在 Cloudera Data Flow 上运行你的第一个 Flink 例子
文档编写目的
Cloudera Data Flow(CDF) 作为 Cloudera 一个独立的产品单元,围绕着实时数据采集,实时数据处理和实时数据分析有多个不同的功能模块,如下图所示:
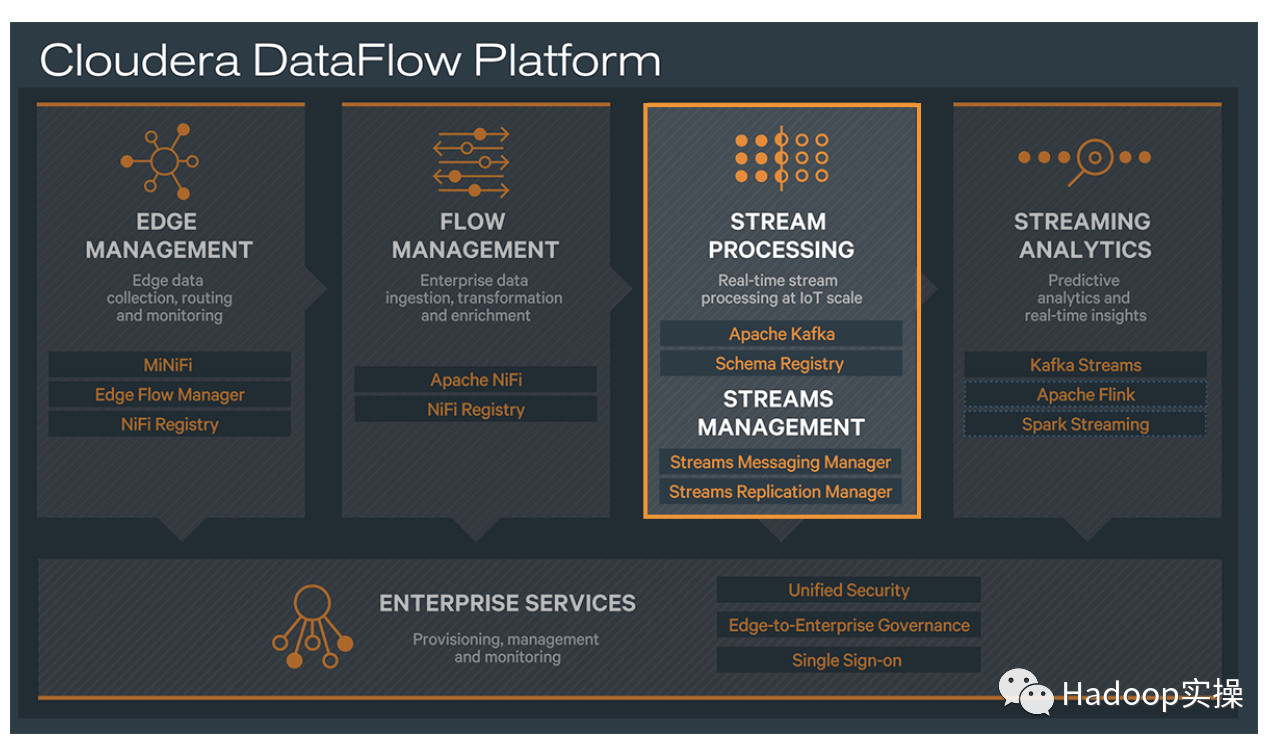
图中 4 个功能模块从左到右分别解释如下:
- Cloudera Edge Management(CEM),主要是指在边缘设备如传感器上部署 MiNiFi 的 agent 后用于采集数据。
- Cloudera Flow Management(CFM),主要是使用 Apache NiFi 通过界面化拖拽的方式实现数据采集,处理和转换。
