MySQL: InnoDB的并发控制,锁,事务模型
一、并发控制
为啥要进行并发控制?
并发的任务对同一个临界资源进行操作,如果不采取措施,可能导致不一致,故必须进行并发控制(Concurrency Control)。
技术上,通常如何进行并发控制?
通过并发控制保证数据一致性的常见手段有:
锁(Locking)
数据多版本(Multi Versioning)
二、锁
如何使用普通锁保证一致性?
普通锁,被使用最多:
(1)操作数据前,锁住,实施互斥,不允许其他的并发任务操作;
(2)操作完成后,释放锁,让其他任务执行;
如此这般,来保证一致性。
普通锁存在什么问题?
简单的锁住太过粗暴,连“读任务”也无法并行,任务执行过程本质上是串行的。
于是出现了共享锁与排他锁:
共享锁(Share Locks,记为S锁),读取数据时加S锁
排他锁(eXclusive Locks,记为X锁),修改数据时加X锁
共享锁与排他锁的玩法是:
共享锁之间不互斥,简记为:读读可以并行
排他锁与任何锁互斥,简记为:写读,写写不可以并行
可以看到,一旦写数据的任务没有完成,数据是不能被其他任务读取的,这对并发度有较大的影响。
画外音:对应到数据库,可以理解为,写事务没有提交,读相关数据的select也会被阻塞。
有没有可能,进一步提高并发呢?
即使写任务没有完成,其他读任务也可能并发,这就引出了数据多版本。
三、数据多版本
数据多版本是一种能够进一步提高并发的方法,它的核心原理是:
(1)写任务发生时,将数据克隆一份,以版本号区分;
(2)写任务操作新克隆的数据,直至提交;
(3)并发读任务可以继续读取旧版本的数据,不至于阻塞;
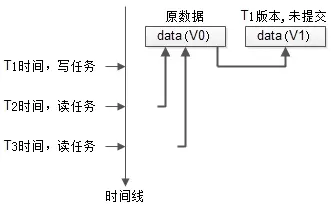
如上图:
1. 最开始数据的版本是V0;
2. T1时刻发起了一个写任务,这是把数据clone了一份,进行修改,版本变为V1,但任务还未完成;
3. T2时刻并发了一个读任务,依然可以读V0版本的数据;
4. T3时刻又并发了一个读任务,依然不会阻塞;
可以看到,数据多版本,通过“读取旧版本数据”能够极大提高任务的并发度。
提高并发的演进思路,就在如此:
普通锁,本质是串行执行
读写锁,可以实现读读并发
数据多版本,可以实现读写并发
画外音:这个思路,比整篇文章的其他技术细节更重要,希望大家牢记。
好,对应到InnoDB上,具体是怎么玩的呢?
四、redo, undo,回滚段
在进一步介绍InnoDB如何使用“读取旧版本数据”极大提高任务的并发度之前,有必要先介绍下redo日志,undo日志,回滚段(rollback segment)。
为什么要有redo日志?
数据库事务提交后,必须将更新后的数据刷到磁盘上,以保证ACID特性。磁盘随机写性能较低,如果每次都刷盘,会极大影响数据库的吞吐量。
优化方式是,将修改行为先写到redo日志里(此时变成了顺序写),再定期将数据刷到磁盘上,这样能极大提高性能。
画外音:这里的架构设计方法是,随机写优化为顺序写,思路更重要。
假如某一时刻,数据库崩溃,还没来得及刷盘的数据,在数据库重启后,会重做redo日志里的内容,以保证已提交事务对数据产生的影响都刷到磁盘上。
一句话,redo日志用于保障,已提交事务的ACID特性。
为什么要有undo日志?
数据库事务未提交时,会将事务修改数据的镜像(即修改前的旧版本)存放到undo日志里,当事务回滚时,或者数据库奔溃时,可以利用undo日志,即旧版本数据,撤销未提交事务对数据库产生的影响。
画外音:更细节的,
对于insert操作,undo日志记录新数据的PK(ROW_ID),回滚时直接删除;
对于delete/update操作,undo日志记录旧数据row,回滚时直接恢复;
他们分别存放在不同的buffer里。
一句话,undo日志用于保障,未提交事务不会对数据库的ACID特性产生影响。
什么是回滚段?
