写一个ORM框架的第一步(Apache Commons DbUtils)
新一次的内部提升开始了,如果您想写一个框架从Apache Commons DbUtils开始学习是一种不错的选择,我们先学习应用这个小“框架”再把源代码理解,然后写一个属于自己的ORM框架不是梦。
一、简介
DbUtils是Apache下commons工具集中的一个小工具,它主要是对JDBC封装的ORM小工具,简化了JDBC的操作。之所以把它称之为工具而不是框架,是因为它和其他的ORM框架还是由很大的区别(例如Hibernate)。DbUtils并不支持所谓的聚合关联映射、缓存机制、实体状态的管理、延迟加载技术等等,它纯粹只是对JDBC的API进行封装。但也由于它的这种简单,因此性能高也是它的特点。DbUtils的源代码并不多,也很容易读得懂,非常适合于初学者阅读和学习。
二、ORM概要
对象关系映射(Object Relational Mapping),简称ORM。网上有很多专业的解释,但对于初学者来说这些专业的术语也许不太好理解。所以我们还是通过一些实际例子来说明。
在日常的开发中我们经常用到实体或者DTO对象,这似乎对每一个程序员来说都是再熟悉不过的了。但这些所谓的实体或者DTO对象按照领域驱动设计的说法,它们只有自己的属性,却没有属于自己的业务行为(get和set那不叫业务行为)。因此我们把他们称之为贫血模型。那用这些贫血模型来做什么呢?没错,就是封装数据。我们经常会将一些不同类型的数据封装到这些对象中。
Users user = new Users();
user.setUserName(“张三”);
user.setAge(20);
给对象属性赋完值以后,便把这个实体传递给Dao层执行保存操作。最终将数据持久化到数据库的某张表中。
public int persist(Users user) {
String sql = “INSERT INTO USERS_INFO(U_NAME, U_AGE) VALUES(?,?)”;
Connection conn = null;
PreparedStatment ps = null;
int row = 0;
try {
conn = ConnUtil.getConnection();
ps = conn.preparedStatment(sql);
ps.setString(1, user.getUserName);
ps.setInt(2, user.getAge());
row = ps.executeUpdate();
} catch(SQLException e){
e.printStackTrace();
} finally {
ConnUtil.close(null, ps, conn);
}
return row;
}
在这个过程我们发现一点,数据在Java中是以对象的形式存储,而最终持久化到数据库的时候是以关系型表格的形式存储,也就是说,我们把一个对象化结构的数据映射到了关系型数据库中的这个过程,就是对象关系映射。反之,当我们从关系型数据库中查询出的数据,又转换成一个对象模型的数据结构,这也是对象关系映射。
public Users findUserById(int id) {
String sql = “SELECT * FROM USERS_INFO WHERE U_ID = ?”;
Connection conn = null;
PreparedStatment ps = null;
ResultSet rs = null;
Users user = null;
try {
conn = ConnUtil.getConnection();
ps = conn.preparedStatment(sql);
ps.setString(1, id);
rs = ps.executeQuery();
if(rs.next()) {
user = new Users();
user.setId(rs.getInt(1));
user.setUserName(rs.getString(2));
user.setAge(rs.getInt(3));
}
} catch(SQLException e){
e.printStackTrace();
} finally {
ConnUtil.close(rs, ps, conn);
}
return user;
}
因此,我们可以将对象关系映射理解为它是一种对象模型和关系型数据库之间相互转换的过程。在实际开发中,我们会遇到大量的ORM操作,然而你会发现,这种操作其实大部分都是重复劳动,频繁的给PreparedStatment设置参数,又或者是频繁的从ResultSet中读取数据保存到实体中,这些操作让我们在开发中降低了效率。我们能否将这些繁琐的操作封装起来,我给你一个实体,你会自动帮我保存到数据库。我告诉你一个对象的类型,你会自动将结果集中的数据封装到这个对象中返回给我。这样就大大简化的JDBC的操作,提高了开发效率。接下来我们所学习的DbUtils就帮我们完成了这些事情。
三、下载与安装
下载:
http://commons.apache.org/proper/commons-dbutils/download_dbutils.cgi
安装:
教程中使用的是1.6的版本,下载的压缩包是 commons-dbutils-1.6-bin.zip。解压后将commons-dbutils-1.6.jar导入工程即可。
四、DML操作
首先,我们在数据中创建USERS_INFO表。(mysql数据库)
CREATE TABLE USERS_INFO (
ID INT PRIMARY KEY AUTO_INCREMENT, -- 主键
U_NAME VARCHAR(50) NOT NULL, --姓名
U_AGE INT NOT NULL --年龄
) CHARSET=UTF8
这里我们使用DBCP连接池作为数据源。DBCP也是commons工具集中一个小工具。简单点说,它主要用于监听和管理JDBC的Connection对象,达到连接复用的效果(连接池的原理及好处可以在JDBC教程的章节中进行查阅)。
DBCP连接池需要的jar文件:
