kafka基础知识梳理
一.Kafka的基本概念
关键字: 分布式发布订阅消息系统;分布式的,分区的消息服务
Kafka是一种高吞吐量的分布式发布订阅消息系统,使用Scala编写。
对于熟悉JMS(Java Message Service)规范的同学来说,消息系统已经不是什么新概念了(例如ActiveMQ,RabbitMQ等)。
Kafka拥有作为一个消息系统应该具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。
二.基础的消息(Message)相关术语
1.Topic
Kafka按照Topic分类来维护消息
2.Producer
我们将发布(publish)消息到Topic的进程称之为生产者(producer)
3.Consumer
我们将订阅(subscribe)Topic并且处理Topic中消息的进程称之为消费者(consumer)
4.Broker
Kafka以集群的方式运行,集群中的每一台服务器称之为一个代理(broker)。
因此,从一个较高的层面上来看,producers通过网络发送消息到Kafka集群,然后consumers来进行消费,如下图
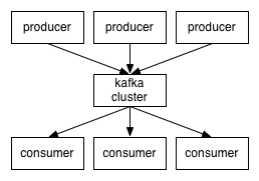
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。我们为Kafka提供了一个Java客户端,但是也可以使用其他语言编写的客户端。
5.Topic和Log
我们首先深入理解Kafka提出一个高层次的抽象概念-Topic。
可以理解Topic是一个类别的名称,所有的message发送到Topic下面。对于每一个Topic,kafka集群按照如下方式维护一个分区(Partition,可以就理解为一个队列Queue)日志文件:
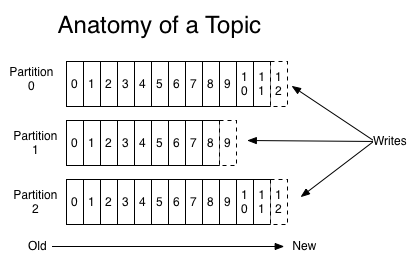
6.partition
partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
提示:每个partition,都对应一个commit-log。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
6.1 对log进行分区的目的
对log进行分区(partitioned),有以下目的。首先,当log文件大小超过系统文件系统的限制时,可以自动拆分。每个partition对应的log都受到所在机器的文件系统大小的限制,但是一个Topic中是可以有很多分区的,因此可以处理任意数量的数据。另一个方面,是为了提高并行度。
7.offset
7.1 consumer有自己的offset
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,offset由consumer来维护:一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,对于集群或者其他consumer来说,都是没有影响的,因此每个consumer维护各自的offset。
8.Distribution
log的partitions分布在kafka集群中不同的broker上,每个broker可以请求备份其他broker上partition上的数据。kafka集群支持配置一个partition备份的数量。
针对每个partition,都有一个broker起到“leader”的作用,0个多个其他的broker作为“follwers”的作用。leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。每个broker都是自己所管理的partition的leader,同时又是其他broker所管理partitions的followers,kafka通过这种方式来达到负载均衡。
9.Producers
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡。也可以根据消息中的某一个关键字来进行区分。通常第二种方式使用的更多。
10.Consumers
consumer实例可以运行在不同的进程上,也可以在不同的物理机器上。
如果所有的consumer都位于同一个consumer group 下,这就类似于传统的queue模式,并在众多的consumer instance之间进行负载均衡。
10.1 consumer group概念
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
每个consumer都要标记自己属于哪一个consumer group。
如果所有的consumer都有着自己唯一的consumer group,这就类似于传统的publish-subscribe模型。
10.2 队列(queuing)模式
在queuing模式中,多个consumer从服务器中读取数据,消息只会到达一个consumer。
10.3 发布订阅(publish-subscribe)模式
在 publish-subscribe模型中,消息会被广播给所有的consumer。
通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者(logical subscriber)。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。这并没有什么特殊的地方,仅仅是将publish-subscribe模型中的运行在单个进程上的consumers中的consumer替换成一个consumer group。如下图所示
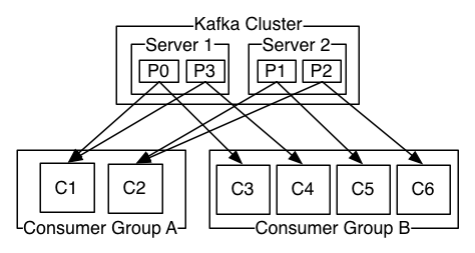
说明:由2个broker组成的kafka集群,总共有4个Parition(P0-P3)。这个集群由2个Consumer Group, A有2个 consumer instances ,而B有四个
三.Kafka的消费顺序
Kafka比传统的消息系统有着更强的顺序保证。
在传统的情况下,服务器按照顺序保留消息到队列,如果有多个consumer来消费队列中的消息,服务器 会接受消息的顺序向外提供消息。但是,尽管服务器是按照顺序提供消息,但是消息传递到每一个consumer是异步的,这可能会导致先消费的consumer获取到消息时间可能比后消费的consumer获取到消息的时间长,导致不能保证顺序性。这表明,当进行并行的消费的时候,消息在多个 consumer之间可能会失去顺序性。
消息系统通常会采取一种“exclusive consumer”的概念,来确保同一时间内只有一个consumer能够从队列中进行消费,但是这实际上意味着在消息处理的过程中是不支持并行的。
Kafka partition保证局部顺序
Kafka比传统方式做得更好:通过Topic中并行度的概念,即partition,Kafka可以同时提供顺序性保证和多个consumer同时消费时的负载均衡。
实现的原理是通过将一个topic中的partition分配给一个consumer group中的不同consumer instance。通过这种方式,我们可以保证一个partition在同一个时刻只有一个consumer instance在消息,从而保证顺序。虽然一个topic中有多个partition,但是一个consumer group中同时也有多个consumer instance,通过合理的分配依然能够保证负载均衡。需要注意的是,一个consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。通常来说,这已经可以满足大部分应用的需求。但是,如果的确有在总体上保证消费的顺序的需求的话,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1.