存储undo日志的地方,是回滚段。
undo日志和回滚段和InnoDB的MVCC密切相关,这里举个例子展开说明一下。
栗子:
t(id PK, name);
数据为:
1, shenjian
2, zhangsan
3, lisi
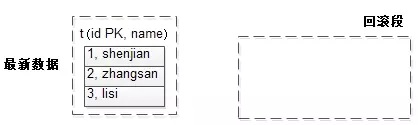
此时没有事务未提交,故回滚段是空的。
接着启动了一个事务:
start trx;
delete (1, shenjian);
update set(3, lisi) to (3, xxx);
insert (4, wangwu);
并且事务处于未提交的状态。
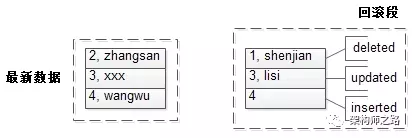
可以看到:
(1)被删除前的(1, shenjian)作为旧版本数据,进入了回滚段;
(2)被修改前的(3, lisi)作为旧版本数据,进入了回滚段;
(3)被插入的数据,PK(4)进入了回滚段;
接下来,假如事务rollback,此时可以通过回滚段里的undo日志回滚。
画外音:假设事务提交,回滚段里的undo日志可以删除。
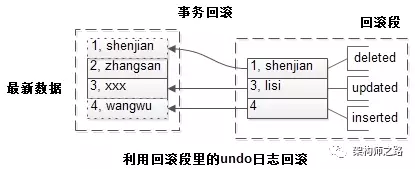
可以看到:
(1)被删除的旧数据恢复了;
(2)被修改的旧数据也恢复了;
(3)被插入的数据,删除了;
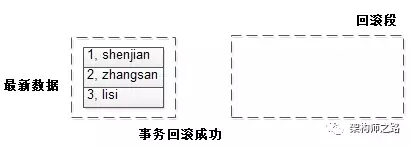
事务回滚成功,一切如故。
四、InnoDB是基于多版本并发控制的存储引擎
《大数据量,高并发量的互联网业务,一定要使用InnoDB》提到,InnoDB是高并发互联网场景最为推荐的存储引擎,根本原因,就是其多版本并发控制(Multi Version Concurrency Control, MVCC)。行锁,并发,事务回滚等多种特性都和MVCC相关。
MVCC就是通过“读取旧版本数据”来降低并发事务的锁冲突,提高任务的并发度。
核心问题:
旧版本数据存储在哪里?
存储旧版本数据,对MySQL和InnoDB原有架构是否有巨大冲击?
通过上文undo日志和回滚段的铺垫,这两个问题就非常好回答了:
(1)旧版本数据存储在回滚段里;
(2)对MySQL和InnoDB原有架构体系冲击不大;
InnoDB的内核,会对所有row数据增加三个内部属性:
(1)DB_TRX_ID,6字节,记录每一行最近一次修改它的事务ID;
(2)DB_ROLL_PTR,7字节,记录指向回滚段undo日志的指针;
(3)DB_ROW_ID,6字节,单调递增的行ID;
InnoDB为何能够做到这么高的并发?
回滚段里的数据,其实是历史数据的快照(snapshot),这些数据是不会被修改,select可以肆无忌惮的并发读取他们。
快照读(Snapshot Read),这种一致性不加锁的读(Consistent Nonlocking Read),就是InnoDB并发如此之高的核心原因之一。
这里的一致性是指,事务读取到的数据,要么是事务开始前就已经存在的数据(当然,是其他已提交事务产生的),要么是事务自身插入或者修改的数据。
什么样的select是快照读?
除非显示加锁,普通的select语句都是快照读,例如:
select * from t where id>2;
这里的显示加锁,非快照读是指:
select * from t where id>2 lock in share mode;
select * from t where id>2 for update;
问题来了,这些显示加锁的读,是什么读?会加什么锁?和事务的隔离级别又有什么关系?
本节的内容已经够多了,且听下回分解。
总结
(1)常见并发控制保证数据一致性的方法有锁,数据多版本;
(2)普通锁串行,读写锁读读并行,数据多版本读写并行;
(3)redo日志保证已提交事务的ACID特性,设计思路是,通过顺序写替代随机写,提高并发;
(4)undo日志用来回滚未提交的事务,它存储在回滚段里;
(5)InnoDB是基于MVCC的存储引擎,它利用了存储在回滚段里的undo日志,即数据的旧版本,提高并发;
(6)InnoDB之所以并发高,快照读不加锁;
(7)InnoDB所有普通select都是快照读;
画外音:本文的知识点均基于MySQL5.6。
出处:https://mp.weixin.qq.com/s/R3yuitWpHHGWxsUcE0qIRQ
MySQL: InnoDB的并发控制,锁,事务模型的更多相关文章
- mysql innodb存储引擎 锁 事务
以下内容翻译自mysql5.6官方手册. InnoDB是一种通用存储引擎,可平衡高可靠性和高性能.在MySQL 5.6中,InnoDB是默认的MySQL存储引擎.除非已经配置了不同的默认存储引擎, ...
