XStream: Stream Processing Platform at Facebook
这是Facebook在FlinkForward2021上的一个talk, 主题如下

在前面的论文中分析了Facebook的实时计算引擎的设计和选型的考量,里面提到了Facebook的实时计算引擎为了满足易用性和性能不同维度的需求,研发了多套实时计算系统如Puma``Stylus``Swift分别使用SQL,C++,Swift来进行研发。但是多套引擎也带来了很多问题,可选择的引擎太多,不同的引擎的功能重叠,对用户和对于引擎维度都有很大的成本。为了能让用户获得一致性的体验,其内部选择将多套引擎整合成一套也就是XStream。

XStream架构分层

他有以下的一些特点
- 基于
Stylus的一个Native C++的执行引擎 - 基于统一的SQL语言,统一的流,批,交互式的查询语言
- 使用解释执行而不是编译执行的模式
- 和presto/spark 共享使用了向量化的SQL执行引擎


SQL上使用标准的SQL2016的语法和Presto统一,并且做了Multi-tumble 和 Mulit-slide window的拓展工作

编译执行的方式就是根据SQL生成的AST tree进行codegen,然后进行编译执行。编译执行的坏处主要是
- 每个pipeline都会生成一个binary文件
- scale up down不友好
- 依赖问题
- 编译时间较长
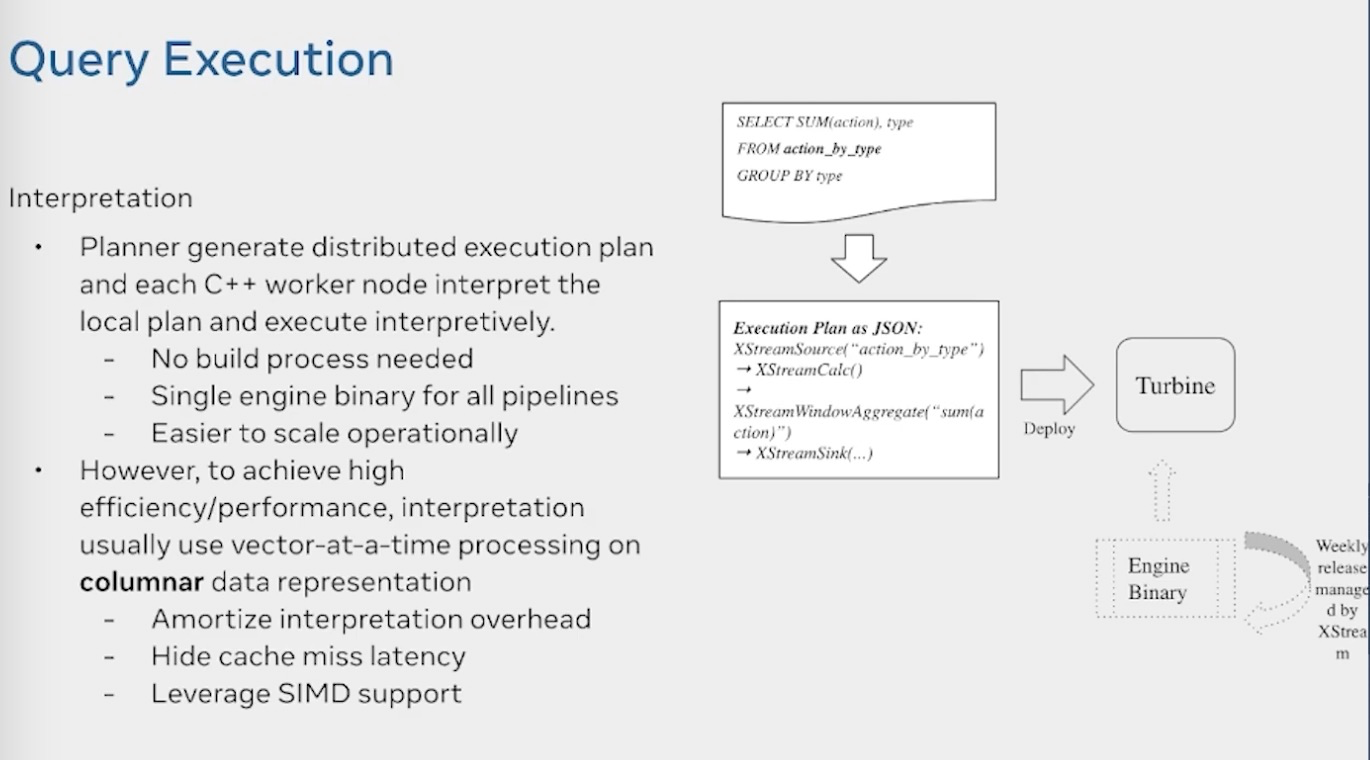
最终他们采用的是解释执行的模式。由C++ worker解释执行,一个作业只有一个binary,但是解释执行的效率肯定没有编译执行的效率高,因此他们使用了以下手段来提速
- 使用列式存储+向量化处理模式
- 利用simd指令加速

