基于K-means Clustering聚类算法对电商商户进行级别划分(含Octave仿真)
在从事电商做频道运营时,每到关键时间节点,大促前,季度末等等,我们要做的一件事情就是品牌池打分,更新所有店铺的等级。例如,所以的商户分入SKA,KA,普通店铺,新店铺这4个级别,对于不同级别的商户,会给予不同程度的流量扶持或广告策略。通常来讲,在一定时间段内,评估的维度可以有:UV,收订金额,好评率,销退金额,广告位点击率,转化率,pc端流量、手机端流量、客单价......等n多个维度,那么如何在这n多个维度中找到一种算法,来将我们的品牌划分到4个级别中呢?今天所讨论的K-means聚类算法是其中一种,基于某电商频道296个品牌的周销量真实数据,我们来进行品牌池划分。
首先, K-means聚类算法可以描述为如下几步:
1、随机选取K个质心(centroids);
2、计算每个数据点距离K个质心的距离,选择距离最小的一个质心作为该数据点的所属组。例如,某数据点距离#3质心最近,那么它就属于#3组。
3、更新质心的坐标,将每个组的数据点坐标相加求平均值,得出新的质心位置并更新。
4、重复第二和第三步n次。
其中,K和n是提前指定的。
为了将K-means运行过程可视化,我们只取296的品牌的2个维度:UV与收订金额。主控代码如下:
%% ================= Part 1: load data ====================
fprintf('load parameters.\n\n');
pkg load io;
tmp = xlsread('data.xlsx');
id=tmp(:,1);
X=tmp(:,2:3); %% =================== Part 2: set parameters ======================
K = 4;
max_iters = 10; %% =================== Part 3: K-Means Clustering ======================
fprintf('\nRunning K-Means clustering on example dataset.\n\n');
initial_centroids = kMeansInitCentroids(X,K);
% Run K-Means algorithm. The 'true' at the end tells our function to plot
% the progress of K-Means
[centroids, idx] = runkMeans(X, initial_centroids, max_iters, true);
fprintf('\nK-Means Done.\n\n');
K-Means Clustering Algorithm核心代码:
function [centroids, idx] = runkMeans(X, initial_centroids, ...
max_iters, plot_progress)
[m n] = size(X);
K = size(initial_centroids, 1);
centroids = initial_centroids;
previous_centroids = centroids;
idx = zeros(m, 1); % Run K-Means
for i=1:max_iters % Output progress
fprintf('K-Means iteration %d/%d...\n', i, max_iters);
if exist('OCTAVE_VERSION')
fflush(stdout);
end % For each example in X, assign it to the closest centroid
idx = findClosestCentroids(X, centroids); % Given the memberships, compute new centroids
centroids = computeCentroids(X, idx, K);
end
end
选择最近质心的算法:
function idx = findClosestCentroids(X, centroids)
K = size(centroids, 1);
idx = zeros(size(X,1), 1);
m = size(X,1); for(i = 1:m)
distance = -1;
index = -1;
for(j=1:K)
e = X(i,:)-centroids(j,:);
d_tmp = e*e';
if(distance == -1)
distance = d_tmp;
index = j;
else
if (d_tmp<distance)
distance = d_tmp;
index = j;
endif
endif
endfor
idx(i) = index;
endfor
end
重新计算质心及初始化质心的算法:
function centroids = computeCentroids(X, idx, K)
[m n] = size(X);
centroids = zeros(K, n); num = zeros(K,1); for(i = 1:m)
c = idx(i,:);
centroids(c,:) += X(i,:);
num(c,:)++;
endfor centroids = centroids./num; function centroids = kMeansInitCentroids(X, K)
centroids = zeros(K, size(X, 2));
randidx = randperm(size(X, 1));
centroids = X(randidx(1:K), :);
end
经过十次迭代后,分组的结果如下:
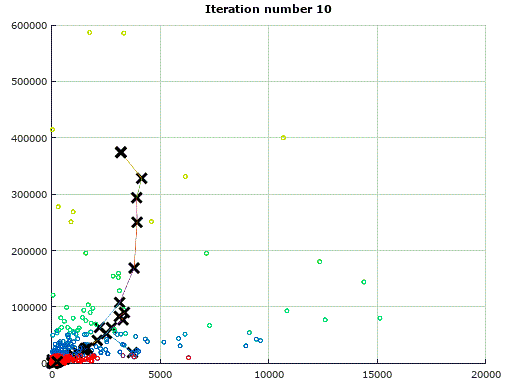
在我本地的原始数据表格中,共有约20个维度来衡量每个店铺的运行情况,根据K-means聚类算法可以很轻松的将它们归类,虽然无法将其进行可视化操作,但原理与二维K-means完全相同。
基于K-means Clustering聚类算法对电商商户进行级别划分(含Octave仿真)的更多相关文章
- 项目实战2—实现基于LVS负载均衡集群的电商网站架构
负载均衡集群企业级应用实战-LVS 实现基于LVS负载均衡集群的电商网站架构 背景:随着业务的发展,网站的访问量越来越大,网站访问量已经从原来的1000QPS,变为3000QPS,网站已经不堪重负,响 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 实现基于LVS负载均衡集群的电商网站架构
背景 上一期我们搭建了小米网站,随着业务的发展,网站的访问量越来越大,网站访问量已经从原来的1000QPS,变为3000QPS,网站已经不堪重负,响应缓慢,面对此场景,单纯靠单台LNMP的架构已经无法 ...
