XStream: Stream Processing Platform at Facebook
这是Facebook在FlinkForward2021上的一个talk, 主题如下

在前面的论文中分析了Facebook的实时计算引擎的设计和选型的考量,里面提到了Facebook的实时计算引擎为了满足易用性和性能不同维度的需求,研发了多套实时计算系统如Puma``Stylus``Swift分别使用SQL,C++,Swift来进行研发。但是多套引擎也带来了很多问题,可选择的引擎太多,不同的引擎的功能重叠,对用户和对于引擎维度都有很大的成本。为了能让用户获得一致性的体验,其内部选择将多套引擎整合成一套也就是XStream。

XStream架构分层

他有以下的一些特点
- 基于
Stylus的一个Native C++的执行引擎 - 基于统一的SQL语言,统一的流,批,交互式的查询语言
- 使用解释执行而不是编译执行的模式
- 和presto/spark 共享使用了向量化的SQL执行引擎


SQL上使用标准的SQL2016的语法和Presto统一,并且做了Multi-tumble 和 Mulit-slide window的拓展工作

编译执行的方式就是根据SQL生成的AST tree进行codegen,然后进行编译执行。编译执行的坏处主要是
- 每个pipeline都会生成一个binary文件
- scale up down不友好
- 依赖问题
- 编译时间较长
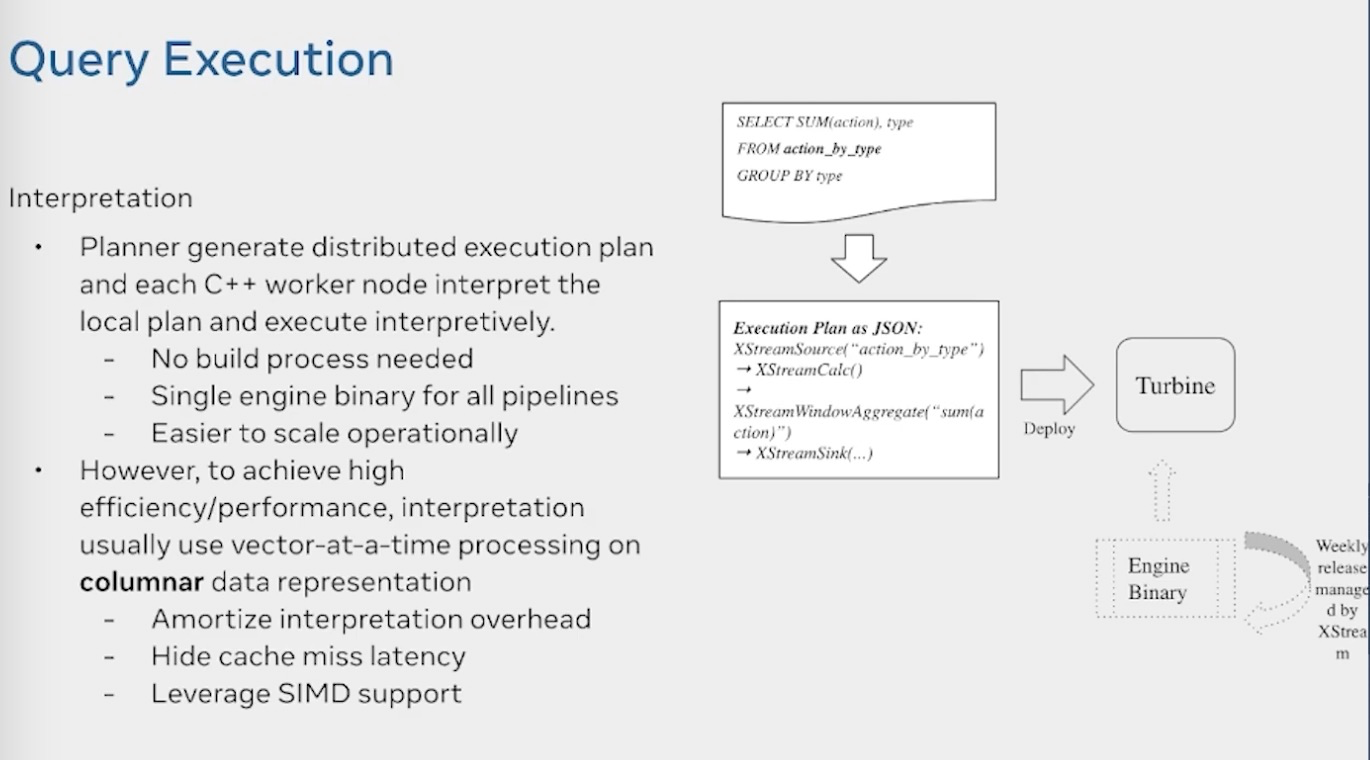
最终他们采用的是解释执行的模式。由C++ worker解释执行,一个作业只有一个binary,但是解释执行的效率肯定没有编译执行的效率高,因此他们使用了以下手段来提速
- 使用列式存储+向量化处理模式
- 利用simd指令加速