向量化提速用到了最近新起的velox的项目,它是一个C++向量化的SQL执行引擎,由Facebook开源,并在其内部用于Presto和Spark以及XStream的统一的运行时向量化加速,velox相关的可以参看这篇文章 Velox: 现代化的向量化执行引擎
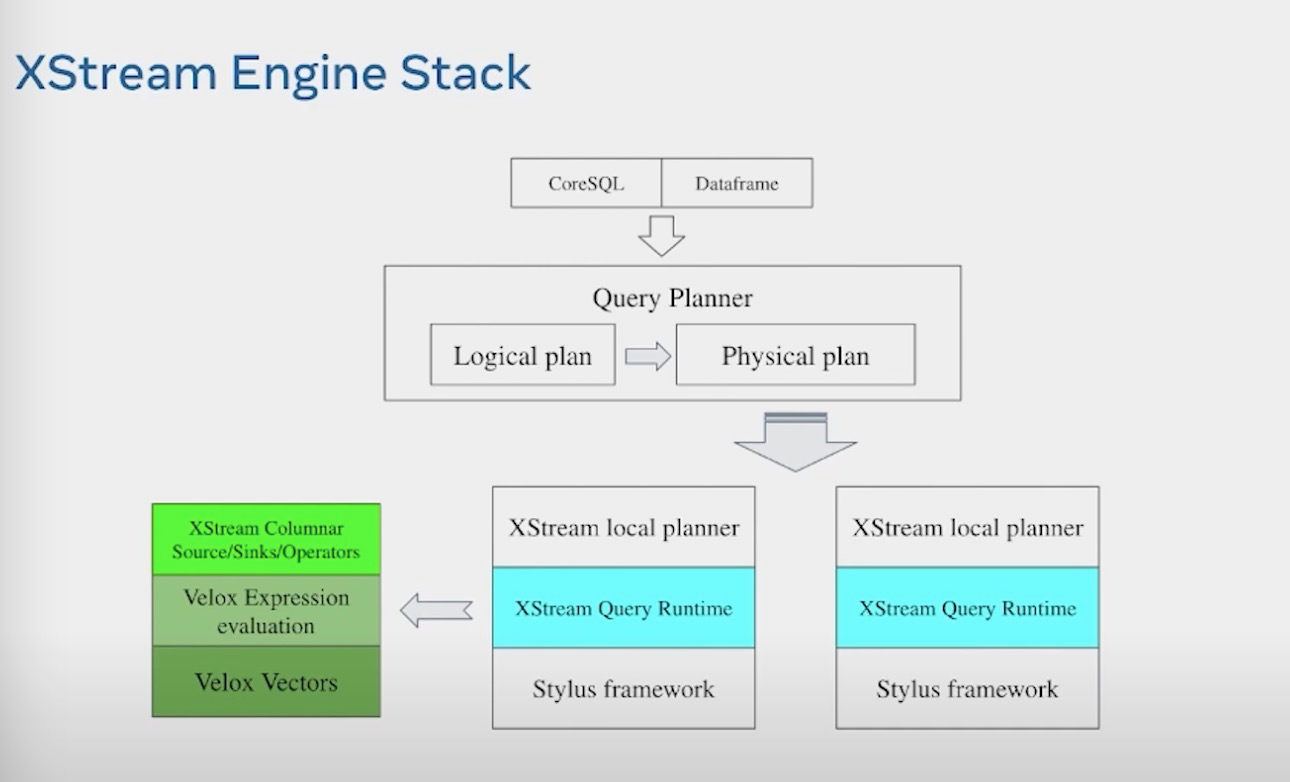
整体的XStream架构,提供CoreSQL和DataFrame两套api,编译成LogicalPlan和Physical Plan。然后分发到local worker进行处理。Local planner将其翻译成XStream operator, 然后利用Velox 来进行加速处理

