Hadoop学习笔记(二):简单操作
1. 启动namenode和datanode,在master上输入命令hdsf dfsadmin -report查看整个集群的运行情况(记得关闭防火墙)
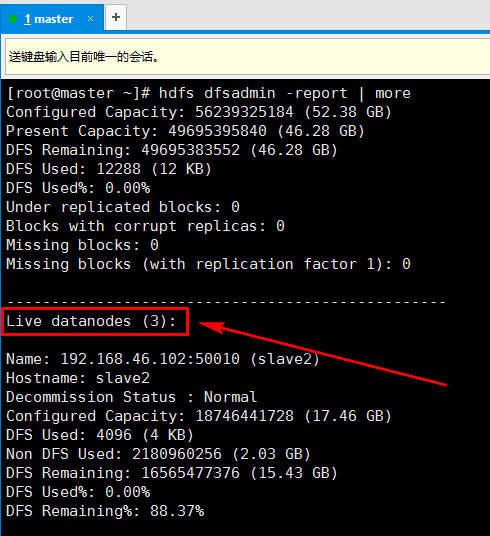
2. 输入命令查看hadoop监听的端口,netstat -ntlp
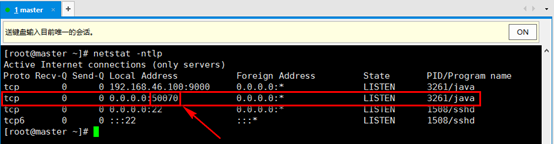
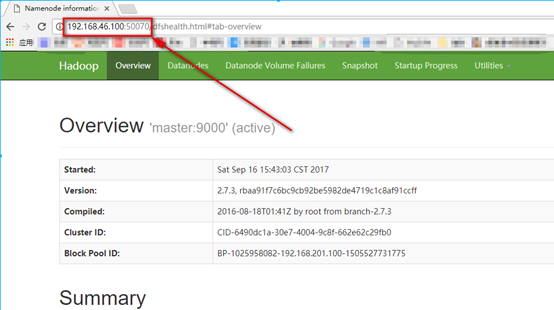
3. 在宿主机浏览器输入{masterIP}:50070进行查看
4. 关闭集群
master机器命令:hadoop-daemon.sh stop namenode
slave机器命令:hadoop-daemon.sh stop datanode
5. 创建集中式管理,在master机器上操作。输入命令
vim /usr/local/hadoop/etc/hadoop/slaves
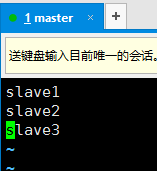
6. 经过上一个步骤的操作后,可以在master机器上,集中的管理控制namenode和所有的datanode。在master机器上,启动所有的hadoop服务,输入命令start-dfs.sh,输入相应的密码,然后输入jps查看(该命令会默认启动SecondaryNameNode)
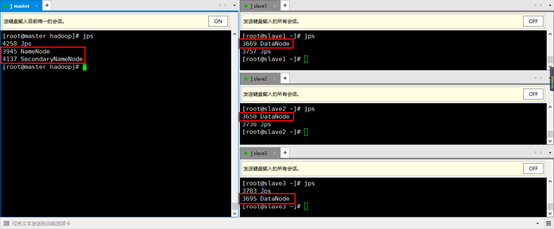
7. 步骤6的时候,需要输入很多密码,下面设置免密登录:
a). 在master机器中进入~/.ssh目录:cd ~/.ssh/
b). 输入ssh-keygen -t rsa,然后一直敲回车
c). 命令结束后,该目录下会多出两个文件

id_rsa为当前root用户的私钥,id_rsa.pub是公钥
d). 将公钥拷贝到所有的datanode机器上,这样,当master机器拿着经过私钥加密的登录信息发送到datanode机器的时候,datanode机器里存储的公钥可以解开,证明是该用户登录,因此就能够实现免密码登录。
e). 拷贝id_rsa.pub的方法,在master机器上输入命令ssh-copy-id slave1,输入密码,即可将公钥拷贝至slave1机器中。
f). 去到slave1机器的~/.ssh目录下查看,有authorized_keys文件表示拷贝成功
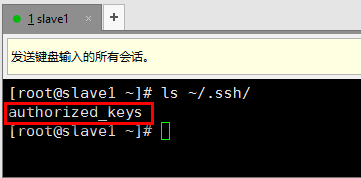