向量化提速用到了最近新起的velox的项目,它是一个C++向量化的SQL执行引擎,由Facebook开源,并在其内部用于Presto和Spark以及XStream的统一的运行时向量化加速,velox相关的可以参看这篇文章 Velox: 现代化的向量化执行引擎
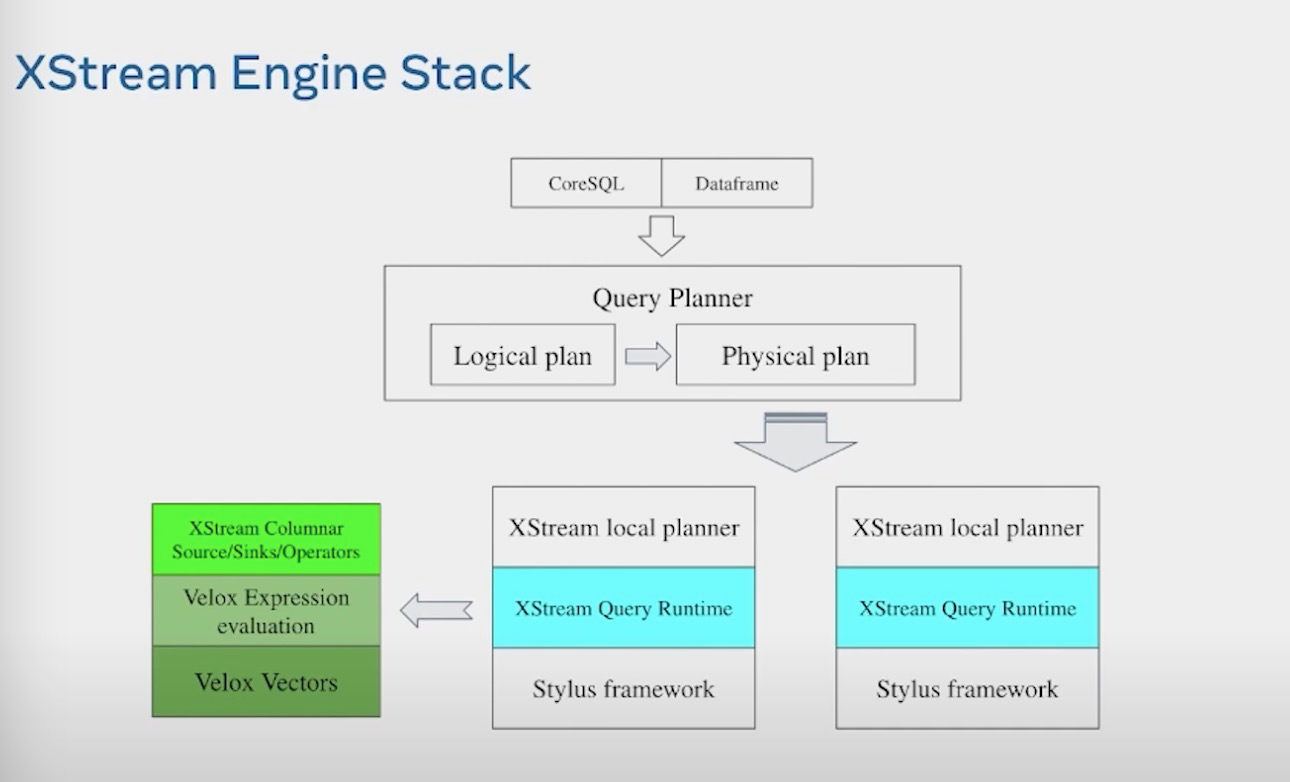
整体的XStream架构,提供CoreSQL和DataFrame两套api,编译成LogicalPlan和Physical Plan。然后分发到local worker进行处理。Local planner将其翻译成XStream operator, 然后利用Velox 来进行加速处理

