型--集合 Module2 数据类型.字符编码.文件操作 Python全栈之路 ...
- 《数据结构-C语言版》(严蔚敏,吴伟民版)课本源码+习题集解析使用说明
<数据结构-C语言版>(严蔚敏,吴伟民版)课本源码+习题集解析使用说明 先附上文档归类目录: 课本源码合辑 链接☛☛☛ <数据结构>课本源码合辑 习题集全解析 链接☛☛☛ ...
- 9-11-Trie树/字典树/前缀树-查找-第9章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第9章 查找 - Trie树/字典树/前缀树(键树) ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版>(严蔚 ...
- 9-9-B+树-查找-第9章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第9章 查找 - B+树 ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版>(严蔚敏,吴伟民版)课本源码+习题 ...
随机推荐
- Qt-QML-ComboBox-自定义,实现状态表示,内容可以动态正价,使用ListModel
哎呀呀呀, 问:杀死一个程序员一个程序要需要进步? 答:改三次需求 我感觉我就要再这需求的变更中被杀死了.不管怎么说,总是要跟着需求走的的,客户才是第一么(要不是因为钱,我才不会了) 下面先上个效果 ...
- 【label】标签组件说明
label标签组件 用来改进表单组件的可用性,使用for属性找到对应的id,或者将控件放在该标签下,当点击时,就会触发对应的控件.目前可以绑定的控件有:<button/>, <che ...
- 一些容易记混的c++相关知识点
一些容易记混的c++相关知识. 截图自:<王道程序员面试宝典>
- JS中通过数组的方式操作字符串 数组是个好东西 ....
题目:使用JS将 var str="what are you nong sha lei",通过您的方法转换为"What Are You Nong Sha Lei" ...
- 刷ROM必備的clockworkmod recovery
Desire HD 手機早早就 Root,前陣子也S-OFF 變成工程版的 HBOOT(ENG S-OFF),想要刷機的朋友一定常常聽人提起 clockworkmod recovery ,接下來就是安 ...
- [solution]xdebug正确配置,但不显示错误信息
一开始以为是配置问题,其实不是,折腾了好久,貌似中文网页很少有人提到这事,更别提解决之道! 最好还是用英文关键词google之:得如下网页 https://bugs.launchpad.net/ubu ...
- Linux的ll命令详解
ll 列出来的结果详细,有时间,是否可读写等信息 ,象windows里的 详细信息 ls 只列出文件名或目录名 就象windows里的 列表 ll -t 是降序, ll -t | tac 是升序 l ...
- python学习笔记02:运行python程序
1.启动cmd命令行,输入python后回车,运行python解释器: 输入python代码后回车: print('Hello World')
- 敏捷冲刺Day1
前言: 之前的各种对教务系统的分析,再加上我们两三天的讨论和一个小时的站立会议,我们做出最终的决定.--我们决定换个项目主题,将原来的教务辅助系统换成现在的校园帮帮帮服务,并在之后会将完成后的计划书附 ...
- centos7 安装 httpd并打开测试页
systemctl start firewalld.service#启动firewallsystemctl stop firewalld.service#停止firewallsystemctl dis ...