kafka基础知识梳理的更多相关文章
- kafka 基础知识梳理及集群环境部署记录
一.kafka基础介绍 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特 ...
- kafka 基础知识梳理-kafka是一种高吞吐量的分布式发布订阅消息系统
一.kafka 简介 今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何及时做到如上两点 ...
- kafka 基础知识梳理
一.kafka 简介 kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据.这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因 ...
- kafka 基础知识梳理(转载)
一.kafka 简介 kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据.这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因 ...
- [SQL] SQL 基础知识梳理(一)- 数据库与 SQL
SQL 基础知识梳理(一)- 数据库与 SQL [博主]反骨仔 [原文地址]http://www.cnblogs.com/liqingwen/p/5902856.html 目录 What's 数据库 ...
- [SQL] SQL 基础知识梳理(二) - 查询基础
SQL 基础知识梳理(二) - 查询基础 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5904824.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(三) - 聚合和排序
SQL 基础知识梳理(三) - 聚合和排序 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5926689.html 序 这是<SQL 基础知识梳理 ...
- [SQL] SQL 基础知识梳理(四) - 数据更新
SQL 基础知识梳理(四) - 数据更新 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5929786.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(五) - 复杂查询
SQL 基础知识梳理(五) - 复杂查询 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5939796.html 序 这是<SQL 基础知识梳理( ...
随机推荐
- layui中的多图上传
效果展示: 1.html部分: 注:<input> 作为隐藏域,用于保存多图上传的资源数组,方便后期进行 form 表单的提交 <input type="hidden&qu ...
- 百度地图api根据用户IP获取用户位置(PHP)
1.百度地图开放平台找的你的ak ,链接:http://lbsyun.baidu.com/apiconsole/key 2.获取用户ip地址(外网ip 服务器上可以获取用户外网Ip 本机ip地址只能获 ...
- .NET 平台系列6 .NET Core 发展历程
系列目录 [已更新最新开发文章,点击查看详细] 在我的上一篇博客<.NET平台系列5 .NET Core 简介>中主要介绍了.NETCore的基本情况,主要包括.NET跨平台的缘由 ...
- Windows 程序自动更新方案: Squirrel.Windows
Windows 程序自动更新方案: Squirrel.Windows 1. Squirrel Squirrel 是一组工具和适用于.Net的库,用于管理 Desktop Windows 应用程序的安装 ...
- 软负载Nginx和硬负载F5的优缺点对比
对于数据流量过大的网络中,往往单一设备无法承担,需要多台设备进行数据分流,而负载均衡器就是用来将数据分流到多台设备的一个转发器. a.软件负载均衡解决方案 在一台服务器的操作系统上,安装一个附加软件 ...
- [bug] IDEA编译时出现 Information:java: javacTask: 源发行版 1.8 需要目标发行版 1.8
原因 jdk版本选低了 解决 将以下几处jdk版本修改为1.8 Project Structure(File->Project Structure...)>Sources>Langu ...
- 强哥memcache学习笔记
搭建memcache服务器:1.在内存中缓存数据2.数据形态以key->value memcache优点:1.快速缓存2.跨域登录memcache缺点:1.复杂的数据存取的操作2.不能永久保存数 ...
- centOS 7 安装 CUPS 打印服务器,安装映美 FP-730K打印机共享
centOS 7 安装 CUPS 打印服务器,安装映美 FP-730K打印机共享 2017-09-13 16:27:02 mostone 阅读数 3698 版权声明:本文为博主原创文章,遵循CC ...
- 012.Ansible高级特性
一 本地执行 如果希望在控制主机本地运行一个特定的任务,可以使用local_action语句. 假设我们需要配置的远程主机刚刚启动,如果我们直接运行playbook,可能会因为sshd服务尚未开始监听 ...
- Linux_配置加密的https
一.配置https 1.安装好httpd服务后,安装mod_ssl模块 //首先查看是否安装mod_ssl [root@localhost ~]# rpm -qa | grep mod_ssl //安 ...