g). 回到master机器上,输入ssh slave1进行远程登录,发现不用输入密码即可登录成功,即实现了免密登录。
h). 同理,将id_rsa.pub文件拷贝到其他datanode机器上,并且,也给自己拷贝一份,即拷贝一份到master机器上。
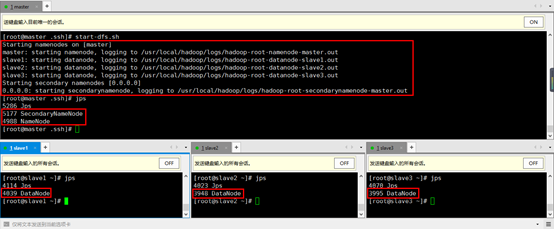
8. 停止集群stop-dfs.sh
9. 再次启动集群start-dfs.sh发现不用输入密码了
10. 查看hadoop根目录下的文件hadoop fs -ls /(也可将hadoop fs替换为hdfs dfs,目前集群刚刚创建,目录为空,此外,删除等命令跟linux命令类似,例如hdfs dfs -rm -r -f /a.txt,其他hdfs命令可以去找度娘和谷老师)
11. 上传一个文件到hadoop(master机器上操作)
a). 上传/usr/local目录下的hadoop-2.7.3.tar.gz文件,hadoop默认的block为128M,该文件为214M,因此会被分块。
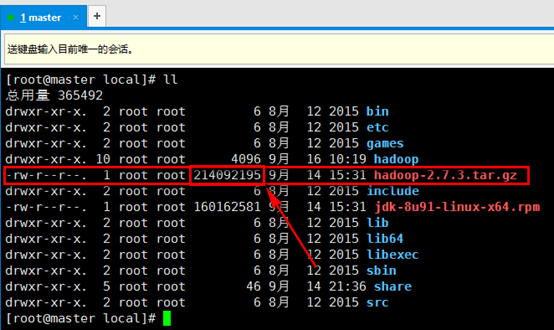
b). 输入命令hadoop fs -put ./hadoop-2.7.3.tar.gz /,前面的./hadoop-2.7.3.tar.gz为上传的文件本地的存放路径,后边的/为存放到hadoop的路径。
c). 输入hadoop fs -ls /查看刚刚上传的文件
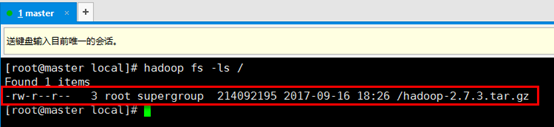
d). 通过网页查看刚才上传的文件,点击Utilsities->Borwse the file system
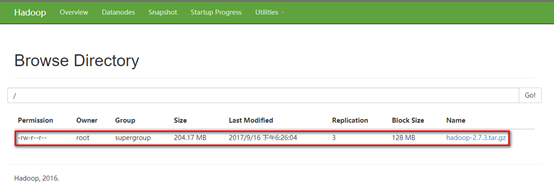
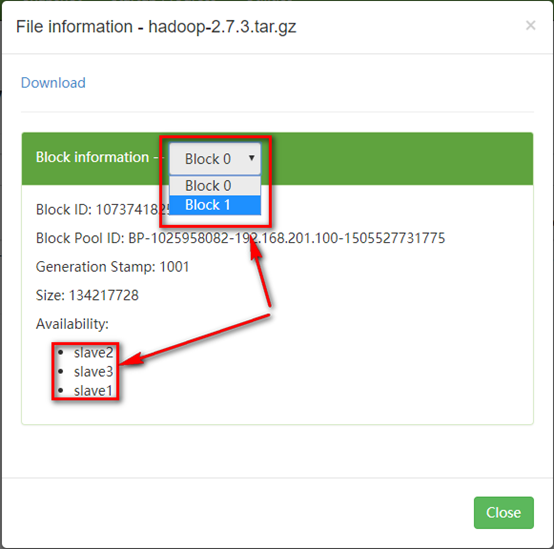
e). 点击该文件,发现该文件被分成了两个块。并且每块复制了三份保存在了datanode当中。
12. hadoop分块后,默认会把块复制三份,以便在出现特殊情况的时候进行恢复,这个数字可以修改,下面就将这个默认复制三份改成两份。(在master机器上进行修改)
a). 编辑/usr/local/hadoop/etc/hadoop/hdfs-site.xml文件,在configuration节点中添加如下内容

具体的配置说明,可查看hadoop安装目录下hadoop-2.7.3/share/doc/hadoop/index.html文件

b). 关闭集群stop-dfs.sh,启动集群start-dfs.sh(重启hadoop)
