Hadoop入门 完全分布式运行模式-准备
Hadoop运行环境
Local Mode:测试偶尔使用
Pseudo-Distributed Mode:用的少
Full-Distreibuted Mode:通常使用
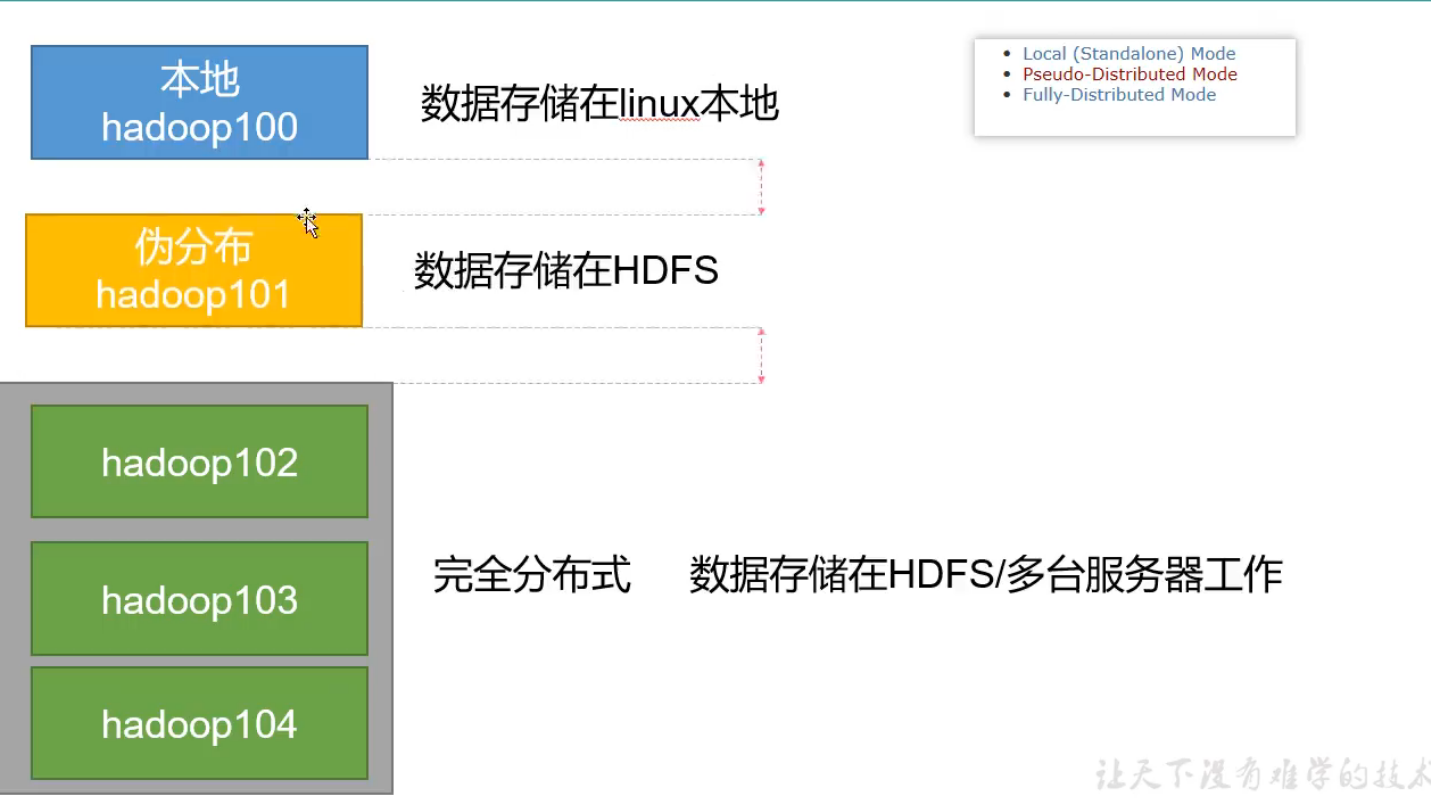
完全分布式运行模式(重点)
任务:
1.准备三台客户机(关闭防火墙、静态IP、主机名称) √
2.安装JDK
3.配置环境变量
4.安装Hadoop
5.配置环境变量
6.配置集群
7.单点启动
8.配置ssh
9.群起并测试集群
scp secure copy 安全拷贝
scp可以实现服务器与服务器之间的数据拷贝
基本语法

1 hadoop102上的JDK文件推给103
前提:在hadoop102、hadoop103、hadoop104都已经创建好了/opt/module、/opt/sofeware两个目录 并且修改为ranan:ranan
opt下: sudo chown ranan:ranan moudule/ sofeware/
在hadoop102上,将hadoop102中/opt/module/jdk1.5目录拷贝到103上
scp -r jdk1.8.0_212/ ranan@hadoop103:/opt/module/

