Mplus数据分析:随机截距交叉之后的做法和如何加协变量,写给粉丝
记得之前有写过如何用R做随机截距交叉滞后,有些粉丝完全是R小白,还是希望我用mplus做,今天就给大家写写如何用mplus做随机截距交叉滞后。
做之前我们需要知道一些Mplus的默认的设定:
- observed and latent exogenous variables are correlated, and
- residuals of observed and latent outcome variables (which do not predict anything) in a path model are correlated.
这些设定可以帮助我们更容易地设定结构方程模型,但是在做随机截距交叉滞后模型的时候我们需要变化一下,此时需要在语法中加上ANALYSIS: MODEL = NOCOV;
用mplus做随机截距交叉滞后需要规定4个部分:
- 因素间部分,就是随机截距,用BY来设置,写出RIx BY x1@1 x2@1 ...这样的形式,其中@1表示固定为1的意思,这个是做随机效应交叉滞后的默认操作
- 因素内部分的内在波动,也是用BY来设定,写出wx1 BY x1; wx2 BY x2; ....这样的形式,同时需要将误差方差固定为0
- 交叉滞后部分,写出wx2 ON wx1 wy1; wx3 ON wx2 wy2; ....这样的形式
- 内外共变部分,因素内写出wx1 WITH wy1; wx2 WITH wy2;....这样的形式;因素外写出RIx WITH RIy的形式。
所以一个基本的随机截距交叉滞后的代码就是如下:
MODEL: ! 随机截距
RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;
RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;
! 因素内
wx1 BY x1@1;
wx2 BY x2@1;
wx3 BY x3@1;
wx4 BY x4@1;
wx5 BY x5@1;
wy1 BY y1@1;
wy2 BY y2@1;
wy3 BY y3@1;
wy4 BY y4@1;
wy5 BY y5@1;
! 误差方差为0
x1-y5@0;
! 交叉滞后
wx2 wy2 ON wx1 wy1;
wx3 wy3 ON wx2 wy2;
wx4 wy4 ON wx3 wy3;
wx5 wy5 ON wx4 wy4;
! 随机截距相关
RIx WITH RIy;
!组内相关
wx1 WITH wy1;
wx2 WITH wy2;
wx3 WITH wy3;
wx4 WITH wy4;
wx5 WITH wy5; 加协变量
一般情况下我们在重复测量之前都会收集一般人口学特征等等协变量,在做分析的时候我们也会有控制协变量的需求,此处我们是有两个选择,一个是把协变量在显变量水平(左图),另外一个是将协变量控制在随机截距水平(右图):
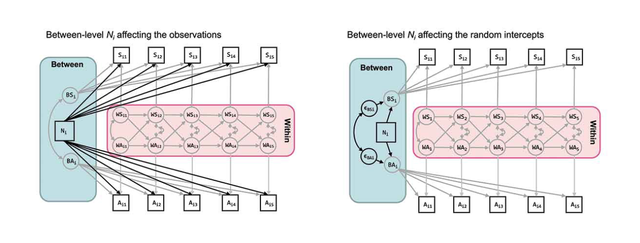
控制在显变量水平的意思就是说我这些变量对模型的作用都是对每一波测量都有的,在协变量不变的情况下来从整体上拟合我们的模型,比如我现在有一个协变量Z我就可以写出代码如下:
MODEL: ! 随机截距
RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;
RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;
RIx WITH RIy;
wx1 BY x1@1;
wx2 BY x2@1;
wx3 BY x3@1;
wx4 BY x4@1;
wx5 BY x5@1;
wy1 BY y1@1;
