再论EM算法的收敛性和K-Means的收敛性
标签(空格分隔): 机器学习
(最近被一波波的笔试+面试淹没了,但是在有两次面试时被问到了同一个问题:K-Means算法的收敛性。在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Means与EM算法的关系,以及EM算法本身的收敛性证明中找到蛛丝马迹,下次不要再掉坑啊。。)
EM算法的收敛性
1.通过极大似然估计建立目标函数:
\(l(\theta) = \sum_{i=1}^{m}log\ p(x;\theta) = \sum_{i=1}^{m}log\sum_{z}p(x,z;\theta)\)
通过EM算法来找到似然函数的极大值,思路如下:
希望找到最好的参数\(\theta\),能够使最大似然目标函数取最大值。但是直接计算 \(l(\theta) = \sum_{i=1}^{m}log\sum_{z}p(x,z;\theta)\)比较困难,所以我们希望能够找到一个不带隐变量\(z\)的函数\(\gamma(x|\theta) \leq l(x,z;\theta)\)恒成立,并用\(\gamma(x|\theta)\)逼近目标函数。
如下图所示:
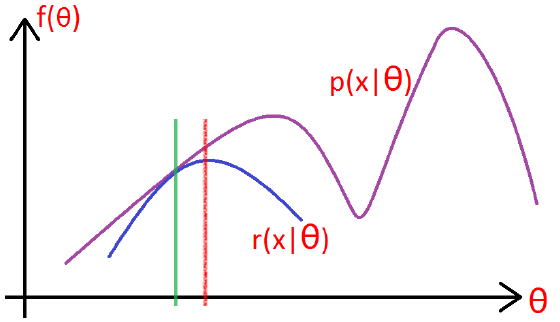
- 在绿色线位置,找到一个\(\gamma\)函数,能够使得该函数最接近目标函数,
- 固定\(\gamma\)函数,找到最大值,然后更新\(\theta\),得到红线;
- 对于红线位置的参数\(\theta\):
- 固定\(\theta\),找到一个最好的函数\(\gamma\),使得该函数更接近目标函数。
重复该过程,直到收敛到局部最大值。
2. 从Jensen不等式的角度来推导
令\(Q_{i}\)是\(z\)的一个分布,\(Q_{i} \geq 0\),则:
$l(\theta) = \sum_{i=1}^{m}log\sum_{z^{(i)}}p(x^{(i)},z^{(i)};\theta) $
$ = \sum_{i=1}^{m}log\sum_{z^{(i)}}Q_{i}(z^{(i)})\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}$
\(\geq \sum_{i=1}^{m}\sum_{z^{(i)}}Q_{i}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}\)
(对于log函数的Jensen不等式)
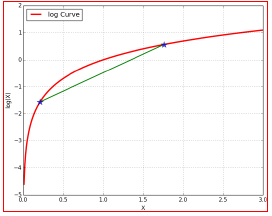
3.使等号成立的Q
尽量使\(\geq\)取等号,相当于找到一个最逼近的下界:也就是Jensen不等式中,\(\frac{f(x_{1})+f(x_{2})}{2} \geq f(\frac{x_{1}+x_{2}}{2})\),当且仅当\(x_{1} = x_{2}\)时等号成立(很关键)。
对于EM的目标来说:应该使得\(log\)函数的自变量恒为常数,即:
\(\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})} = C\)
也就是分子的联合概率与分母的z的分布应该成正比,而由于\(Q\)是z的一个分布,所以应该保证\(\sum_{z}Q_{i}(z^{(i)}) = 1\)
故\(Q = \frac{p}{p对z的归一化因子}\)
\(Q_{i}(z^{(i)}) = \frac{p(x^{(i)},z^{(i)};\theta)}{\sum_{z}p(x^{(i)},z^{(i)};\theta)}\)
\(= \frac{p(x^{(i)},z^{(i)};\theta)}{p(x^{(i)};\theta)} = p(z^{(i)}|x^{(i)};\theta)\)
4.EM算法的框架
由上面的推导,可以得出EM的框架:
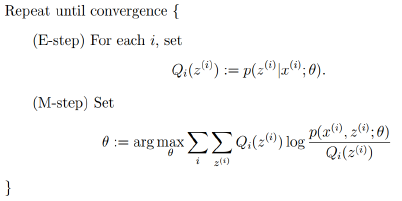
回到最初的思路,寻找一个最好的\(\gamma\)函数来逼近目标函数,然后找\(\gamma\)函数的最大值来更新参数\(\theta\):
- E-step: 根据当前的参数\(\theta\)找到一个最优的函数\(\gamma\)能够在当前位置最好的逼近目标函数;
- M-step: 对于当前找到的\(\gamma\)函数,求函数取最大值时的参数\(\theta\)的值。
K-Means的收敛性
通过上面的分析,我们可以知道,在EM框架下,求得的参数\(\theta\)一定是收敛的,能够找到似然函数的最大值。那么K-Means是如何来保证收敛的呢?
