HashMap在JDK1.7中可能出现的并发问题
在JDK1.7及以前中,如果在并发环境中使用HashMap保存数据,有可能会产生死循环的问题,造成cpu的使用率飙升。之所以会发生该问题,实际上就是因为HashMap中的扩容问题。
HashMap的实现实际上是一个数组+链表的实现(JDK1.8中当链表长度达到一定值会转化为红黑树),当HashMap中保存的值超过阈值时将会进行一次扩容操作,并发环境下可能存在一个线程发现HashMap容量不够需要扩容,而在这个过程中,另外一个线程也刚好进行扩容操作,这时就有可能造成死循环的问题。扩容操作一般是在调用put(...)方法时进行的,put时会对容量进行检查。如果在扩容是链表中产生一个环形链表,那么在使用get(...)获取数据时将可能产生死循环。
//进行扩容时调用的方法
void resize(int newCapacity) {
Entry[] oldTable = table;//保存旧的数组
int oldCapacity = oldTable.length;//保存旧的容量
if (oldCapacity == MAXIMUM_CAPACITY) {//无法再进行扩容
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
//将原数组中的元素迁移到扩容后的数组中
//死循环就是在这个方法中产生的
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
在并发环境中,多个线程并不是一起执行的,而是由cpu来调度,任何线程在任意时刻都有可能停下来,当线程停下来时状态实际上被保存在栈帧中,下一次被cpu分配到执行权时从读取当前状态开始继续执行,对于被cpu挂起的线程在挂起这段时间相当于是"时间暂停"了。明白了这些接下来我们模拟死循环出现的情况,实际上这种情况是很不容易出现的,因为需要的条件较多,但是如果我们线上环境执行频率很高的话产生这种情况就显得比较容易了,一旦产生一次那就是灾难,除了修改代码重启服务器基本没别的解决方法。
假设当前HashMap中数组长度为1,并且只保存了两个值(设置的值都是为了产生死循环),如下图,改图表示一个长度为1的数组,保存值为1和3的两个值:
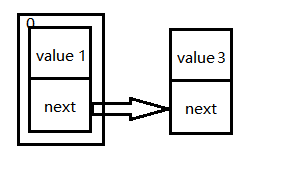
现在假设两个线程都在进行扩容操作,线程1刚开始,当走到Entry<K,V> next = e.next;时线程挂起,cpu被分配给线程2。
线程2在cpu分配的执行时间中对HashMap操作后变成下图所示。扩容后,数组长度变为2,由于扩容是重新插入(头插法)的原因,值得顺序变了,现在value=3持有value=1的引用。此时线程2挂起,cpu切换到线程1。之前保存的状态中e的值为value=1的entry且e包含value=3的值得引用。
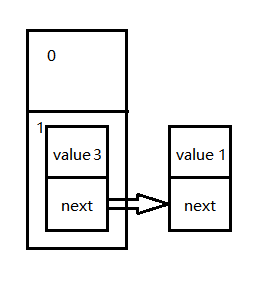
线程1继续之前的操作:
e.next = newTable[i];
newTable[i] = e;
e = next;
经过两次循环后:
看起来和正常的没有什么区别,理论上来说,正常情况下由于value=3的entry的next为null此时应该跳出循环,但是问题在于之前的线程2使得value=3持有value=1的引用,这时还会在进行一次循环:
//此时e = value(1)
Entry<K,V> next = e.next; //next=null
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //e.next=value(3) 死循环了
newTable[i] = e;
e = next;
由上可知此时value(3).next=value(1) 并且value(1).next=value(3),产生了环形链表。
如果之后调用get(...)方法,能找到还好,如果查找的值不存在,那么get方法会在环形链表处一直循环无法退出,只能重启服务器了...