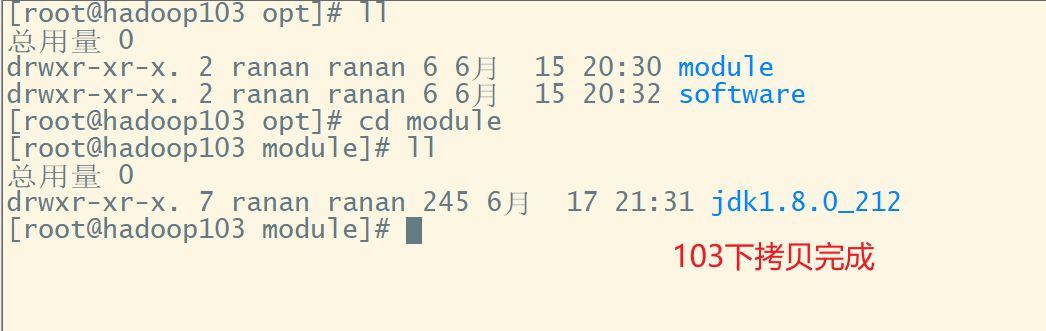
2 hadoop103从102上拉取Hadoop文件
在hadoop103,从hadoop102拉去数据到103
scp -r ranan(对方的用户名):hadoop102(对方的主机名):/opt/module/hadoop-3.1.3(没办法自动补全) /opt/module/(目的路径)


3 在hadoop103上从102把数据拷贝到104
hadoop103下

hadoop104下

rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同的内容和支持符号链接的优点。
rsync和scp区别
rsync:速度更快,只更新差异文件。第一次同步 = scp
scp:复制所有的文件
基本语法
rsync -av(选择参数) 要拷贝的文件路径 目的用户@主机:目的路径
-a 归档拷贝
-v 显示复制过程
编写集群分发脚本xsync
做法:rsync上进行封装
需求:循环复制文件到所有节点的相同目录下
需求分析:
1.rsync原始拷贝命令
# hadoop102下
rsync -av /opt/module/ ranan@hadoop103:/opt/module
2.期望脚本
xsync 要同步的文件名称
3.期望脚本在任何路径都能使用