目标函数
假设使用平方误差作为目标函数:
\(J(\mu_{1},\mu_{2},...,\mu_{k}) = \frac{1}{2}\sum_{j=1}^{K}\sum_{i=1}^{N}(x_{i}-\mu_{j})^{2}\)
E-Step
固定参数\(\mu_{k}\), 将每个数据点分配到距离它本身最近的一个簇类中:
\[
\gamma_{nk} =
\begin{cases}
1, & \text{if $k = argmin_{j}||x_{n}-\mu_{j}||^{2}$ } \\
0, & \text{otherwise}
\end{cases}
\]
M-Step
固定数据点的分配,更新参数(中心点)\(\mu_{k}\):
\(\mu_{k} = \frac{\sum_{n}\gamma_{nk}x_{n}}{\sum_{n}\gamma_{nk}}\)
所以,答案有了吧。为啥K-means会收敛呢?目标是使损失函数最小,在E-step时,找到一个最逼近目标的函数\(\gamma\);在M-step时,固定函数\(\gamma\),更新均值\(\mu\)(找到当前函数下的最好的值)。所以一定会收敛了~
再论EM算法的收敛性和K-Means的收敛性的更多相关文章
- EM算法总结
EM算法总结 - The EM Algorithm EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用 ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...
- 机器学习之高斯混合模型及EM算法
第一部分: 这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类 ...
- EM算法【转】
混合高斯模型和EM算法 这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与K-means一样,给定的训练样本是, ...
- 【转】EM算法原理
EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用到了.在Mitchell的书中也提到EM可以用于贝叶 ...
- EM 算法求解高斯混合模型python实现
注:本文是对<统计学习方法>EM算法的一个简单总结. 1. 什么是EM算法? 引用书上的话: 概率模型有时既含有观测变量,又含有隐变量或者潜在变量.如果概率模型的变量都是观测变量,可以直接 ...
- EM算法原理详解
1.引言 以前我们讨论的概率模型都是只含观测变量(observable variable), 即这些变量都是可以观测出来的,那么给定数据,可以直接使用极大似然估计的方法或者贝叶斯估计的方法:但是当模型 ...
- EM算法及其推广
概述 EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计. EM算法的每次迭代由两步组成:E步,求期望(expectation): ...
- EM算法定义及推导
EM算法是一种迭代算法,传说中的上帝算法,俗人可望不可及.用以含有隐变量的概率模型参数的极大似然估计,或极大后验概率估计 EM算法定义 输入:观测变量数据X,隐变量数据Z,联合分布\(P(X,Z|\t ...
随机推荐
- Win7旗舰版中的IIS配置asp.net的运行环境
Win7旗舰版中的IIS配置asp.net的运行环境 以前弄过好多次,都没有成功,昨天晚上不知怎么地就成功了,借用我同学的一句话,这叫“灵光一闪”,废话不多说了,这个成功是有图有视频有真相地哈! ...
- Android开机自启动程序
背景知识:当Android启动时,会发出一个系统广播,内容为ACTION_BOOT_COMPLETED,它的字符串常量表示为 android.intent.action.BOOT_COMPLETED. ...
- Install Sogou IM 2.0 in Ubuntu14.04+/Xfce
Ubuntu14.04+ 安装搜狗输入法 搜狗输入法是一款非常友好的输入法产品,从Ubuntu14.04开始对Linux支持,不过只是Debian系的,是Ubuntu优麒麟组引入的.优麒麟是针对国人设 ...
- 如何查看Linux操作系统版本
1. 查看内核版本命令: 360kb.com:~> cat /proc/version Linux version 2.6.32-358.el6.x86_64 (mockbuild@c6b8.b ...
- 修改Linux时间一般涉及到3个命令: date, clock, hwclock
原贴:http://203.208.37.104/search?q=cache:p1vAAHvs9ikJ:www.goldthe.com /blog/%3Faction%3Dshowlog%26gid ...
- tar+gzip
tar打gzip包: tar -czvf sourceDir.tar.gz sourceDir tar查看压缩包内容: tar -tvf sourceDir.tar.gz tar解压缩包crontab ...
- PHP array_column() 函数
定义和用法 array_column() 返回输入数组中某个单一列的值. array_column(array,column_key,index_key); 参数 描述 array 必需.规定要使用的 ...
- Codeforces 733C:Epidemic in Monstropolis(暴力贪心)
http://codeforces.com/problemset/problem/733/C 题意:给出一个序列的怪兽体积 ai,怪兽只能吃相邻的怪兽,并且只有体积严格大于相邻的怪兽才能吃,吃完之后, ...
- 在ecshop顶部会员信息提示区显示会员等级
会员登陆后,在顶部会员信息提示区显示会员等级会员登陆后会在顶部出现这样的提示:您好,test2, 欢迎您回来 ! 进入用户中心 |退出现在设想在会员名后面加上“会员等级”效果如下:您好,test2, ...
- easyui enableFilter combobox级联 combotree
//网格过滤 function datagridFilter(dg){ dg.datagrid('enableFilter'); dg. ...