c). 根据上述,将jdk的安装文件上传到集群当中,登录网页观察。

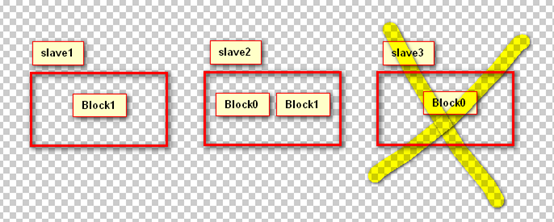
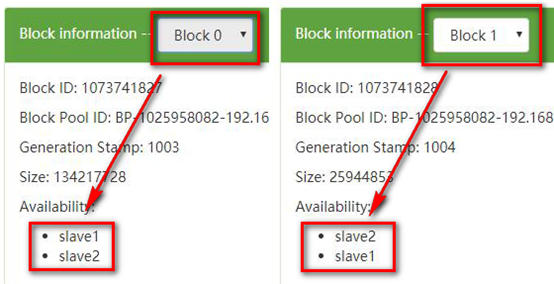
通过上图发现,上传的文件被分割成了两个block块,其中Block0放在了slave2和slave3上边,Block1放在了slave1和slave2上边,此时,如果我们干掉slave3,即如下图所示,那么Block0就只剩下一份了,而我们的配置文件当中设置的是两份,我们测试一下hadoop会不会再帮我们复制一份出来(答案是会,这就是自动冗余)。
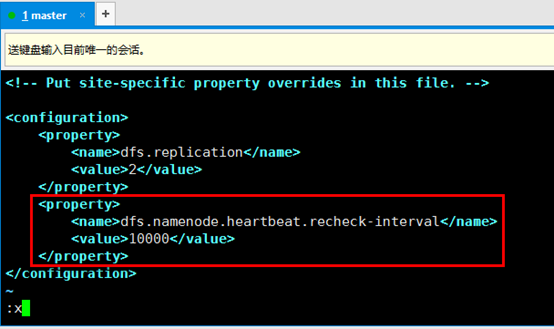
d). 在进行上述实验之前,我们还要配置一个选项

该属性表示,hadoop在多少时间间隔后对datanode进行一次检测,检测它们是否宕机,单位是毫秒,默认为300000,也就是5分钟,我们修改成小一点的值,不然还要等待漫长的5分钟。同样修改/usr/local/hadoop/etc/hadoop/hdfs-site.xml文件,将值改为10000,即10秒钟,然后重新启动hadoop。
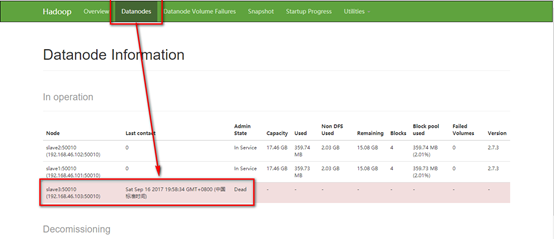
e). 在slave3机器上,关闭hadoop服务:hadoop-daemon.sh stop datanode,默默的等待10秒钟,9、8、7、6。。。
f). 去到网页观察slave3确认已经死亡
g). 再次查看jdk文件的情况,发现Block0又在slave1当中被复制了一份,验证了上述的结果。
13. 思考:此时再次启动slave3,而slave3里有一份Block0备份,那么这样的话Block0就一共有三份备份了,而我们配置的是两个备份,考虑这个时候启动slave3,会不会删掉一份Block0呢?
Hadoop学习笔记(二):简单操作的更多相关文章
- Html学习笔记(二) 简单标签
标签的重点 标签的用途 标签在浏览器中的默认样式 <body>标签: 在网页上显示的内容 <p>标签: 添加段落 <hx>标签: 添加标题 标签一共有6个,h1.h ...
- Java设计模式学习笔记(二) 简单工厂模式
前言 本篇是设计模式学习笔记的其中一篇文章,如对其他模式有兴趣,可从该地址查找设计模式学习笔记汇总地址 正文开始... 1. 简介 简单工厂模式不属于GoF23中设计模式之一,但在软件开发中应用也较为 ...
