一致性Hash算法的原理与实现(分布式映射算法)
一致性Hash算法解决的问题:
解决分布式系统中的负载均衡问题
背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务
硬Hash映射:将每台服务器结点进行编号,0到N-1,Key%N就是映射到的服务器结点编号
硬Hash映射存在的问题:当分布式系统中服务器结点个数N变化的时候,每个Key对应的服务器结点的映射关系都要被改变,这会导致大量的Key会被重定向到不同的服务器结点上从而造成大量的缓存不命中,这种情况在分布式系统中是非常糟糕的,这个就是所谓的缓存雪崩,当这种情况发生时,服务器的数据库会存在非常大的压力,很可能会直接宕机
怎么解决硬Hash映射存在的问题?
一致性Hash算法
一致性Hash算法
原理:将整个Hash空间组织成一个虚拟的圆环,如假设某个哈希函数H的值的空间为0到2的32次方-1,即hash值是一个32位的无符号整型数,整个Hash空间环如下:
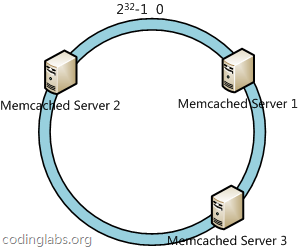
下一步将各个服务器结点使用H哈希函数进行哈希映射,具体可以选择服务器的IP或者主机名作为关键字进行映射,这样每台服务器就能确定其在Hash空间上的位置,比如下图:
接下来我们将数据对象映射到Hash空间环上,假设我们有A,B,C,D四个数据对象,他们的Hash空间环上的位置如下:
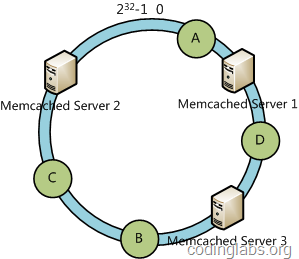
接下来就是怎么把数据对象映射到服务器结点的问题,映射规则:每个数据对象顺时针遇到的第一个服务器结点就是映射到的服务器结点,根据一致性Hash算法:A会被映射到服务结点1,D会被映射到服务器结点3,BC会被映射到服务器结点2
那一致性Hash算法的优势到底在哪里呢?
我们现在假设两种情况:
情况1:服务器3宕机了,不可用了
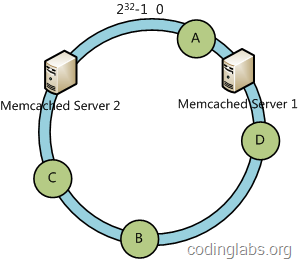
这种情况下,A还是映射到服务结点1,BC还是映射到服务结点2,因为服务器结点3宕机了,数据对象D无法映射到服务器结点3,根据我们的映像规则:数据对象D也映射到服务器结点2,我们可以发现当服务器结点3宕机的时候,影响到的数据对象只有服务器3和服务器1之间的数据对象,也就是数据对象D,对比硬Hash映射:当服务器结点N变化的时候,采用一致性Hash算法影响到的数据对象更少,也就是很多的映射关系对象都不用改变,不会造成缓存雪崩
情况2:新增一个服务器结点4
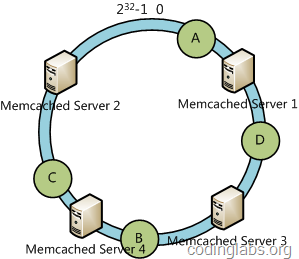
这种情况下,映射关系被改变的只有数据对象B,即新增服务器结点3和服务器结点3之间的数据对象(新增服务器结点逆时针遇到的第一个服务器结点)
这样情况下,当服务器结点数量N变化的时候,被影响的数据对象也很少,所以一致性Hash算法确实是有用的
当然有一种特殊情况需要我们考虑一下:
当服务器结点太少且服务器结点的Hash值台解决时,容易造成因为结点分布不均而造成的数据对象倾斜问题,比如下图:
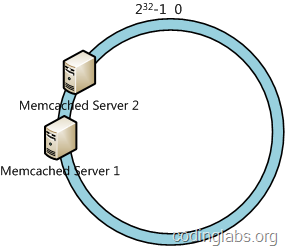
这种情况容易造成数据对象大大部分映射到服务器结点1的问题(数据倾斜问题),这样服务器结点1压力很大,而服务2却很空闲
那怎么解决这种问题呢?