- commons-dbcp2-2.1.1-bin.zip
下载地址: http://commons.apache.org/proper/commons-dbcp/download_dbcp.cgi
- commons-pool2-2.4.2-bin.zip
下载地址: http://commons.apache.org/proper/commons-pool/download_pool.cgi
- commons-logging-1.2-bin.zip
下载地址: http://commons.apache.org/proper/commons-logging/download_logging.cgi
解压后将commons-dbcp2-2.1.1.jar、commons-pool2-2.4.2.jar、commons-logging-1.2.jar这三个jar文件导入工程。
接下来编写一个DBCP连接池的工具类,用于获取DataSource
public class DBCPUtil {
private static Properties prop = new Properties();
private static DataSource dataSource;
/**
* 初始化连接池
*/
static {
//驱动
prop.setProperty("driverClassName", "com.mysql.jdbc.Driver");
//连接url
prop.setProperty("url", "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8");
//用户名
prop.setProperty("username", "root");
//密码
prop.setProperty("password", "root");
//初始连接数
prop.setProperty("initialSize", "5");
//最大活动连接数
prop.setProperty("maxTotal", "20");
//最小空闲连接
prop.setProperty("minIdle", "5");
//最大空闲连接
prop.setProperty("maxIdle", "10");
//等待连接的最大超时时间(单位:毫秒)
prop.setProperty("maxWaitMillis", "1000");
//连接未使用时是否回收
prop.setProperty("removeAbandonedOnMaintenance", "true");
prop.setProperty("removeAbandonedOnBorrow", "true");
try {
dataSource = BasicDataSourceFactory.createDataSource(prop);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取DataSource
* @return
*/
public static DataSource getDataSource(){
return dataSource;
}
}
4.1、QueryRunner类
这个类用于发送执行SQL语句并返回相应的结果。其实现当中对Connection以及PreparedStatment接口的API进行了封装。QueryRunner有两种方式来管理连接,一种是在构建QueryRunner实例时通过构造方法传递一个数据源DataSource实例;另一种则是在调用相应的操作方法,如query、update、batch等这些方法时传入一个Connection对象。这两种方式有什么区别呢?通过源码的阅读,我们不难发现,其实对于DataSource的管理,在每次执行完相应操作后,DbUtils会自动关闭数据源的连接对象。而在调用相应的操作方法时传入的Connection对象,在使用完之后是需要我们手动去关闭这个资源的。在以下所有的例子中,我们都将使用DataSouce的方式进行操作。
4.2、Insert操作
/**
* 添加操作
* @param userName 姓名
* @param age 年龄
* @return int 影响的行数
* @throws SQLException
*/
public int persist(String userName, int age) throws SQLException{
String sql = "INSERT INTO USERS_INFO(U_NAME,U_AGE) VALUES(?,?)";
//创建Query执行器,通过构造方法传入一个DataSource对象
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource());
// 执行update方法,方法的第一个和第二个参数分别是Connection对象和要执行的sql语句
// 第三个参数开始是一个可变参数,分别是sql语句中所需的参数,对应上面语句中问号的顺序
// 执行完成后会返回影响的行数
return qr.update(sql, userName, age);
}
4.3、Update操作
/** * 更新操作,用的是同样的方法,仅是sql语句的不同
* @param userName 姓名
* @param age 年龄
* @param id 主键
* @return int 影响的行数
* @throws SQLException
*/ public int update(String userName, int age, int id) throws SQLException{
String sql = "UPDATE USERS_INFO SET U_NAME = ?, U_AGE = ? WHERE ID = ?";
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource());
return qr.update(sql, userName, age, id);
}