HashMap在JDK1.7中可能出现的并发问题的更多相关文章
- HashMap在JDK1.8中并发操作,代码测试以及源码分析
HashMap在JDK1.8中并发操作不会出现死循环,只会出现缺数据.测试如下: package JDKSource; import java.util.HashMap; import java.ut ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进(转)
一.简单回顾ConcurrentHashMap在jdk1.7中的设计 先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示: 每一个segment都是一个HashE ...
- Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进
一.简单回顾ConcurrentHashMap在jdk1.7中的设计 先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示: 每一个segment都是一个HashE ...
- Jdk1.8中的HashMap实现原理
HashMap概述 HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变. HashM ...
- 【不做标题党,只做纯干货】HashMap在jdk1.7和1.8中的实现
同步首发:http://www.yuanrengu.com/index.php/20181106.html Java集合类的源码是深入学习Java非常好的素材,源码里很多优雅的写法和思路,会让人叹为 ...
- 【1】Jdk1.8中的HashMap实现原理
HashMap概述 HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变. 内部实现 ...
- JDK1.7中HashMap死环问题及JDK1.8中对HashMap的优化源码详解
一.JDK1.7中HashMap扩容死锁问题 我们首先来看一下JDK1.7中put方法的源码 我们打开addEntry方法如下,它会判断数组当前容量是否已经超过的阈值,例如假设当前的数组容量是16,加 ...
- JDK1.7 中的HashMap源码分析
一.源码地址: 源码地址:http://docs.oracle.com/javase/7/docs/api/ 二.数据结构 JDK1.7中采用数组+链表的形式,HashMap是一个Entry<K ...
随机推荐
- java中的值传递和引用传递有什么区别呀?
值传递: (形式参数类型是基本数据类型和String):方法调用时,实际参数把它的值传递给对应的形式参数,形式参数只是用实际参数的值初始化自己的存储单元内容,是两个不同的存储单元,所以方法执行中形式参 ...
- ConcurrentDictionary
ConcurrentDictionary ConcurrentDictionary一大特点是线程安全,在没有ConcurrentDictionary前 在多线程下用Dictionary,不管读写都要加 ...
- 计算机爱好者协会技术贴markdown第一期
本周爱酱给大家带来的是markdown的介绍和使用哦~ Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式.由于是纯文本,所以可移植性特 ...
- Linux二进制分析PDF
链接:https://pan.baidu.com/s/1lp5mz30J3RamFyQIXRvx5w 提取码:vcdq 我就是看不惯csdn的付费下载,链接失效了就评论区留言,我能收到邮件.
- 通过HttpClient发起Get请求,获取Json数据,然后转为java数据,然后批量保存数据库;
Json转java所需Jar包: commons-beanutils-1.8.0.jar,commons-collections-3.2.1.jar,commons-lang-2.5.jar,comm ...
- Windows多线程学习随笔
自学Windows多线程知识,例程如下: #include <iostream> #include <windows.h> #include <process.h> ...
- 【慕课网实战】七、以慕课网日志分析为例 进入大数据 Spark SQL 的世界
用户: 方便快速从不同的数据源(json.parquet.rdbms),经过混合处理(json join parquet), 再将处理结果以特定的格式(json.parquet)写回到 ...
- 20155205 郝博雅 Exp6 信息搜集与漏洞扫描
20155205 郝博雅 Exp6 信息搜集与漏洞扫描 一.实践内容 (1)各种搜索技巧的应用 (2)DNS IP注册信息的查询 (3)基本的扫描技术:主机发现.端口扫描.OS及服务版本探测.具体服务 ...
- 20145232韩文浩 《网络对抗技术》 Web基础
Apache 因为端口号80已经被占用(上次实验设置的),所以先修改/etc/apache2/ports.conf里的端口为5232后重新开启 可以在浏览器中输入localhost:5208来检查是否 ...
- JS入门经典第二章总结
document:在对网页编写脚本时,我们使用document对象代表网页.要引用一个属性,只需在document对象后加一个“.”号,然后再加上要引用的属性名. alert():该函数弹出一个消息框 ...