wy2 BY y2@1;
wy3 BY y3@1;
wy4 BY y4@1;
wy5 BY y5@1;
x1-y5@0;
! 协变量添加
x1-x5 ON z1 (s1);
y1-y5 ON z1 (s2);
wx2 wy2 ON wx1 wy1;
wx3 wy3 ON wx2 wy2;
wx4 wy4 ON wx3 wy3;
wx5 wy5 ON wx4 wy4;
wx1 WITH wy1;
wx2 WITH wy2;
wx3 WITH wy3;
wx4 WITH wy4;
wx5 WITH wy5;控制在放在随机截距的意思就是说这个显变量是影响了个体差异进而影响整个模型,这个是在探究between-difference的影响的时候用的,此时我们的代码如下:
MODEL:
RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;
RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;
RIx WITH RIy;
wx1 BY x1@1;
wx2 BY x2@1;
wx3 BY x3@1;
wx4 BY x4@1;
wx5 BY x5@1;
wy1 BY y1@1;
wy2 BY y2@1;
wy3 BY y3@1;
wy4 BY y4@1;
wy5 BY y5@1;
x1-y5@0;
! 协变量添加语法
RIx RIy ON z1;
wx2 wy2 ON wx1 wy1;
wx3 wy3 ON wx2 wy2;
wx4 wy4 ON wx3 wy3;
wx5 wy5 ON wx4 wy4;
wx1 WITH wy1;
wx2 WITH wy2;
wx3 WITH wy3;
wx4 WITH wy4;
wx5 WITH wy5;运行上面的代码我们的带协变量的随机截距交叉滞后就出来了,然后我们点击view diagram还可以看自动生成的路径图
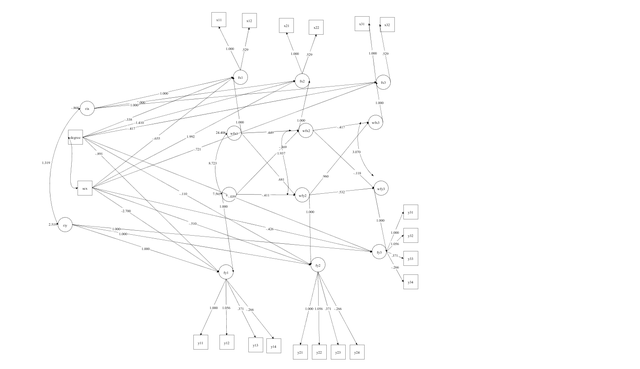
自己生成的就是乱糟糟一团,然后点击图中的各个节点都是可以调整的,下图是给一个同学做的多个显变量的随机截距交叉滞后模型,模型中控制了两个协变量sex和degree,然后下图就是mplus自动生成的模型图,调整调整还是能看的,这个模型是将协变量控制在显变量水平的:
多组比较建模
多组比较的意思就是看看路径系数或者载荷,在某个变量的组间是不是一样,内在原理是将模型分组拟合,然后比较固定两组路径相等的模型拟合优度和两组自由估计的优度之间的差异,如果路径相等的模型并没有显著差于自由估计的模型就可以认为组间无差异,常见的应用就是在量表的跨文化调试中,比如你想看看英文和中文的量表有没有差异,你就可以尝试进行多组比较建模:
Multigroup models test separate models in two or more discrete groups. Equality constraints across groups are used to conduct nested tests using likelihood ratio comparisons between a model with certain parameters constrained to be equal and a model with those same parameters freely estimated (allowed to differ) across the groups. For example, one can investigate whether means, predictive paths, or loadings differ across two nationalities.