脚本放在声明了全局环境变量的路径
声明了全局环境变量的路径echo $PATH如图所示,这里选择使用/root/bin

3.脚本实现
把脚本放在全局环境变量下就可以任何路径都能使用了
编写脚本代码
#!/bin/bash
#1. 判断参数个数
# 判断参数是否小于1
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
# 对102,103,104都进行分发
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送 $@代表命令行中所有的参数
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
# 如果不存在
else
echo $file does not exists!
fi
done
done
脚本可执行权限
这里hadoop103,104已经通过scp,rsync安装了JDK和Hadoop了。那么我们就使用分发脚本分发环境变量,给hadoop103、104配置环境变量
这样前5步就完成了。
我这里用的root,用其他用户可能权限不够,解决办法
xsync /etc/profile.d/my_env.sh
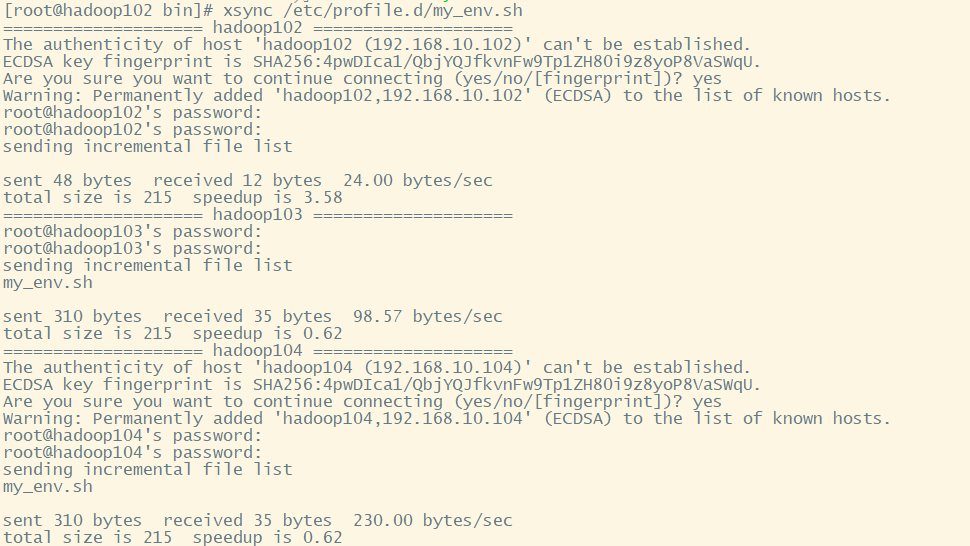