采用虚拟结点的方式,即对每一个服务器结点计算多个Hash值,每个计算结果位置都放置一个服务器结点,叫做虚拟结点,具体可以在服务器IP或者主机名后面增加编号实现,比如下图:
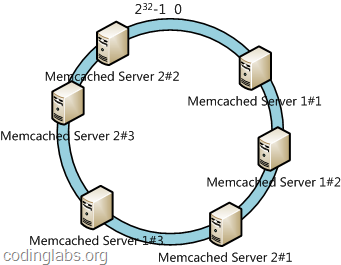
这样数据对象倾斜问题将会得到有效的解决
一致性Hash算法的原理与实现(分布式映射算法)的更多相关文章
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- 分方式缓存常用的一致性hash是什么原理
分方式缓存常用的一致性hash是什么原理 一致性hash是用来解决什么问题的?先看一个场景有n个cache服务器,一个对象object映射到哪个cache上呢?可以采用通用方法计算object的has ...
- 一致性hash和solr千万级数据分布式搜索引擎中的应用
互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中 获得成功,这个和当前的开源技术.海量数据架构有着必不可分的关 ...
- redis分布式映射算法
redis分布式映射算法 一致性Hash算法的原理和实现 为了解决分布式系统中的负载均衡的问题 背景问题 有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载 ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
- 给面试官讲明白:一致性Hash的原理和实践
"一致性hash的设计初衷是解决分布式缓存问题,它不仅能起到hash作用,还可以在服务器宕机时,尽量少地迁移数据.因此被广泛用于状态服务的路由功能" 01分布式系统的路由算法 假设 ...
- 一致性Hash的原理与实现
应用场景 在了解一致性Hash之前,我们先了解一下一致性Hash适用于什么场景,能解决什么问题?这里先放一下我自己认为适用的场景.一致性Hash适用于服务器动态扩展且需要负载均衡的场景 试想以下场景, ...
- Golang 实现 Redis(7): Redis 集群与一致性 Hash
本文是使用 golang 实现 redis 系列的第七篇, 将介绍如何将单点的缓存服务器扩展为分布式缓存.godis 集群的源码在Github:Godis/cluster 单台服务器的CPU和内存等资 ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
随机推荐
- 2018-09-28 用Python3和tkinter开发简单图形界面程序
源码库: program-in-chinese/wubi_code_editor 起因在这里. 由于此项目和汉字相关, 个人也想尝试Python的图形界面开发, 于是开始尝试. 遇到的一个坑. 用户测 ...
- 开发Spring过程中几个常见异常(一)
异常一:java.lang.NoClassDefFoundError: org/apache/commons/logging/LogFactory 原因:未导入有关日志管理的jar包或者未添加到路径. ...
- Tomcat_记一次tomcatwar包应用简单部署过程
记一次tomcat war包应用简单部署过程 by:授客 QQ:1033553122 1. 实践环境 Linux apache-tomcat-7.0.73 2. 实践步骤 # 解压tomcat压缩 ...
- matlab练习程序(点云表面法向量)
思路还是很容易想到的: 1.首先使用KD树寻找当前点邻域的N个点,这里取了10个,直接调用了vlfeat. 2.用最小二乘估计当前邻域点组成的平面,得到法向量. 3.根据当前邻域点平均值确定邻域质心, ...
- 使用VSTS的Git进行版本控制(二)——提交保存工作
使用VSTS的Git进行版本控制(二)--提交保存工作 当对文件进行更改时,Git将在本地仓库中记录更改.可以通过选择变更来提交的对应更改.提交总是针对本地的Git仓库,因此不必担心提交是完美的,或者 ...
- java----构造回文字符串java(动态规划)【手写演算残图】
问题描述 草稿解决过程 (字丑别喷) 代码实现 import java.util.Scanner; /** * Created by Admin on 2017/3/26. */ public cla ...
- Linux系统网络文件配置
/etc 一.修改配置文档(需要重启网络配置,永远生效) 1.修改IP地址[MariaDB@db1]$ vi /etc/sysconfig/network-scripts/ifcfg-eth0DEV ...
- Windows Server 2016-配置Windows Defender防病毒排除项
Windows Server 2016 的计算机上的 Windows Defender 防病毒自动注册你在某些排除项,由你指定的服务器角色定义. 这些排除项不会显示在Windows 安全中心应用中所示 ...
- eclipse版本对应名称以及下载地址
Eclipse 1.0 2001年11月7日(Win32/Linux32 Motif) Eclipse 2.0 2002年6月27日(Linux32 Motif ...
- linux 查看命令 ls-list
1. ls 基础常用 显示指定目录下的文件列表 list ls -lthr /floder l 长的列表格式 lang 能查看到常用大部分信息 t 按时间先后排序 (sort排序) tim ...