做多组比较的时候,我们也需要修改一些mplus的默认设定,在默认设定中,显变量的截距在组间是等价的;潜变量的均值是自由估计的,我们在做多组比较模型的时候需要估计的参数其实变多了,所以我们需要将显变量的截距自由估计和将潜变量的均值固定从而释放更多的自由度。
如果我们要依照某个变量比如说group这个变量进行多组比较,我就可以在variable参数中加上grouping,写出代码如下,如果我们想直接比较某两个参数,我们可以用model test语法,然后结果中就会输出系数的组间检验,比如下面的代码就是在比较两组间随机截距的相关是不是一样:
VARIABLE: NAMES = x1-x5 y1-y5 GROUP;
GROUPING = GROUP (1=G1 2=G2);
MODEL: ! 随机截距部分
RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;
RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;
! 测量误差
wx1 BY x1@1;
wx2 BY x2@1;
wx3 BY x3@1;
wx4 BY x4@1;
wx5 BY x5@1;
wy1 BY y1@1;
wy2 BY y2@1;
wy3 BY y3@1;
wy4 BY y4@1;
wy5 BY y5@1;
x1-y5@0;
! 交叉滞后系数
wx2 wy2 ON wx1 wy1;
wx3 wy3 ON wx2 wy2;
wx4 wy4 ON wx3 wy3;
wx5 wy5 ON wx4 wy4;
! 随机截距共变
RIx WITH RIy(a);
! 同一波次的相关
wx1 WITH wy1;
wx2 WITH wy2;
wx3 WITH wy3;
wx4 WITH wy4;
wx5 WITH wy5;
MODEL G2:
RIx WITH RIy(b);
model test:
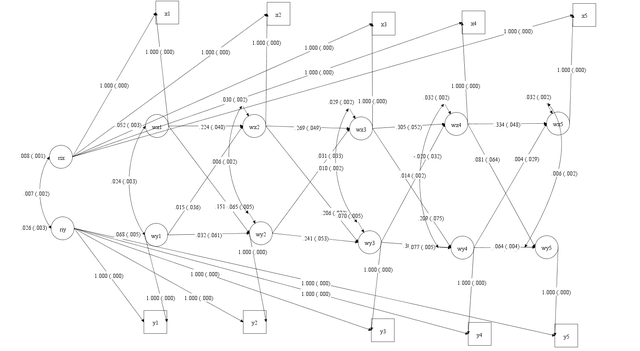
a = b;上面的代码的意思就是在运行上面的代码就可以出多组比较的结果了:
结果中会有系数比较的结果,说明两组间我们的系数(随机截距的相关)是有显著差异的:

以上就是今天给大家分享的在随机截距交叉滞后中控制协变量以及如何做组间系数比较,希望对大家有所启发。
上面的所有操作都是可以在R语言中进行的,不过有做这个模型需求的大多数同学还是用mplus多,所以出了一期mplus,希望可以帮助到大家。之后会给大家写R的操作。
小结
今天给大家写了随机截距交叉滞后的mplus做法,包括如何添加协变量,以及如何进行多组比较,希望对大家有启发,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,另欢迎私信。
Mplus数据分析:随机截距交叉之后的做法和如何加协变量,写给粉丝的更多相关文章
- mplus数据分析:增长模型潜增长模型与增长混合模型再解释
混合模型,增长混合模型这些问题咨询的同学还是比较多的,今天再次尝试写写它们的区别,希望对大家进一步理解两种做轨迹的方法有帮助. 首先,无论是LCGA还是GMM,它们都是潜增长模型的框框里面的东西: L ...
- R数据分析:生存分析与有竞争事件的生存分析的做法和解释
今天被粉丝发的文章给难住了,又偷偷去学习了一下竞争风险模型,想起之前写的关于竞争风险模型的做法,真的都是皮毛哟,大家见笑了.想着就顺便把所有的生存分析的知识和R语言的做法和论文报告方法都给大家梳理一遍 ...
- Mysql命令-以NULL做where条件过滤时应该写 IS NULL;
以NULL做where条件过滤时应该写 IS NULL;SELECT * FROM pet WHERE death IS NULL; SELECT * FROM pet WHERE death IS ...
- IM推送保障及网络优化详解(二):如何做长连接加推送组合方案
对于移动APP来说,IM功能正变得越来越重要,它能够创建起人与人之间的连接.社交类产品中,用户与用户之间的沟通可以产生出更好的用户粘性. 在复杂的 Android 生态环境下,多种因素都会造成消息推送 ...