- Cloudera Streaming Processing(CSP),主要包括 Apache Kafka,Kafka Streams,Kafka 的监控 Streams Messaging Manager(SMM),以及跨集群 Kafka topic 的数据复制 Streams Replication Manager(SRM)。
- Cloudera Streaming Analytics(CSA),以前这块是使用 Storm 来作为 Native Streaming 来补充 Spark Streaming 的 Micro-batch 的时延问题,目前这块改为 Flink 来实现,未来的 CDF 中将不再包含 Storm。
本文 Fayson 主要是介绍如何在 CDH6.3 中安装 Flink 1.9 以及运行你的第一个 Flink 例子,以下是测试环境信息:
- CM 和 CDH 版本为 6.3
- Redhat 7.4
- JDK 1.8.0_181
- 集群未启用 Kerberos
- Root 用户安装
安装 Flink 1.9
1.准备 Flink 1.9 的 csd 文件,并放置到 Cloudera Manager Server 的 /opt/cloudera/csd 目录。然后重启 Cloudera Manager Server 服务。

2.CM 重启完成以后,添加服务页面可以看到有 Flink 服务。

3.下载 Flink 1.9 的 Parcel,并放置 /var/www/html 目录。

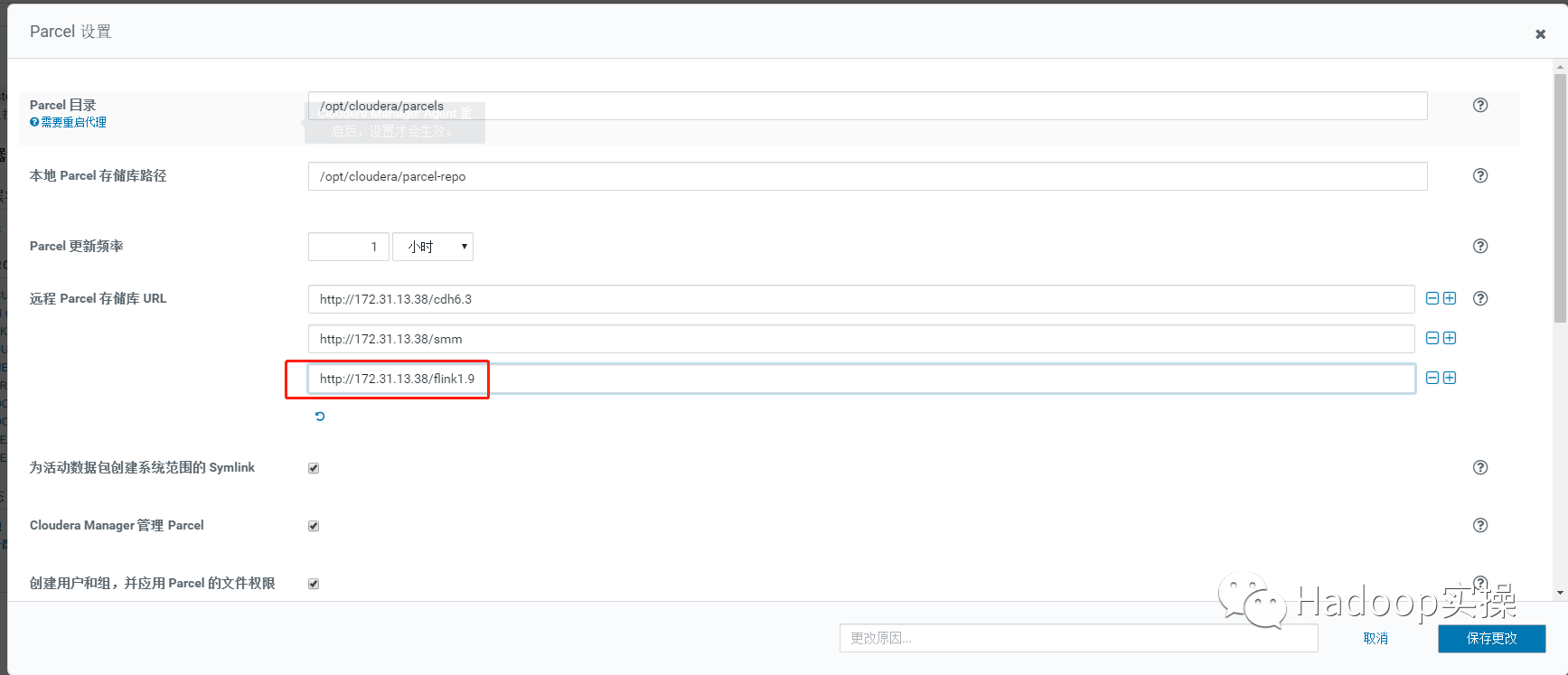
4.通过 Hosts > Parcels 进入 Cloudera Manager 的 Parcel 页面,输入 SMM Parcel 的 http 地址,下载->分配->激活。

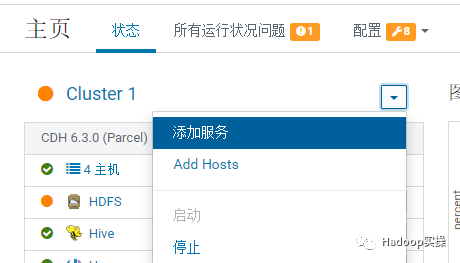
5.进入 CM 主页点击“添加服务”。
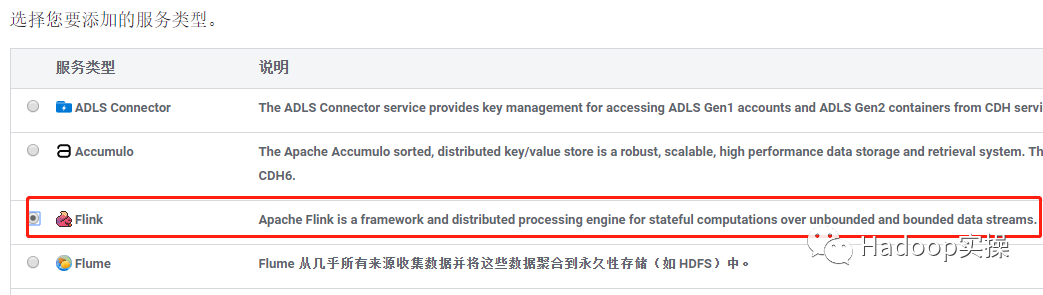
6.选择添加 Flink 服务,点击继续。
7.选择 Flink History Server 以及 Gateway 节点,点击继续。