Velox和XStream 编译型和解释型的对比数据
参考
https://www.youtube.com/watch?v=DNI54vc1ALQ&t=1158s&ab_channel=FlinkForward
XStream: Stream Processing Platform at Facebook的更多相关文章
- 腾讯大数据平台Oceanus: A one-stop platform for real time stream processing powered by Apache Flink
January 25, 2019Use Cases, Apache Flink The Big Data Team at Tencent In recent years, the increa ...
- Stream Processing 101: From SQL to Streaming SQL in 10 Minutes
转自:https://wso2.com/library/articles/2018/02/stream-processing-101-from-sql-to-streaming-sql-in-ten- ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
- Storm(2) - Log Stream Processing
Introduction This chapter will present an implementation recipe for an enterprise log storage and a ...
- Akka(23): Stream:自定义流构件功能-Custom defined stream processing stages
从总体上看:akka-stream是由数据源头Source,流通节点Flow和数据流终点Sink三个框架性的流构件(stream components)组成的.这其中:Source和Sink是stre ...
- Apache Samza - Reliable Stream Processing atop Apache Kafka and Hadoop YARN
http://engineering.linkedin.com/data-streams/apache-samza-linkedins-real-time-stream-processing-fram ...
- 13 Stream Processing Patterns for building Streaming and Realtime Applications
原文:https://iwringer.wordpress.com/2015/08/03/patterns-for-streaming-realtime-analytics/ Introduction ...
- 1.2 Use Cases中 Stream Processing官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Stream Processing 流处理 Many users of Kafka ...
- 1.1 Introduction中 Kafka for Stream Processing官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Kafka for Stream Processing kafka的流处理 It i ...
随机推荐
- JavaScript的执行过程(深入执行上下文、GO、AO、VO和VE等概念)
JavaScript的执行过程 前言 编写一段JavaScript代码,它是如何执行的呢?简单来说,JS引擎在执行JavaScript代码的过程中需要先解析再执行.那么在解析阶段JS引擎又会进行哪些操 ...
- CAS学习笔记四:CAS单点登出流程
CAS 的登出包含两种情况,一种是CAS客户端登出,另一种是CAS单点登出,使用流程图说明这两者的不同.(一图胜千言) 总结自官方文档 CAS客户端登出流程 如图,客户端的登出仅仅是过期当前用户与客户 ...
- 【初体验】macos下android ndk交叉编译hello world,并拷贝到android手机上执行
1.机器上以前安装了java 1.8(貌似android ndk不需要java) 2. 下载android ndk,版本是android-ndk-r14b (比较奇怪,我下载了最新的android-n ...
- android ndk下没有pthread_yield,好在std::this_thread::yield()可以达到同样的效果
一个多线程的算法中,发现线程利用率只有47%左右,大量的处理时间因为usleep(500)而导致线程睡眠: 性能始终上不去. 把usleep(500)修改为std::this_thread::yiel ...
- 2021年SpringBoot面试题200道及答案
https://blog.csdn.net/yanpenglei/article/details/120822218 https://blog.csdn.net/ldb987/article/deta ...
- 关于cmake和开源项目发布的那些事(PF)
本来是打算写一篇年终总结,随便和以往一样提一提自己的开源项目(长不大的plain framework)的一些进度,不过最近这一年对于这个项目实在是维护不多,实在难以用它作为醒目的标题.而最近由于使用了 ...
- SSM项目使用拦截器实现登录验证功能
SSM项目使用拦截器实现登录验证功能 登录接口实现 public User queryUser(String UserName, String Password,HttpServletRequest ...
- gin框架的热加载方法
gin是用于实时重新加载Go Web应用程序的简单命令行实用程序.只需gin在您的应用程序目录中运行,您的网络应用程序将 gin作为代理提供.gin检测到更改后,将自动重新编译您的代码.您的应用在下次 ...
- ddos攻击是什么,如何防御
DDoS(Distributed Denial of Service,分布式拒绝服务) 定义: 主要通过大量合法的请求占用大量网络资源,从而使合法用户无法得到服务的响应,是目前最强大.最难防御的攻击之 ...
- Water 2.5 发布,一站式服务治理平台
Water(水孕育万物...) Water 为项目开发.服务治理,提供一站式解决方案(可以理解为微服务架构支持套件).基于 Solon 框架开发,并支持完整的 Solon Cloud 规范:已在生产环 ...