4.4、Delete操作
/**
* 删除操作,用的是同样的update方法,仅是sql语句的不同
* @param userName 姓名
* @param id 主键
* @return int 影响的行数
* @throws SQLException
*/ public int delete(int id) throws SQLException{
String sql = "DELETE FROM USERS_INFO WHERE ID = ?";
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource());
return qr.update(sql, id);
}
4.5、批量操作
/**
* 批量操作
* @param params 批量执行SQL所需的参数,必须是一个二维数组
* @return int[] 影响的行数
* @throws SQLException
*/ public int[] betch(Object[][] params) throws SQLException{
String sql = "INSERT INTO USERS_INFO(U_NAME,U_AGE) VALUES(?,?)";
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource());
//使用batch方法,第三个参数是一个二维数组,数组中的每个元素对应每次sql执行所需的参数
//返回影响的行数的是一个int类型的数组
return qr.batch(sql, params);
}
五、DQL操作
5.1、ResultSetHandler接口
这个接口的核心作用是将查询结果进行封装(O/R Mapping)。它有许多不同的实现类,每一个实现类都将ResultSet中的结果封装成不同类型的数据对象。如下图:
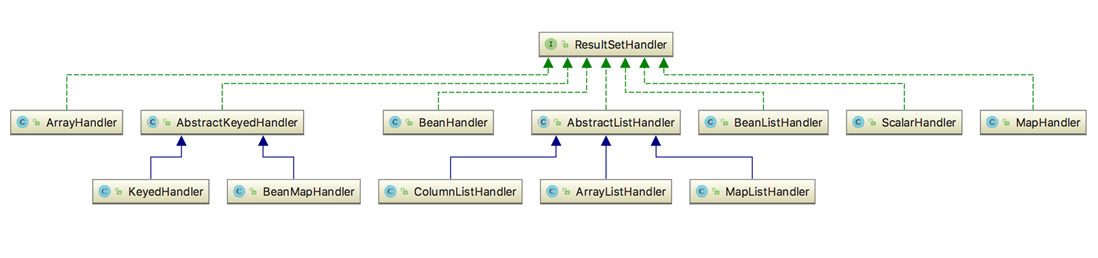
在ResultSetHandler众多的处理器实现类中主要分为两类,一类是处理单条结果集的,一类是处理多条结果集的。
单条数据处理器:BeanHandler、ArrayHandler、MapHandler、ScalarHandler
多条数据处理器:AbstractKeyedHandler(KeyedHandler、BeanMapHandler)、AbstractListHandler(ColumnListHandler、ArrayListHandler、MapListHandler)
5.1、BeanHandler
将单条查询结果封装为Bean对象
/**
* Users实体
*/ public class Users { private String userName;
private int age;
public String getUserName() {
return userName;
} public void setUserName(String userName) {
this.userName = userName;
} public int getAge() {
return age;
} public void setAge(int age) {
this.age = age;
}
}
使用BeanHandler查询单条记录:
/**
* 使用BeanHandler查询单条记录
* @param id 主键
* @return Users
*/ public Users findUserById(int uid) throws SQLException{
//当表的列名和实体的属性名不一致时,在sql中使用as关键字给当前列指定别名,
//别名和实体的属性名对应即可
String sql = "SELECT U.U_NAME AS userName, U.U_AGE AS age FROM USERS_INFO U WHERE U.ID = ?"; //创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用BeanHandler类,泛型参数指定实体名称。构造方法指定实体的Class对象
BeanHandler<Users> handler = new BeanHandler<>(Users.class); //调用query方法执行查询,该方法的参数一和参数二为连接对象和sql语句,
//参数三为ResultSetHandler接口的实现类对象,这里是BeanHandler,
//方法的第四个参数为可变参数,是sql查询时所需的条件参数
//返回值则是一个封装好的实体对象
Users user = qr.query(sql, handler, uid); return user;
}
将多条查询结果封装为List集合,集合中的每个元素都是一个Bean对象
/**
* 使用BeanListHandler查询多条记录
* @return List<Users>
*/ public List<Users> findUsers() throws SQLException{
//当表的列名和实体的属性名不一致时,在sql中使用as关键字给当前列指定别名,
//别名和实体的属性名对应即可
String sql = "SELECT U.U_NAME AS userName, U.U_AGE AS age FROM USERS_INFO U"; //创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用BeanListHandler类
BeanListHandler<Users> handler = new BeanListHandler<>(Users.class); //同样调用query方法执行查询,返回值则是一个List对象,List的泛型参数为实体类型
List<Users> list = qr.query(sql, handler); return list;
}
5.3、ArrayHandler
将单条查询结果封装为一个Object数组
/**