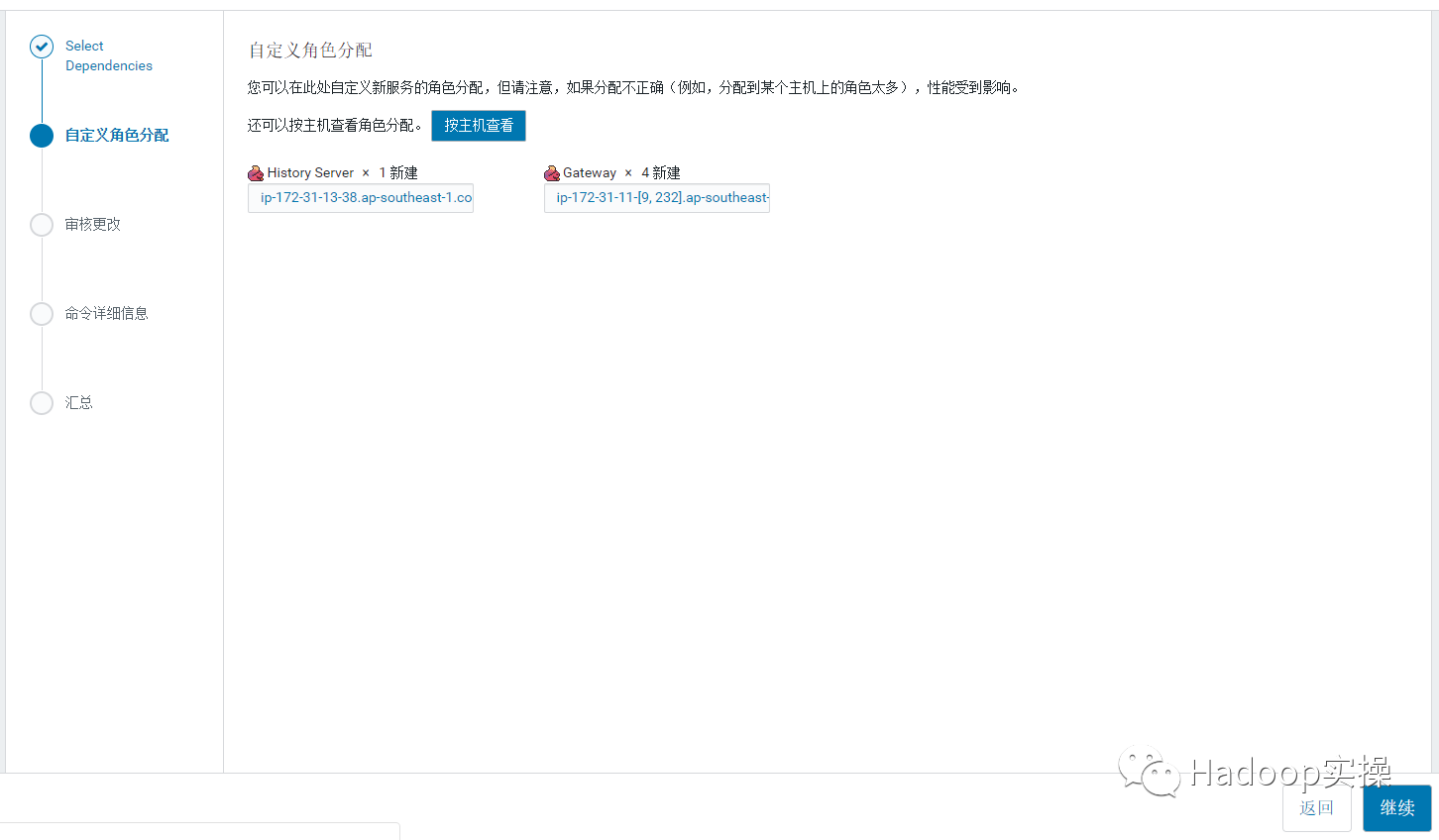
8.点击继续。
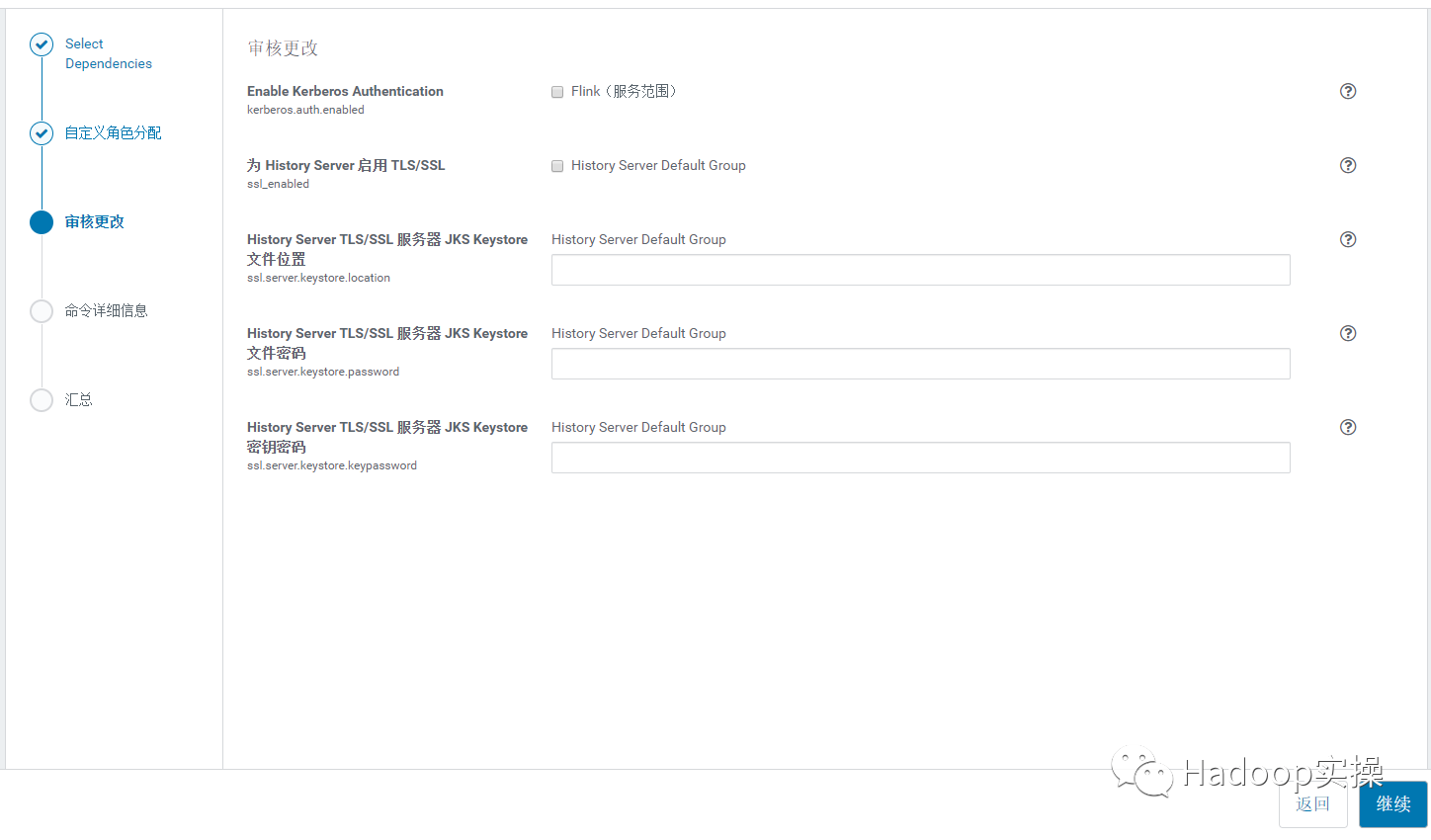
9.等待 Flink History Server 启动成功,完成后点击继续。
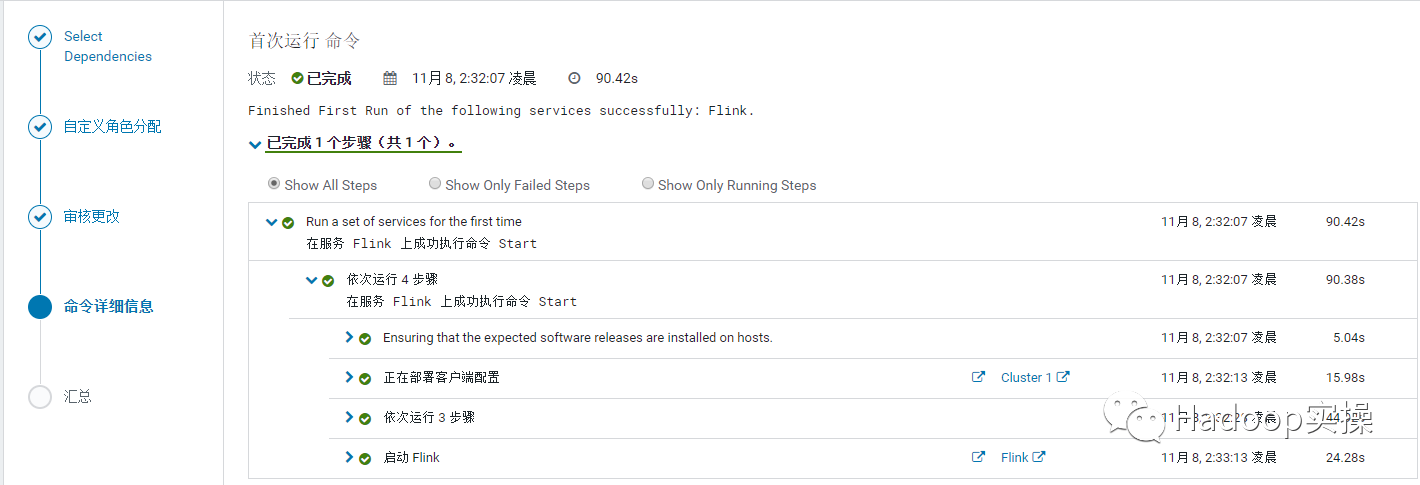
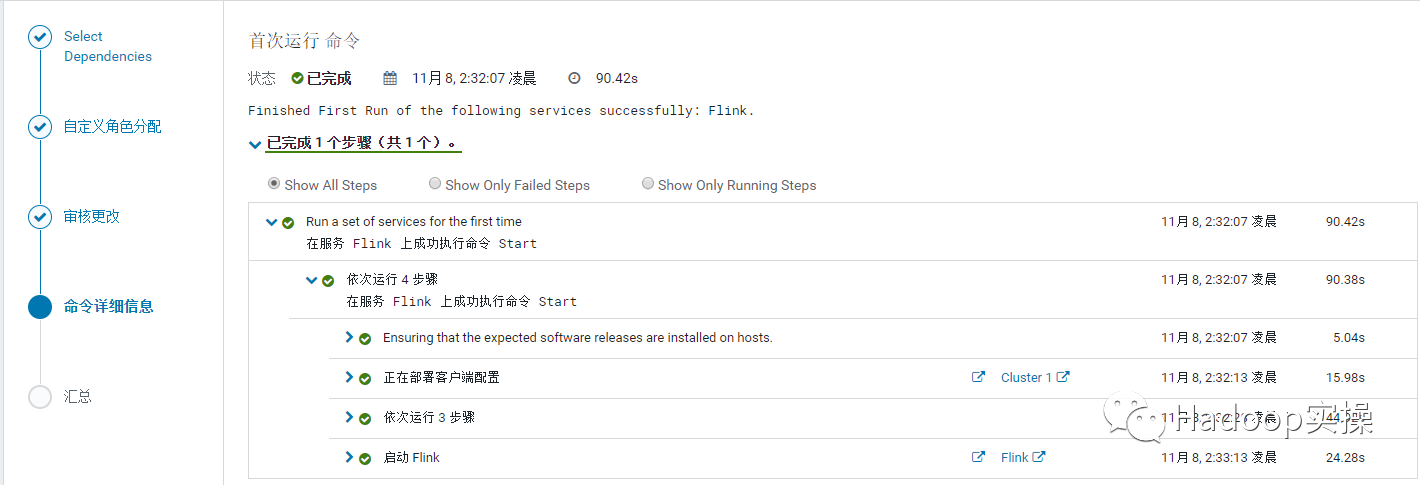
10.安装完成,点击完成回到 CM 主页。
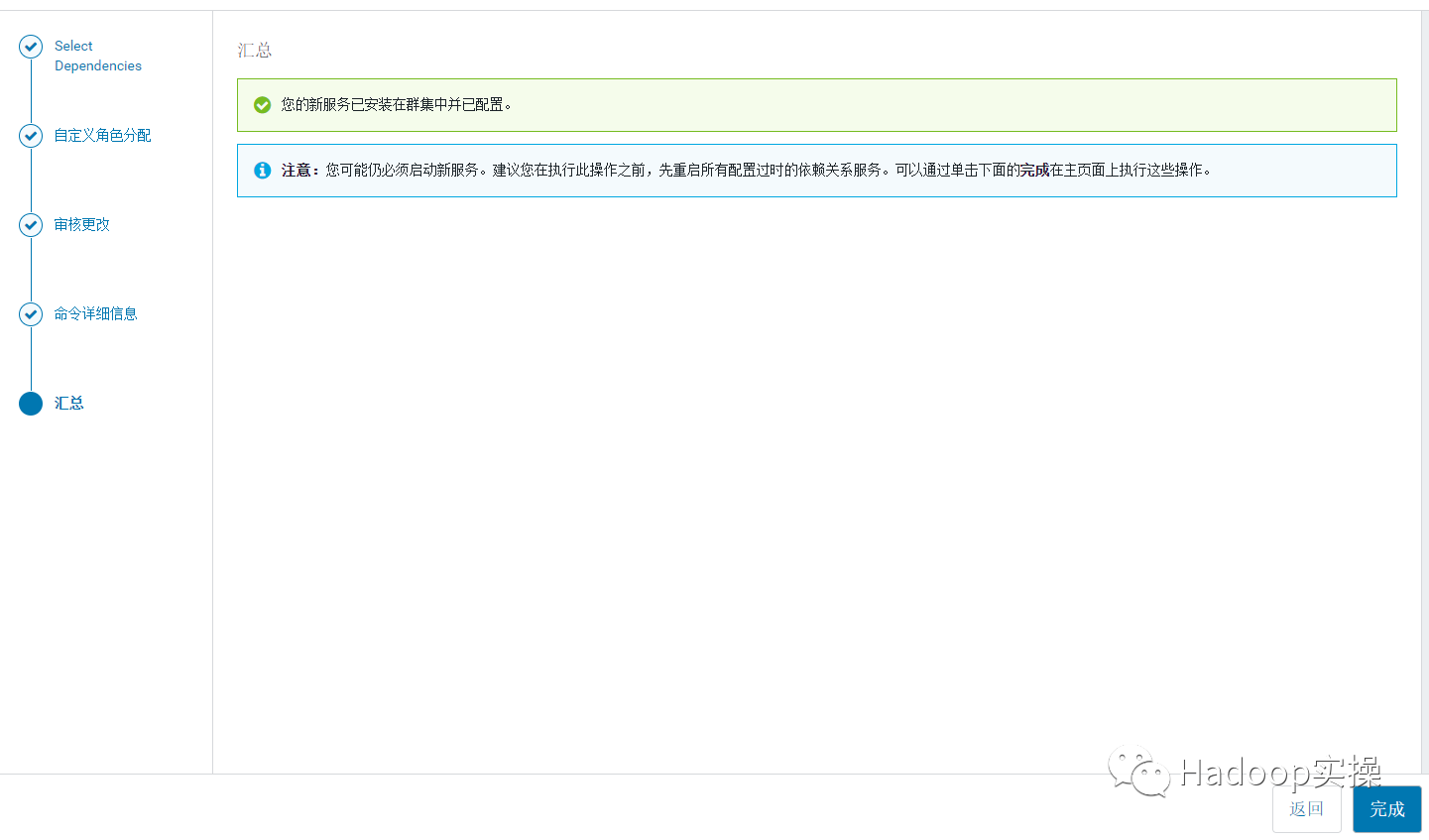
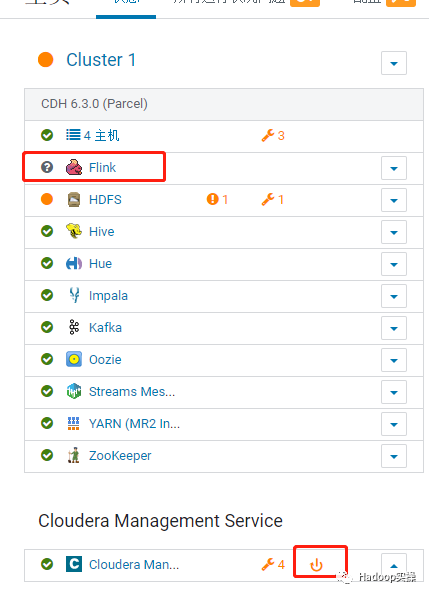