- 基于rabbitMQ 消息延时队列方案 模拟电商超时未支付订单处理场景
前言 传统处理超时订单 采取定时任务轮训数据库订单,并且批量处理.其弊端也是显而易见的:对服务器.数据库性会有很大的要求,并且当处理大量订单起来会很力不从心,而且实时性也不是特别好 当然传统的手法还可 ...
- 各类聚类(clustering)算法初探
1. 聚类简介 0x1:聚类是什么? 聚类是一种运用广泛的探索性数据分析技术,人们对数据产生的第一直觉往往是通过对数据进行有意义的分组.很自然,首先要弄清楚聚类是什么? 直观上讲,聚类是将对象进行分组 ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
- 机器学习:Python实现聚类算法(三)之总结
考虑到学习知识的顺序及效率问题,所以后续的几种聚类方法不再详细讲解原理,也不再写python实现的源代码,只介绍下算法的基本思路,使大家对每种算法有个直观的印象,从而可以更好的理解函数中参数的意义及作 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 密度峰值聚类算法(DPC)
密度峰值聚类算法(DPC) 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 简介 基于密度峰值的聚类算法全称为基于快速搜索和发现密度峰值的聚类算法(cl ...
随机推荐
- java实战应用:MyBatis实现单表的增删改
MyBatis 是支持普通 SQL查询.存储过程和高级映射的优秀持久层框架.MyBatis 消除了差点儿全部的JDBC代码和參数的手工设置以及结果集的检索.MyBatis 使用简单的 XML或注解用于 ...
- 垂直口风琴菜单3(jquery)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- python学习笔记(10):面向对象
一.类和实例 1.类(Class): 用来描述具有相同的属性和方法的对象的集合.它定义了该集合中每个对象所共有的属性和方法.对象是类的实例. 2.对象:通过类定义的数据结构实例.对象包括两个数据成员( ...
- DAG
DAG的生成 DAG(Directed Acyclic Graph) 叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依 ...
- ios UIWebView加载HTMLStr图文,关于图片宽高设置,webView内容实际高度的踩坑问题
一.关于UIWebView 与 WKWebView 选取问题 从发布时间看: 2008年7月11日,在新一代iPhone3G正式发售当天,iPhone OS 2.0(iOS 2.0)推出,这时候就有U ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
- Jupyter Notebook 安装与使用
Ref: https://jupyter.org/install Installing Jupyter Notebook with pip python -m pip install --upgrad ...
- AOP切面详解
一.spring-aop.xml文件 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns= ...
- Java 多态概念、使用
1.概念 2.多态的格式与使用 package Java12; /* 代码当中体现多态性,其实就是一句话: 父类引用指向子类对象 格式: 父类名称 对象名 = new 子类名称(): 或者: 接口名称 ...
- bat 获取系统日期,时间,并去掉时间小时前面的空格和时间后面的空格
@echo off rem BAT获取系统日期,时间,并去掉时间小时前面的空格和时间后面的空格 echo *** %DATE% echo *** %TIME% set THISDATE=%DATE:~ ...