- Hadoop-HBASE案例分析-Hadoop学习笔记<二>
之前有幸在MOOC学院抽中小象学院hadoop体验课. 这是小象学院hadoop2.X概述第八章的笔记 主要介绍HBase,一个分布式数据库的应用案例. 案例概况: 1)时间序列数据库(OpenTSD ...
- Hadoop学习笔记二
一.设置无密码sudo权限,不用在普通用户和root用户间来回切换 chmod u+w /etc/sudoers vim /etc/sudoers #首行添加如下的内容: hadoop ALL=(ro ...
- hadoop 学习笔记二
NameNode的持久化(persistent)(day4,1) 类似于:Redis redis中的持久化文件是相互独立的当两个持久化文件同时存在时默认使用的是aof ,但是namenode 的持久化 ...
- Hadoop学习笔记——入门指令操作
假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop. 启动与关闭启动HADOOP1. 进入HADOOP_HOME目录. 2. 执行sh bin/start-all. ...
- MongoDB学习笔记二—Shell操作
数据类型 MongoDB在保留JSON基本键/值对特性的基础上,添加了其他一些数据类型. null null用于表示空值或者不存在的字段:{“x”:null} 布尔型 布尔类型有两个值true和fal ...
- redis 学习笔记二 (简单动态字符串)
redis的基本数据结构是动态数组 一.c语言动态数组 先看下一般的动态数组结构 struct MyData { int nLen; char data[0]; }; 这是个广泛使用的常见技巧,常用来 ...
- hadoop学习笔记叁--简单应用
1.通过命令向HDFS传输文件 上传:./hadoop fs -put hdfs.cmd (本地文件名) hdfs://主机名称:9000/ hadoop fs -copyFromLoca ...
- Python学习笔记_03:简单操作MongoDB数据库
目录 1. 插入文档 2. 查询文档 3. 更新文档 4. 删除文档 1. 插入文档 # -*- coding: UTF-8 -*- import datetime from pymongo im ...
随机推荐
- 移动 web 适配
一.移动 web 开发与适配 1.跑在手机端的 web 页面(H5 页面) 2.跨平台(PC 端.手机端 - 安卓.IOS) 3.基于 webview(终端开发技术的一个组件) 4.告别 IE 拥抱 ...
- 致C#,致我这工作一年(上)
回忆 最近比较闲,虽然我总是每天会在博客园逛上1~2个钟(最近是真的有点闲),看了很多人对于工作的感悟,谈程序员的职业规划,不知不觉出来工作我也快一年多了,我也想聊聊现在用C#找工作和我这一年多 ...
- appium:运行脚本时,报404的解决办法
对于报404的错,不要怀疑,在环境正常的情况下,一定是你的端口被占用了. 就用:查看端口:netstat -aon|findstr 5037 查看进程:tasklist /fi "PID e ...
- 数据结构与STL容器
1.静态数组 静态数组就是大小固定不能扩展的数组,如C中普通数组.C++11中array. 2.动态数组 动态数组的空间大小在需要的时候可以进行再分配,其代表为vector.由于数组的特点,在位置0插 ...
- mysql查询前一天的数据
curdate()表示当天日期 统计前一天的日志sql语句: day); 要求: 统计从昨天开始统计前7天的日志包括昨天 day) --------------------- date_sub( ...
- numpy 库简单使用
numpy 库简单使用 一.numpy库简介 Python标准库中提供了一个array类型,用于保存数组类型的数据,然而这个类型不支持多维数据,不适合数值运算.作为Python的第三方库numpy便有 ...
- VS Code 之 smarty 扩展
VS Code 中的 Smarty 扩展: https://github.com/imperez/vscode-smarty 目前(v0.2.0)不支持定制定界符.可以通过 trick 的方式篡改. ...
- 【ProtoBuffer】windows上安装ProtoBuffer3.1.0 (附已编译资源)
------- 17.9.17更新 --- 以下这些方法都是扯淡,对我的机器不适用,我后来花了最后成功安装并亲测可用的方法不是靠vs编过的,vs生成的库引入后函数全部报undefine refere ...
- springboot的拦截器Interceptor的性质
Interceptor在springboot2.x版本的快速入门 实现HandlerInterceptor的接口,并重载它的三个方法:preHandle.postHandle.afterComplet ...
- 长见识-python小知识
操作系统:桌面操作系统,服务器操作系统,嵌入式操作系统,移动设备操作系统. 作用:1直接控制计算机不同的硬件比如cpu,硬盘等进行工作. 2 把操作这些硬件的方法封装成一个又一个的系统调用, 供其他成 ...