发现 Flink 的状态为灰色,CMS 有重启提示,按照提示重启 CMS 服务,重启过程略。重启完成后显示 Flink 服务正常。
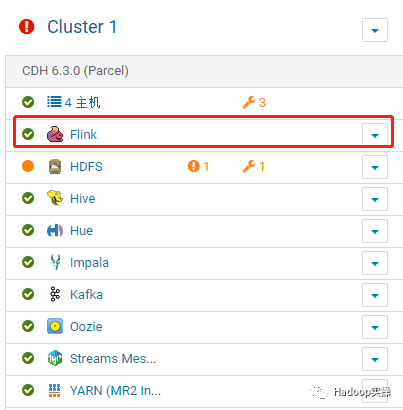
第一个 Flink 例子
1.执行 Flink 自带的 example 的 wordcount 例子。

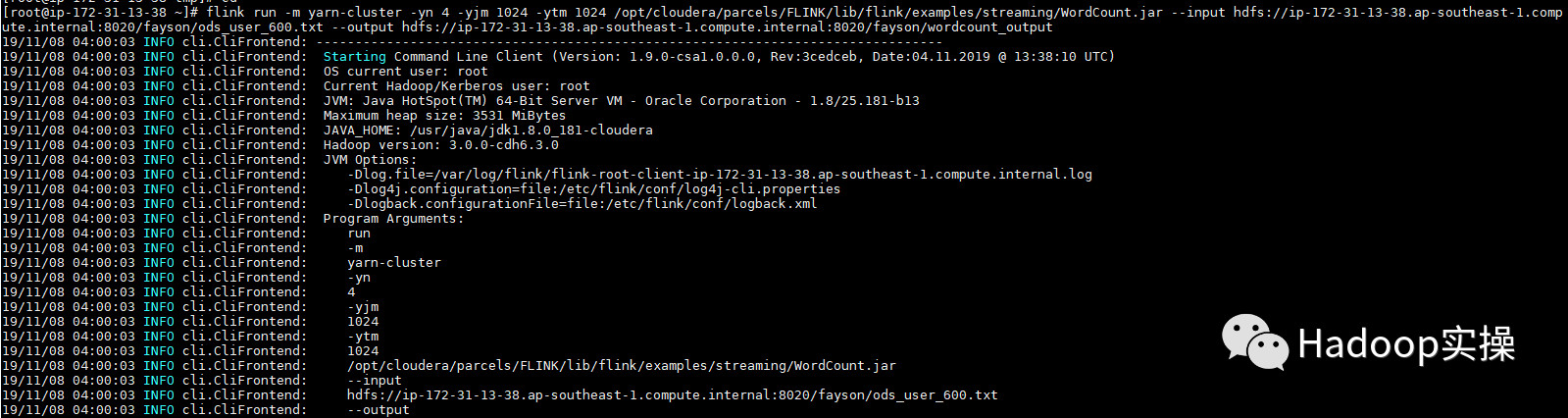
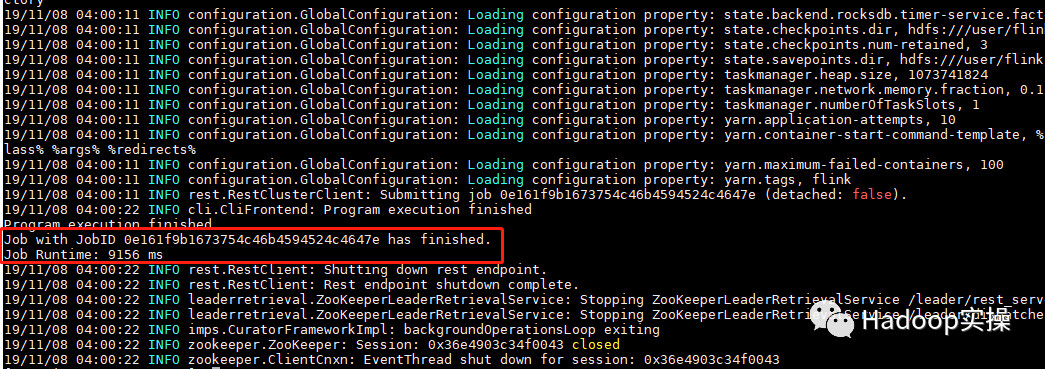
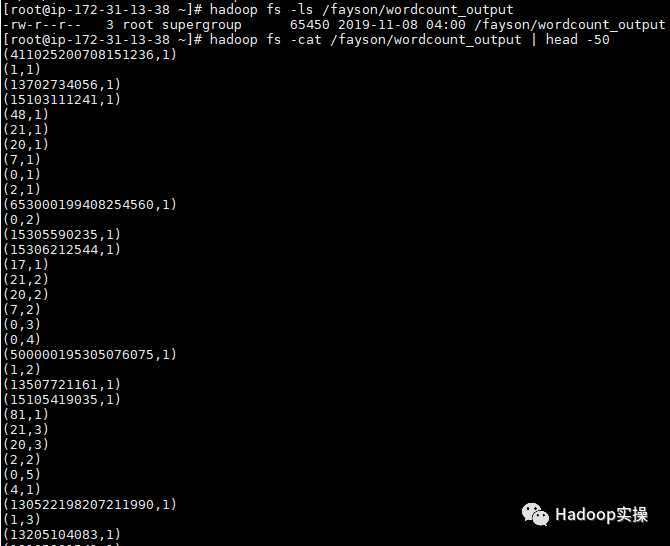
2.查看输出结果。
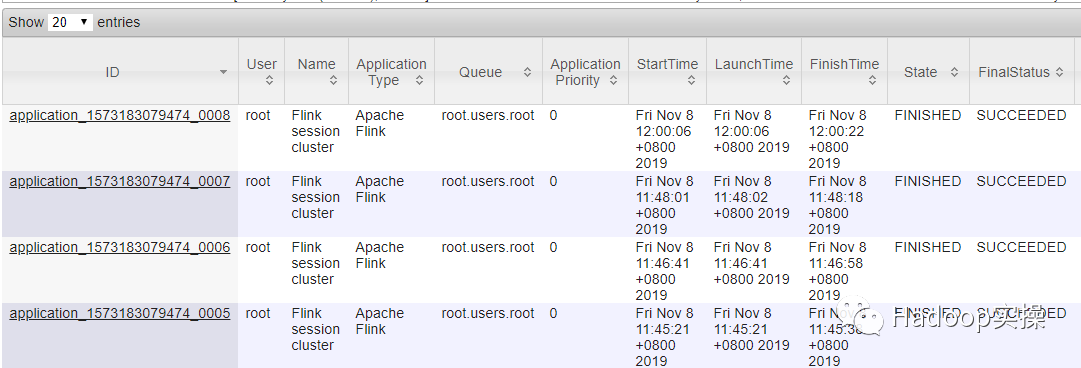