* 使用ArrayHandler查询单条记录
* @param id 主键
* @return Object []
*/ public Object[] findUserById(int uid) throws SQLException{
String sql = "SELECT U.U_NAME, U.U_AGE FROM USERS_INFO U WHERE U.ID = ?";
//创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用ArrayHandler类,由于ArrayHandler将结果集封装为Object数组,因此这个handler是不需要指定泛型的
ArrayHandler handler = new ArrayHandler(); //调用query方法执行查询,返回值则是一个Object数组
Object[] objects = qr.query(sql, handler, uid); return objects; }
5.4、ArrayListHandler
将多条查询结果封装为List集合,集合中的每个元素都是一个Object数组
/**
* 使用ArrayListHandler查询多条记录
* @return List<Object[]>
*/
public List<Object[]> findUsers() throws SQLException{ String sql = "SELECT U.U_NAME, U.U_AGE FROM USERS_INFO U";
//创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用ArrayListHandler类
ArrayListHandler handler = new ArrayListHandler(); //同样调用query方法执行查询,返回值则是一个List对象,List的泛型参数为Object数组类型
List<Object[]> list = qr.query(sql, handler); return list;
}
5.5、MapHandler
将单条查询结果封装为一个Map对象, Key保存的是查询的列名,Value保存的是列的值
/**
* 使用MapHandler查询单条记录
* @param id 主键
* @return Map<String, Object>
*/ public Map<String, Object> findUserById(int id) throws SQLException{ //当表的列名和实体的属性名不一致时,在sql中使用as关键字给当前列指定别名,
//别名和实体的属性名对应即可
String sql = "SELECT U.U_NAME, U.U_AGE FROM USERS_INFO U WHERE U.ID = ?"; //创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用MapHandler类,由于返回的是一个Map,因此这个handler也是是不需要指定泛型的
MapHandler handler = new MapHandler(); //调用query方法执行查询,返回值则是Map对象
Map<String, Object> map = qr.query(sql, handler, uid); return map;
}
5.6、MapListHandler
将多条查询结果封装为一个List集合,集合中的每个元素都是一个Map对象
/** * 使用MapListHandler查询多条记录
* @return List<Map<String, Object>>
*/ public List<Map<String, Object>> findUsers() throws SQLException{ String sql = "SELECT U.U_NAME, U.U_AGE FROM USERS_INFO U"; //创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用MapListHandler类
MapListHandler handler = new MapListHandler(); //同样调用query方法执行查询,返回值则是一个List对象,List的泛型参数为Map类型
List<Map<String, Object>> list = qr.query(sql, handler); return list;
}
5.7、ScalarHandler
将单条查询结果中的某一列转换为指定的类型
/**
* 使用ScalarHandler查单条询记录中某一列
* @param id 主键
* @return String
*/ public String findUserNameById(int id) throws SQLException{ String sql = "SELECT U.U_NAME, U.U_AGE FROM USERS_INFO U WHERE U.ID = ?"; //创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用ScalarHandler类,泛型参数指定要返回的数据类型,构造方法指定查询结果中的某一列的下标
ScalarHandler<String> handler = new ScalarHandler<>(1); //调用query方法执行查询,返回值则是String类型
String userName = qr.query(sql, handler, id); return userName; }
5.8、ColumnListHandler
将多条查询结果中的某一列封装为List集合
/**
* 使用ColumnListHandler查单多询记录中某一列
* @return List<String>