- MySql InnoDB中的锁研究
# MySql InnoDB中的锁研究 ## 1.InnoDB中有哪些锁### 1. 共享和排他(独占)锁(Shared and Exclusive Locks) InnoDB实现标准的行级锁定,其中 ...
- MySQL/InnoDB中,对于锁的认识
MySQL/InnoDB的加锁,一直是一个面试中常问的话题.例如,数据库如果有高并发请求,如何保证数据完整性?产生死锁问题如何排查并解决?我在工作过程中,也会经常用到,乐观锁,排它锁,等.于是今天就对 ...
- 【译文】MySQL InnoDB 使用的锁分析
InnoDB 使用的 锁类型 共享锁和排它锁 意向锁 记录锁 间隙锁 Next-key 锁 插入意向锁 AUTO-INC 锁 共享锁和排他锁 InnoDB实现了俩个标准的行级锁,共享锁和排它锁. 共享 ...
- Mysql InnoDB 数据更新导致锁表
一.数据表结构 CREATE TABLE `jx_attach` ( `attach_id` int(11) NOT NULL AUTO_INCREMENT, `feed_id` int(11) DE ...
- mysql innodb 行级锁升级
创建数据表test,表定义如下所示: CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) NO ...
- mysql InnoDB 的行锁
表的引擎类型必须为InnoDB才可以进行此操作. 相关链接:http://www.cnblogs.com/CyLee/p/5579672.html 共享锁:单独运行前两句,然后新建一个会话使用第三句. ...
- Mysql InnoDB的四个事务隔离级别和(分别逐级解决的问题)脏读,不可重复读,虚读
MySqlInnoDB的事务隔离级别有四个:(默认是可重复读repeatable read) 未提交读 read uncommit : 在另一个事务修改了数据,但尚未提交,在本事务中SELECT语句可 ...
- 从一个死锁看mysql innodb的锁机制
背景及现象 线上生产环境在某些时候经常性的出现数据库操作死锁,导致业务人员无法进行操作.经过DBA的分析,是某一张表的insert操 作和delete操作发生了死锁.简单介绍下数据库的情况(因为涉及到 ...
随机推荐
- Power-Aware GateSim Debug
For PAG debug, the following steps may be useful. 1. Get correct netlists from PD which contain powe ...
- Python爬虫十六式 - 第四式: 使用Xpath提取网页内容
Xpath:简单易用的网页内容提取工具 学习一时爽,一直学习一直爽 ! Hello,大家好,我是Connor,一个从无到有的技术小白.上一次我们说到了 requests 的使用方法.到上节课为止, ...
- hdu 1754 线段树 水题 单点更新 区间查询
I Hate It Time Limit: 9000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- Rust:剑指C++
Rust:极富活力和前途的编程语言,剑指C++ 今天开始学习Rust,马上要回去休息了,只贴上一段实例代码,在后续的学习中,会对这种语言进行一个详尽的介绍(学习中....). extern crate ...
- [CSP-S模拟测试]:Walker(数学)
题目传送门(内部题86) 输入格式 第一行$n$接下来$n$行,每行四个浮点数,分别表示变换前的坐标和变换后的坐标 输出格式 第一行浮点数$\theta$以弧度制表示第二行浮点数$scale$第三行两 ...
- bootstrap的editTable实现方法
首先下载基于bootstrap的源码到本地.引用相关文件. <link href="/Content/bootstrap/css/bootstrap.min.css" rel ...
- Vue 使用v-bind:style 绑定样式
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- SpringBoot整合Shiro实现权限控制,验证码
本文介绍 SpringBoot 整合 shiro,相对于 Spring Security 而言,shiro 更加简单,没有那么复杂. 目前我的需求是一个博客系统,有用户和管理员两种角色.一个用户可能有 ...
- 获取免费的https证书
可以通过网站获取免费的https证书 首先到https://freessl.org注册一个账号 然后就可以开始创建免费证书了 获取的证书里面通常只有pem后缀文件 nodejs使用的时候需要crt文件 ...
- leetcode-mid-math-202. Happy Number-NO
mycode 关键不知道怎么退出循环.............其实只要有一个平方和以前出现过,那么整个计算过程就会重复 参考: class Solution(object): def isHappy( ...