3.在 YARN 和 Flink 的界面上分别都能看到这个任务。
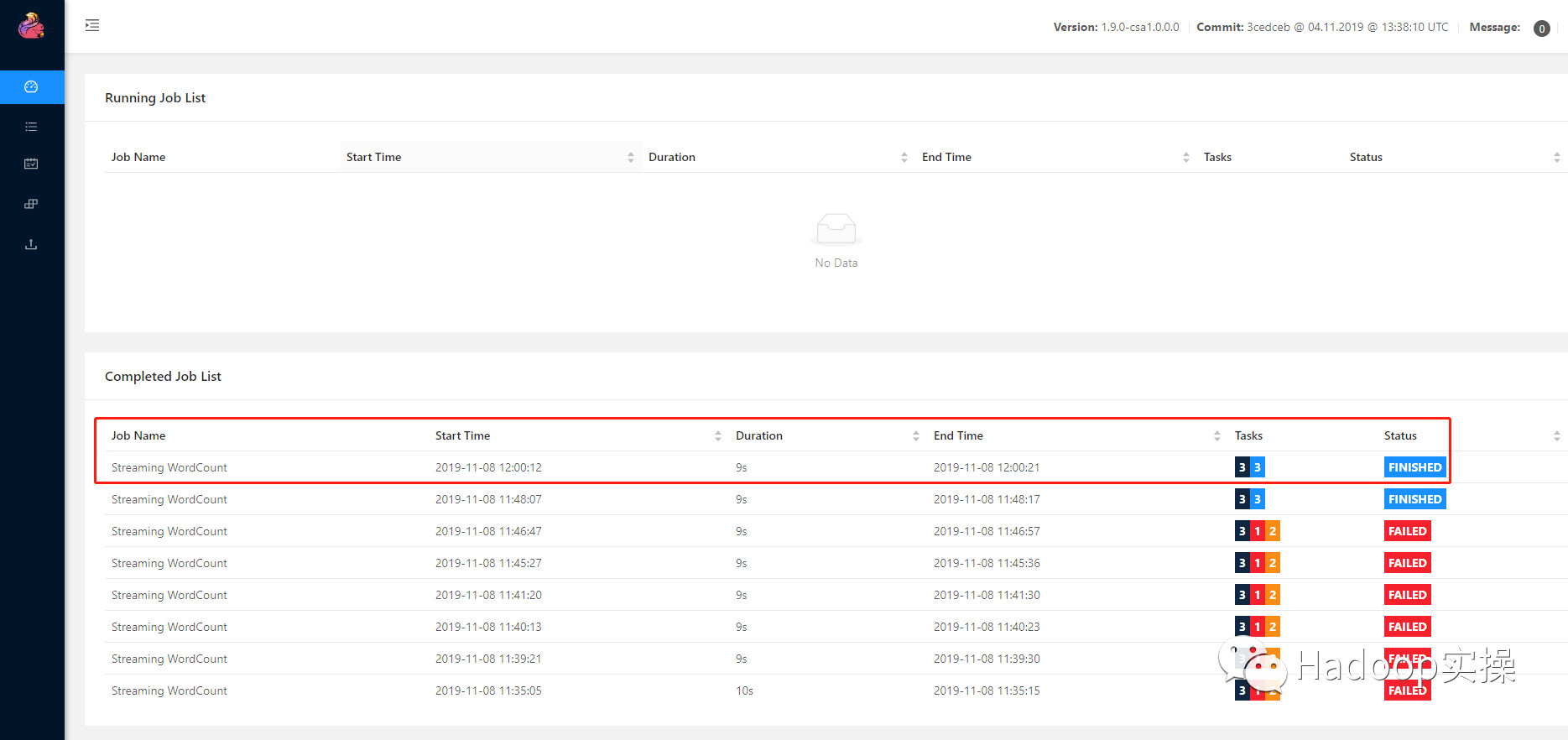
至此,Flink 1.9 安装到 CDH 6.3 以及第一个例子介绍完毕。
备注:这是 Cloudera Streaming Analytics 中所包含 Apache Flink 的抢先测试版。Cloudera 不提供对此版本的支持。该 Beta 版本的目的是让用户可以尽可能早的开始使用 Flink 进行应用程序的开发。
本文作者:巴蜀真人
本文为阿里云内容,未经允许不得转载。
在 Cloudera Data Flow 上运行你的第一个 Flink 例子的更多相关文章
- 阿里云上 配置 vsftpd 配置文件 (一个成功例子)