*/ public List<String> findUserNames() throws SQLException{ String sql = "SELECT U.U_NAME, U.U_AGE FROM USERS_INFO U"; //创建QueryRunner实例 QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用ColumnListHandler类, 泛型参数指定要返回的数据类型,构造方法指定查询结果中的某一列的下标 ColumnListHandler<String> handler = new ColumnListHandler<>(1); //同样调用query方法执行查询,返回值则是一个List对象,List的泛型参数指定为查询结果转换的类型 List<String> list = qr.query(sql, handler); return list; }
5.9、KeyedHandler
将多条查询结果转换为Map,并将某列保存为Key,而Value则与MapHandler的查询结果一样,封装的是一个Map集合
/**
* 使用KeyedHandler查询结果转换为Map,并将某列的值保存为Key
* @return Map<Integer, Map<String, Object>>
*/ public Map<Integer, Map<String, Object>> findUsers() throws SQLException{
String sql = "SELECT * FROM USERS_INFO U";
//创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用KeyedHandler类,泛型参数指定key的类型,构造方法中的参数指定哪一列的值作为key保存
//构造方法的参数可以是查询结果中某列的下标,也可以是列的名称
//KeyedHandler<Integer> handler = new KeyedHandler<>("ID");
KeyedHandler<Integer> handler = new KeyedHandler<>(1);
//同样调用query方法执行查询,返回值则是一个Map集合,key为查询某列的值,value为封装当前行的Map对象
Map<Integer, Map<String, Object>> map = qr.query(sql, handler);
return map; }
5.10. BeanMapHandler
将多条查询结果转换为Map,并将某列保存为Key,而Value则与BeanHandler的查询结果一样,封装的是一个Bean对象
/**
* 使用MapBeanHandler查询结果转换为Map,并将某列的值保存为Key
* @return Map<Integer, Users>
*/ public Map<Integer, Users> findUsers() throws SQLException{ String sql = "SELECT U.ID, U.U_NAME AS userName, U.U_AGE AS age FROM USERS_INFO U";
//创建QueryRunner实例
QueryRunner qr = new QueryRunner(DBCPUtil.getDataSource()); //使用KeyedHandler类,泛型第一个参数指定key的类型,第二个参数指定查询结果转换的Bean类型,
//构造方法中的第一个参数指定Bean的Class对象,第二个参数指定将查询结果的哪一列的值作为key保存
//构造方法的参数可以是查询结果中某列的下标,也可以是列的名称
//BeanMapHandler<Integer, Users> handler = new BeanMapHandler<>(Users.class, "ID");
BeanMapHandler<Integer, Users> handler = new BeanMapHandler<>(Users.class, 1);
//同样调用query方法执行查询,返回值是一个Map集合,key为查询某列的值,value为封装当前行的Bean对象
Map<Integer, Users> map = qr.query(sql, handler);
return map;
}
六、作业
6.1、作业要求
1. 任意数据库,建立一个表student,字段有id,name(id是自增长的,name是char类型)
2. 利用DbUtils完成CRUD操作
3. insert操作要能得到返回的自增长值
4. Connection对象要能正确处理
6.2、提交内容
1. 整个项目的源代码打包发到我的qq或者直接把你的项目的git地址告诉我即可
6.3、提交时间
2017-11-2号 星期四 中午12:00前
七、资料下载与说明
7.1、参考
- https://coding.net/u/david_cj/p/dbutils-demo/git 陈军老师写的详细教程
- http://www.cnblogs.com/best/p/7474442.html Git的使用
- https://commons.apache.org/proper/commons-dbutils/ 官网
7.2、资料下载
链接:
https://pan.baidu.com/s/1mhK2d5Y 密码: d78g
7.3、说明
文章内容由“王亮”老师提供,内部学习时由“陈军”老师讲授
写一个ORM框架的第一步(Apache Commons DbUtils)的更多相关文章
- 写一个ORM框架的第一步
新一次的内部提升开始了,如果您想写一个框架从Apache Commons DbUtils开始学习是一种不错的选择,我们先学习应用这个小“框架”再把源代码理解,然后写一个属于自己的ORM框架不是梦. 一 ...
- 从 0 开始手写一个 Mybatis 框架,三步搞定!
阅读本文大概需要 3 分钟. MyBatis框架的核心功能其实不难,无非就是动态代理和jdbc的操作,难的是写出来可扩展,高内聚,低耦合的规范的代码. 本文完成的Mybatis功能比较简单,代码还有许 ...