6 配置SSH
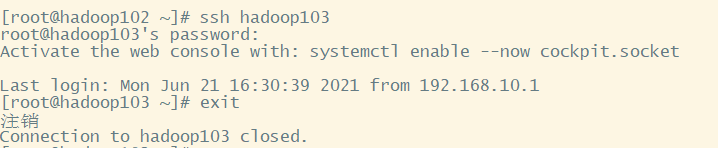
说明:SSh可以访问其他服务器
基本语法:ssh 服务器
退出当前登录:exit
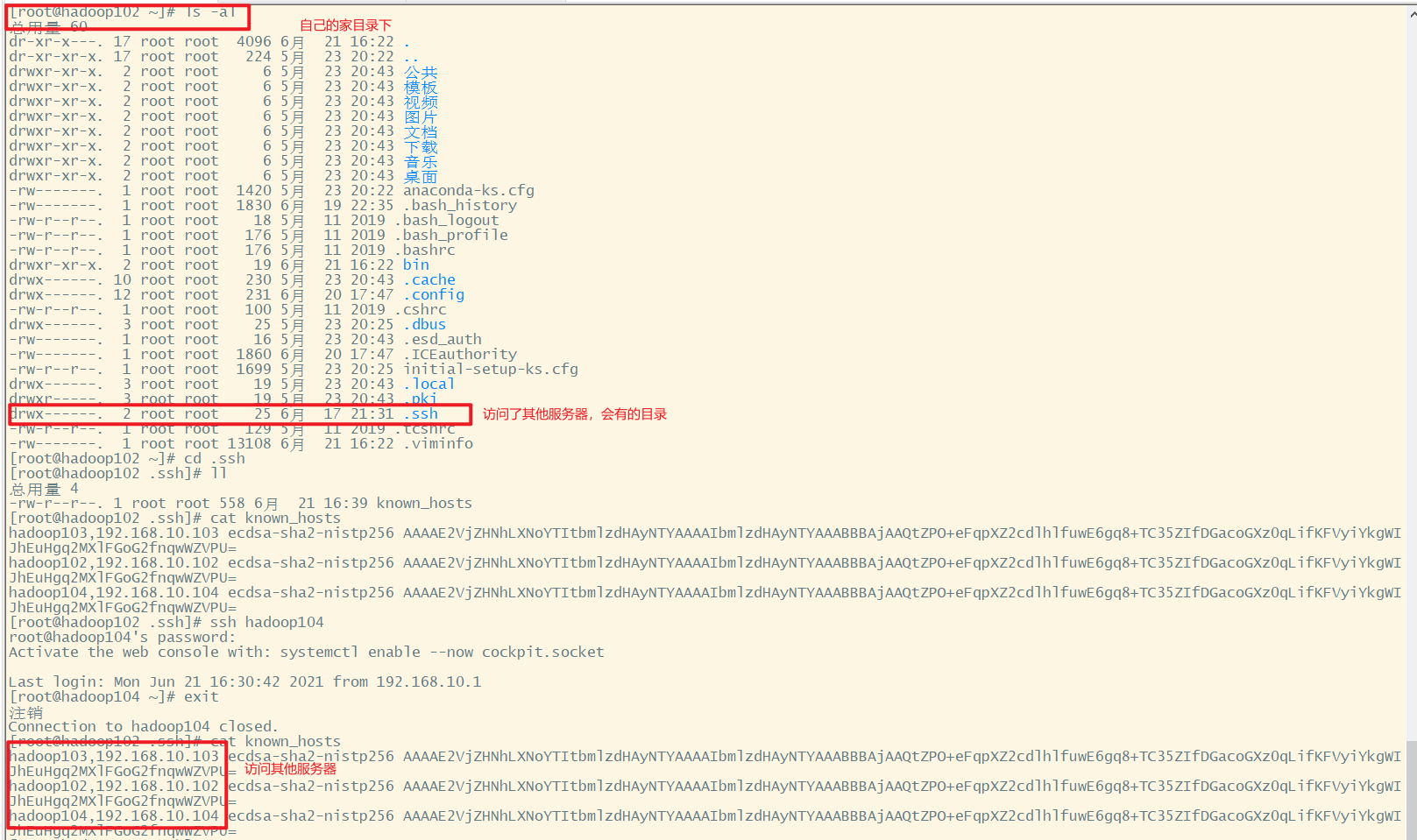
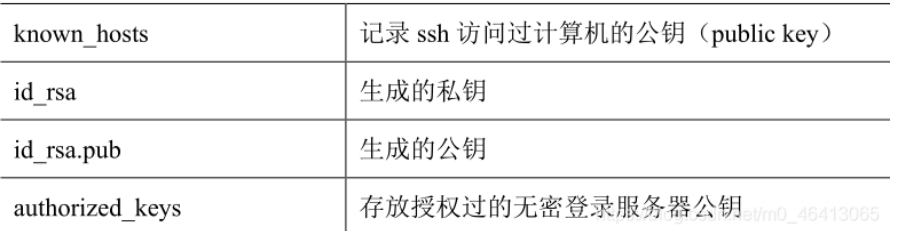
相关文件
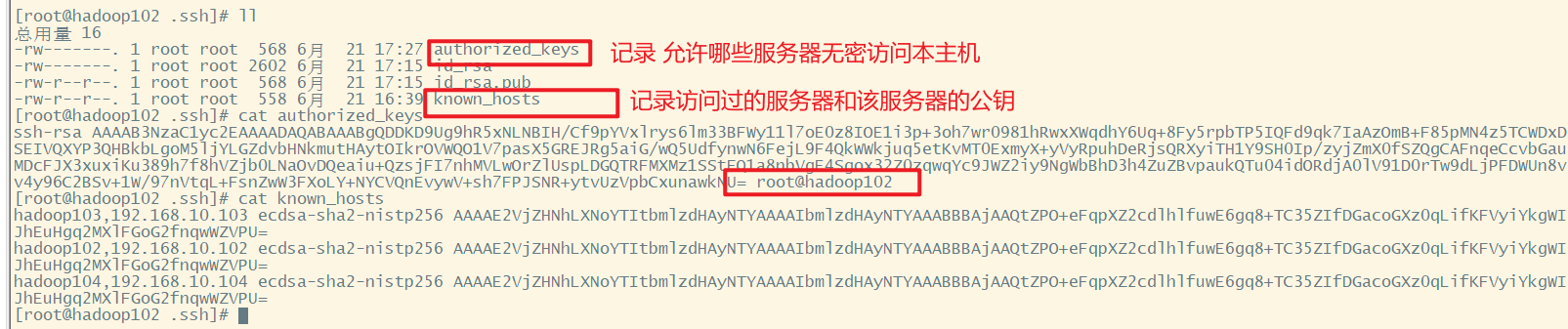
在自己的家目录下,查看隐藏文件ls -al.ssh,进入到.ssh查看known_hosts
.ssh文件夹是在自己的家目录下,所以如果切换到其他用户如ranan,还需要去ranan的家目录重新配置免密登录
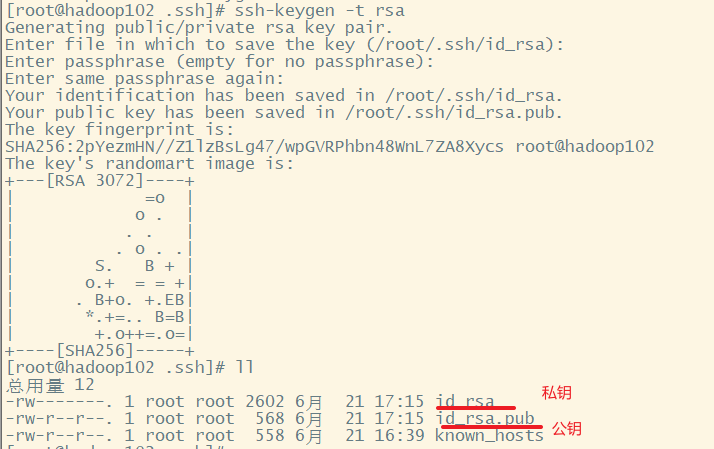
配置无密登录
命令:ssh-keygen -t rsa + 三次回车
说明:生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
1. 获得102的公钥和私钥
2. 把102的公钥拷贝给103、104
[root@hadoop102 .ssh]# ssh-copy-id hadoop103
[root@hadoop102 .ssh]# ssh-copy-id hadoop104