# # READ THIS: This example file is NOT an exhaustive list of vsftpd options. # Please read the vsft ...
- SSIS的 Data Flow 和 Control Flow
Control Flow 和 Data Flow,是SSIS Design中主要用到的两个Tab,理解这两个Tab的作用,对设计更高效的package十分重要. 一,Control Flow 在Con ...
- 如何在国产龙芯架构平台上运行c/c++、java、nodejs等编程语言
高能预警:本文内容过于硬核,涉及编译器原理.cpu指令集.机器码.编程语言原理.跨平台原理等计算机专业基础知识,建议具有c.c++.java.nodejs等多种编程语言开发能力,且实战经验丰富的资深开 ...
- Spring Cloud Data Flow初体验,以Local模式运行
1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! Spring Cloud Data Flow是什么,虽然已经出现一段时间了,但想必很多人不知道,因为在项目中很少有人用.不仅 ...
- 把Spring Cloud Data Flow部署在Kubernetes上,再跑个任务试试
1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! Spring Cloud Data Flow在本地跑得好好的,为什么要部署在Kubernetes上呢?主要是因为Kubern ...
- SSIS Data Flow优化
一,数据流设计优化 数据流有两个特性:流和在内存缓冲区中处理数据,根据数据流的这两个特性,对数据流进行优化. 1,流,同时对数据进行提取,转换和加载操作 流,就是在source提取数据时,转换组件处理 ...
- Data Flow ->> Union All
Wrox的<Professional Microsoft SQL Server 2012 Integration Services>一书中再讲Merge的时候有这样一段解释: This t ...
- Spring Cloud Data Flow 中的 ETL
Spring Cloud Data Flow 中的 ETL 影宸风洛 程序猿DD 今天 来源:SpringForAll社区 1 概述 Spring Cloud Data Flow是一个用于构建实时数据 ...
- 【SFA官方译文】:Spring Cloud Data Flow中的ETL
原创: 影宸风洛 SpringForAll社区 昨天 原文链接:https://www.baeldung.com/spring-cloud-data-flow-etl 作者:Norberto Ritz ...
随机推荐
- JS实现网页选取截屏 保存+打印 功能(转)
源码地址: 1.1 确定截图选取范围 用户在开始截图后,需要在页面上选取一个截图范围,并且可以直观的看到,类似如下效果: image 我们的选取范围就是鼠标开始按下的那个点到鼠标拖动然后松开的那个点之 ...
- 如何在CBV中使用装饰器
要区分函数装饰器和方法装饰器得区别 ,方法装饰器得第一个参数是self本身,所以函数装饰器不能用
- windows jenkins 发布 springboot项目脚本
windows jenkins 发布 springboot项目脚本 1.关闭现有程序 (按端口关闭) [与按应用关闭 二选一] @echo off for /f "tokens=1-5&q ...
- CDH6.2扩容
参考: yum方式扩容: https://www.cnblogs.com/yinzhengjie/articles/11104776.html 二进制包方式扩容: https://www.cnblog ...
- Node.js使用redis进行订阅发布管理
redis NPM 官方介绍地址:https://www.npmjs.com/package/redis let redis = require('redis'); let subscriber; l ...
- 插入数据库失败([Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version)
报错信息如下: , ) 原因,read是数据库的关键字, 牢记,如果一个词是数据库的关键字,那么在写数据库语句的时候,这个词一定是蓝色的(关键字颜色)!!
- 2017 ACM-ICPC 亚洲区(乌鲁木齐赛区)网络赛 F. Islands
On the mysterious continent of Tamriel, there is a great empire founded by human. To develope the tr ...
- 10.jQuery之停止动画排队stop方法(重点)
重点:stop,在实际项目中,这个细节很重要 <style> * { margin: 0; padding: 0; } li { list-style-type: none; } a { ...
- ArcGIS 在VS2010中 ESRI.ArcGIS.SOESupport.dll 无法正常加载的处理
转自 http://blog.csdn.net/tnt123688/article/details/23186973 问题描述: 打开ArcGIS的SOE模板后,提示 错误 命名空间“ESRI.A ...
- Jade学习(五)之命令编译执行jade
首先全局安装jade,我们就可以使用jade 命令了! jade index.jade // 解析后会在文件夹中新生成一个压缩代码后的index.html 如果我们不想生成的index.html文件进 ...