- 手写开源ORM框架介绍
手写开源ORM框架介绍 简介 前段时间利用空闲时间,参照mybatis的基本思路手写了一个ORM框架.一直没有时间去补充相应的文档,现在正好抽时间去整理下.通过思路历程和代码注释,一方面重温下知识,另 ...
- 剖析手写Vue,你也可以手写一个MVVM框架
剖析手写Vue,你也可以手写一个MVVM框架# 邮箱:563995050@qq.com github: https://github.com/xiaoqiuxiong 作者:肖秋雄(eddy) 温馨提 ...
- 高性能jdbc封装工具 Apache Commons DbUtils 1.6(转载)
转载自原文地址:http://gao-xianglong.iteye.com/blog/2166444 前言 关于Apache的DbUtils中间件或许了解的人并不多,大部分开发人员在生成环境中更多的 ...
- Java连接数据库 #04# Apache Commons DbUtils
索引 通过一个简单的调用看整体结构 Examples 修改JAVA连接数据库#03#中的代码 DbUtils并非是什么ORM框架,只是对原始的JDBC进行了一些封装,以便我们少写一些重复代码.就“用” ...
- 《笔者带你剖析Apache Commons DbUtils 1.6》(转)
前言 关于Apache的DbUtils中间件或许了解的人并不多,大部分开发人员在生成环境中更 多的是依靠Hibernate.Ibatis.Spring JDBC.JPA等大厂提供的持久层技术解决方案, ...
- Apache Commons DbUtils 快速上手
原文出处:http://lavasoft.blog.51cto.com/62575/222771 Hibernate太复杂,iBatis不好用,JDBC代码太垃圾,DBUtils在简单与优美之间取得了 ...
- java JDBC (七) org.apache.commons.dbutils 查询
package cn.sasa.demo1; import java.sql.Connection; import java.sql.SQLException; import java.util.Li ...
随机推荐
- winform中TextBox只能输入字母
private void txtTestPerson_KeyPress(object sender, KeyPressEventArgs e) { if ((e.KeyChar >= 'a' & ...
- karaf 控制台 常用linux指令(2)
11,查看onos风格注解实例列表 -bash代码 scr:list ACTIVE代表实例已生成,REGISTERED代表实例未注入生成 12,查看组件列表,查看组件信息,查看组件提供的服务 -bas ...
- EF学习笔记(九):异步处理和存储过程
总目录:ASP.NET MVC5 及 EF6 学习笔记 - (目录整理) 上一篇:EF学习笔记(八):更新关联数据 本篇原文:Async and Stored Procedures 为何要采用异步? ...
- javaWeb中MVC的编程思想示例
没有学习MVC之前我只写了一个Servlet类(Note_List.java),分层之后,我将这个类分成了5个类(NoteDao.java,,NoteDaoImpl.java,,NoteService ...
- Oracle EBS数据定义移植工具:Xdf(XML Object Description File)
转载自:http://www.orapub.cn/posts/3296.html Oracle EBS二次开发中,往往会创建很多数据库对象,如表.同义词.视图等,这些数据库对象是二次开发配置管理内容很 ...
- 2017-12-04 编写Visual Studio Code插件初尝试
参考官方入门: Your First Visual Studio Code Extension - Hello World 源码在: program-in-chinese/vscode_helloWo ...
- 包建强的培训课程(13):iOS与ReactNative
@import url(http://i.cnblogs.com/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/c ...
- 【设计经验】3、ISE中烧录QSPI Flash以及配置mcs文件的加载速度与传输位宽
一.软件与硬件平台 软件平台: 操作系统:Windows 7 64-bit 开发套件:ISE14.7 硬件平台: FPGA型号:XC6SLX45-CSG324 QSPI Flash型号:W25Q128 ...
- 宝塔面板下安装zabbix
宝塔面板之前已经安装完成,如果不会可以查看上一个日志.接下来开始安装zabbix 1.添加系统用户和组 2. yum -y install epel-release #安装源 3.使用命令 yum - ...
- 第54节:Java当中的IO流(中)
Java当中的IO流(中) 删除目录 // 简书作者:达叔小生 import java.io.File; public class Demo{ public static void main(Stri ...