[root@hadoop102 .ssh]# ssh-copy-id hadoop102 # ssh访问自己也需要密码
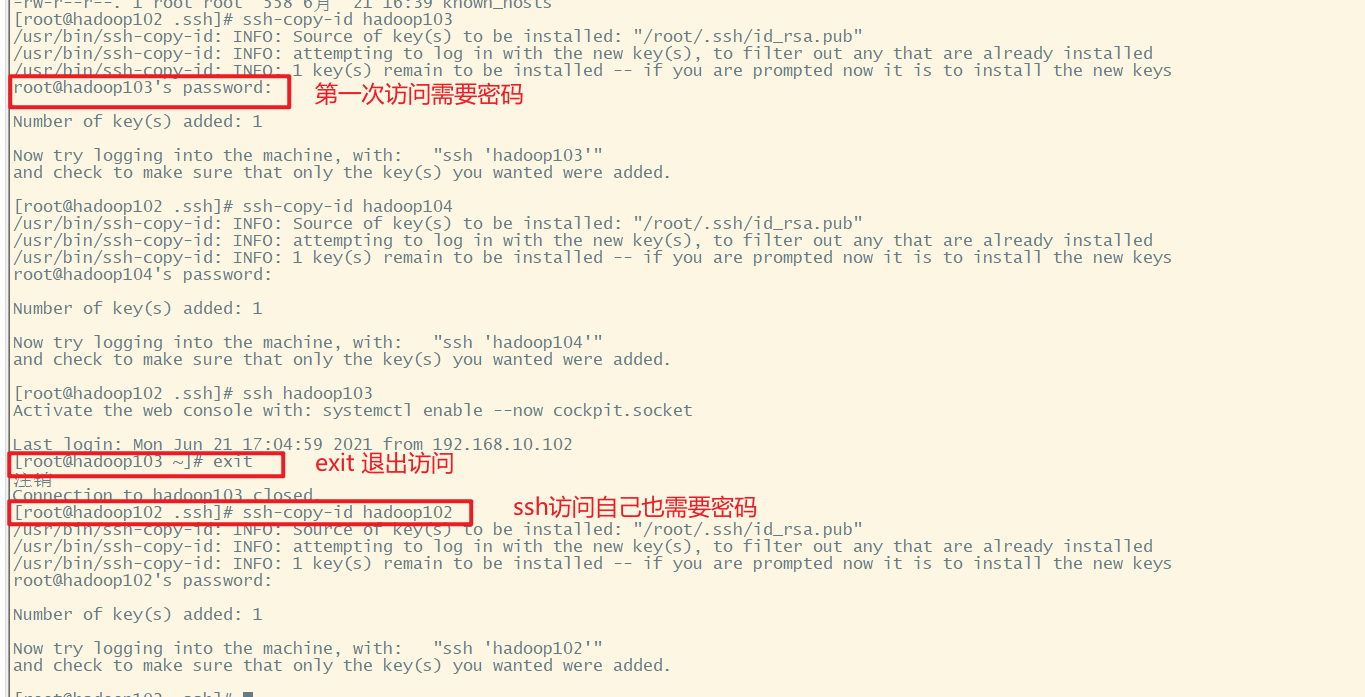
这里102已经可以免密登录103、104了
3. 103、104做同样的操作
[root@hadoop103 .ssh]# ssh-keygen -t rsa
[root@hadoop103 .ssh]# ssh-copy-id hadoop103
[root@hadoop103 .ssh]# ssh-copy-id hadoop104
[root@hadoop103 .ssh]# ssh-copy-id hadoop102
配置102、103已经足够了,配置104的目的是为了操作灵活,任何一台主机都可以访问和操作集群。

步骤总结
1.获得自己的公钥和私钥
2.把自己的公钥拷贝到目的服务器
3.本服务器可以无密访问目的服务器
ssh文件下的文件功能
Hadoop入门 完全分布式运行模式-准备的更多相关文章
- Hadoop入门 完全分布式运行模式-集群配置
目录 集群配置 集群部署规划 配置文件说明 配置集群 群起集群 1 配置workers 2 启动集群 总结 3 集群基本测试 上传文件到集群 查看数据真实存储路径 下载 执行wordcount程序 配 ...