- R随机森林交叉验证 + 进度条
library(data.table) library(randomForest) data <- iris str(data) #交叉验证,使用rf预测sepal.length k = 5 d ...
- 在js中做数字字符串加0补位,效率分析
分类: Jquery/YUI/ExtJs 2010-08-30 11:27 2700人阅读 评论(0) 收藏 举报 functiondate算法语言c 通常遇到的一个问题是日期的“1976-02-03 ...
- Ajax做列表无限加载和Ajax做二级下拉选项
//栏目Ajax做加载 public function ajaxlist(){ //echo "http://www.域名.com/index.php?a=Index&c=Index ...
- POJ3246-Balanced Lineup,好经典的题,做法和HDU-I hate it 一样~~
Balanced Lineup Time Limit: 5000MS Memory Limit: 65536K Case Time Limit: 2000MS Description For ...
- 【CSS】333- 使用CSS自定义属性做一个前端加载骨架
点击上方"前端自习课"关注,学习起来~ 我们在打开APP或者网站的时候,经常可以看到这样的效果,在内容加载完成之前,会有一个骨架动画的出现,这种加载方式比传统的进度条方式要友好的多 ...
随机推荐
- Vue组件间的数据传输
1.父组件向子组件传输数据:自定义属性 1 //父组件 2 <Son :msg="message" :user="userinfo"></So ...
- Java实现四大基本排序算法和二分查找
Java 基本排序算法 二分查找法 二分查找也称为折半查找,是指当每次查询时,将数据分为前后两部分,再用中值和待搜索的值进行比较,如果搜索的值大于中值,则使用同样的方式(二分法)向后搜索,反之则向前搜 ...
- 解决Vite-React项目中js使用jsx语法报错的问题
背景 在做存量项目接入Vite测试时发现,存量(老)项目中很多是直接在js中书写jsx语法,使用Vite启动时就会抛出一堆问题Failed to parse source. 不嫌麻烦可以跑个脚本批量修 ...
- ssh 批量免密登陆
SSH第一次连接远程主机 公钥交换原理 1.客户端发起链接请求2.服务端返回自己的公钥,以及一个会话ID(这一步客户端得到服务端公钥)3.客户端生成密钥对4.客户端用自己的公钥异或会话ID,计算出一个 ...
- 题解 Crash 的文明世界
题目传送门 题目大意 给出一个\(n\)个点的树,和常数\(k\),对于\(\forall i\in[1,n]\),求出: \[\sum_{j=1}^{n} \text{dist}(i,j)^k \] ...
- python中列表和元组的区别
列表(list)特点: 1.可变类型且有序的,有索引值. 元组特点: 1.不可变类型且有序的,通过下标索引值访问 2.元组里面只有一个元素的时候该元组类型就是这个元素的类型.例如:t=(1) t的类型 ...
- 随机生成文章的AI(C++)
#include <iostream> #include <cstdlib> #include <ctime> #include <fstream> u ...
- captcha_trainer 验证码识别-训练 使用记录
captcha_trainer 验证码识别-训练 使用记录 在爬数据的时候,网站出现了验证码,那么我们就得去识别验证码了.目前有两种方案 接入打码平台(花钱,慢) 自己训练(费时,需要GPU环境,快) ...
- 自动化运维利器Ansible要点汇总
由于大部分互联网公司服务器环境复杂,线上线下环境.测试正式环境.分区环境.客户项目环境等造成每个应用都要重新部署,而且服务器数量少则几十台,多则千台,若手工一台台部署效率低下,且容易出错,不利后期运维 ...
- 《手把手教你》系列技巧篇(三十三)-java+ selenium自动化测试-单选和多选按钮操作-上篇(详解教程)
1.简介 在实际自动化测试过程中,我们同样也避免不了会遇到单选和多选的测试,特别是调查问卷或者是答题系统中会经常碰到.因此宏哥在这里直接分享和介绍一下,希望小伙伴或者童鞋们在以后工作中遇到可以有所帮助 ...