Velox和XStream 编译型和解释型的对比数据
参考
https://www.youtube.com/watch?v=DNI54vc1ALQ&t=1158s&ab_channel=FlinkForward
XStream: Stream Processing Platform at Facebook的更多相关文章
- 腾讯大数据平台Oceanus: A one-stop platform for real time stream processing powered by Apache Flink
January 25, 2019Use Cases, Apache Flink The Big Data Team at Tencent In recent years, the increa ...
- Stream Processing 101: From SQL to Streaming SQL in 10 Minutes
转自:https://wso2.com/library/articles/2018/02/stream-processing-101-from-sql-to-streaming-sql-in-ten- ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
- Storm(2) - Log Stream Processing
Introduction This chapter will present an implementation recipe for an enterprise log storage and a ...
- Akka(23): Stream:自定义流构件功能-Custom defined stream processing stages
从总体上看:akka-stream是由数据源头Source,流通节点Flow和数据流终点Sink三个框架性的流构件(stream components)组成的.这其中:Source和Sink是stre ...
- Apache Samza - Reliable Stream Processing atop Apache Kafka and Hadoop YARN
http://engineering.linkedin.com/data-streams/apache-samza-linkedins-real-time-stream-processing-fram ...
- 13 Stream Processing Patterns for building Streaming and Realtime Applications
原文:https://iwringer.wordpress.com/2015/08/03/patterns-for-streaming-realtime-analytics/ Introduction ...
- 1.2 Use Cases中 Stream Processing官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Stream Processing 流处理 Many users of Kafka ...
- 1.1 Introduction中 Kafka for Stream Processing官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Kafka for Stream Processing kafka的流处理 It i ...
随机推荐
- 《剑指offer》面试题59 - I. 滑动窗口的最大值
问题描述 给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值. 示例: 输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3 输出: [3,3,5,5 ...
- go语言 strconv.ParseInt 的实现分析
字符串与数值之间进行转换是一个高频操作,在go语言中,SDK提供 strconv.ParseInt 将字符串转换为数值,strconv.FormatInt 可以将数值转换为字符串. 1.首先看下 st ...
- WSL删除子系统后无法重装
问题 WSL卸载后安装error 解决办法 UWP应用卸载后没有删除目录下的文件 C:\Users\wwwfe\AppData\Local\Packages路径下删除就可以了 再次安装会卡顿很久,可能 ...
- 使用Hot Chocolate和.NET 6构建GraphQL应用(1)——GraphQL及示例项目介绍
系列导航 使用Hot Chocolate和.NET 6构建GraphQL应用文章索引 前言 这篇文章是这个系列的第一篇,我们会简单地讨论一下GraphQL,然后介绍一下这个系列将会使用的示例项目. 关 ...
- elasticsearch启动流程
本文基于ES2.3.2来描述.通过结合源码梳理出ES实例的启动过程. elasticsearch的启动过程是根据配置和环境组装需要的模块并启动的过程.这一过程就是通过guice注入各个功能模块并启动这 ...
- IoC容器-Bean管理XML方式(注入内部bean和级联赋值)
注入属性-内部bean和级联赋值 (1)一对多关系:部分和员工 一个部门有多个员工,一个员工属于一个部门 部门是一,员工是多 (2)在实体类之间表示一对多关系 (3)在spring配置文件中进行配置 ...
- git命令,github
1.git原理 2.git和svn的区别 SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以首先要从中央服务器哪里得到最新的版本,然后干活,干完后,需要把 ...
- python网络爬虫-入门(二)
为什么要学网络爬虫 可以替代人工从网页中找到数据并复制粘贴到excel中,这种重复性的工作不仅浪费时间还一不留神还会出错----解决无法自动化和无法实时获取数据 对于这些公开数据的应用价值,我 ...
- Luogu_P1613跑路
跳转链接 题目大意 题目中要求的是从1号点到n号点所需要的最短时间, 一秒可以走 \(2^k\) 个距离 给定的有向图的边边权都是1. 问题分析 由于一秒可以走 \(2^k\) 个距离,因此题目转化为 ...
- 理解https中的安全及其实现原理
Google的一份网络上的 HTTPS 加密透明报告(数据截至2022年1月)中指出HTTPS 连接的普及率在过去几年激增,互联网上排名前 100 位的非 Google 网站HTTPS 使用情况为:9 ...