- java大数据最全课程学习笔记(2)--Hadoop完全分布式运行模式
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 Hadoop完全分布式运行模式 步骤分析: 编写集群分发脚本xsync 集群配置 集群部署规划 配置集群 集群单 ...
- Hadoop之搭建完全分布式运行模式
一.过程分析 1.准备3台客户机(关闭防火墙.修改静态ip.主机名称) 2.安装JDK 3.配置环境变量 4.安装Hadoop 5.配置集群 6.单点启动 7.配置ssh免密登录 8.群起并测试集群 ...
- Hadoop之运行模式
Hadoop运行模式包括:本地模式.伪分布式以及完全分布式模式. 一.本地运行模式 1.官方Grep案例 1)在hadoop-2.7.2目录下创建一个 input 文件夹 [hadoop@hadoop ...
- 大数据技术之Hadoop入门
第1章 大数据概论 1.1 大数据概念 大数据概念如图2-1 所示. 图2-1 大数据概念 1.2 大数据特点(4V) 大数据特点如图2-2,2-3,2-4,2-5所示 图2-2 大数据特点之大量 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- Hadoop入门进阶课程1--Hadoop1.X伪分布式安装
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- centos中-hadoop单机安装及伪分布式运行实例
创建用户并加入授权 1,创建hadoop用户 sudo useradd -m hadoop -s /bin/bash 2,修改sudo的配置文件,位于/etc/sudoers,需要root权限才可以读 ...
- Hadoop系列005-Hadoop运行模式(下)
本人微信公众号,欢迎扫码关注! Hadoop运行模式(下) 2.3.完全分布式部署Hadoop 1)分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4) ...
随机推荐
- 从零开始 DIY 智能家居 - 基于 ESP32 的智能语音合成播报模块
目录 前言 硬件选择 代码解析 获取代码 设备控制命令: 设备和协议初始化流程: 配置设备信息 回调函数注册 语音播报与设置流程 总结 前言 这里这么多设备,突然发现我做的好像都是传感器之类的居多好像 ...
- heihei
adb shell screencap -p /sdcard/p1.pngadb pull /sdcard/p1.png c:\BaiduYunDownloadadb shell rm /sdcard ...
- Go语言核心36讲(Go语言进阶技术十二)--学习笔记
18 | if语句.for语句和switch语句 现在,让我们暂时走下神坛,回归民间.我今天要讲的if语句.for语句和switch语句都属于 Go 语言的基本流程控制语句.它们的语法看起来很朴素,但 ...
- fork函数详解(附代码)
虽然篇幅很长,但大多是易懂的代码,不用担心看不完 这里的所有操作,都将在下面的代码中有所体现 fork会拷贝当前进程的内存,并创建一个新的进程.如上图,fork函数会将整个进程的内存镜像拷贝到新的内存 ...
- 分布式事务(四)之TCC
在电商领域等互联网场景下,传统的事务在数据库性能和处理能力上都暴露出了瓶颈.在分布式领域基于CAP理论以及BASE理论,有人就提出了柔性事务的概念.在业内,关于柔性事务,最主要的有以下四种类型:两阶段 ...
- glibc memcpy() 源码浅谈
其实我本来只是想搞懂为什么memcpy()函数的参数类型是void *的: 我以为会在memcpy()源码中能找到答案,其实并没有,void *只是在传递参数的时候起了作用,可以让memcpy()接受 ...
- C# | VS2019连接MySQL的三种方法以及使用MySQL数据库教程
本文将介绍3种添加MySQL引用的方法,以及连接MySQL和使用MySQL的教程 前篇:Visual Studio 2019连接MySQL数据库详细教程 \[QAQ \] 第一种方法 下载 Mysql ...
- Nginx面试题(总结最全面的面试题!!!)
https://blog.csdn.net/weixin_43122090/article/details/105461971
- 彻底搞懂Spring状态机原理,实现订单与物流解耦
本文节选自<设计模式就该这样学> 1 状态模式的UML类图 状态模式的UML类图如下图所示. 2 使用状态模式实现登录状态自由切换 当我们在社区阅读文章时,如果觉得文章写得很好,我们就会评 ...
- vue2与vue3的差异(总结)?
vue作者尤雨溪在开发 vue3.0 的时候开发的一个基于浏览器原生 ES imports 的开发服务器(开发构建工具).那么我们先来了解一下vite Vite Vite,一个基于浏览器原生 ES i ...