吴恩达Machine Learning 第一周课堂笔记
1.Introduction
1.1 Example
1.2 What is machine learning?
对机器学习的两种定义
1. Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programed.
2. Tom Mitchell(1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.(定义理解以spam为例:T表示对邮件进行分类,判断是否为垃圾邮件,E表示对邮件进行分类的结果,P表示对邮件分类的正确率。定义的意思是通过E,使得T更好,P就是这个指标,P增加)
1.3 Supervised Learning
1.3.1 Regression
Predict continuous valued output (price).预测一个连续值作为输出。比如知道房屋的面积,预测房价。
1.3.2 Classification
Discrete valued output(eg:0 or 1). 比如Breast cancer(malignant, benign)
1.4 Unsupervised Learning
给出一组数据,不给出相关数据的正确答案。找出这些数据内部存在的结构。无监督学习最为常见例子是聚类。根据事物间的相似度将它们归为一类。
2 Linear Regression with One Variable
2.1 Model and Cost Function
2.1.1 Model Representation
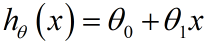 (2-1)
(2-1)
将要用到的符号说明:
x 表示输入(特征)
y 表示输出 (目标值)
m 表示训练集的样本数量
(x,y) 表示全部训练集数据
(x(i),y(i)) 表示训练集中第i个数据
h 表示假设函数,输入和输出之间的一种关系
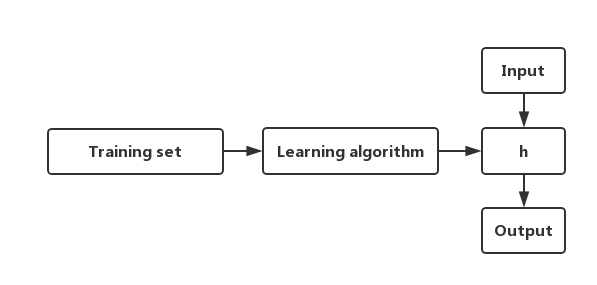
图 2.1 线性回归过程
学习算法利用训练集数据,拟合出假设函数h,输入经过假设函数拟合出输出。
2.1.2 Cost Function
代价函数是为了找到目的函数的最优解。因为在一个训练集中,有无数个模型,我们需要找到最拟合的这个训练集的函数,所以引入代价函数,用来找到那个最好的模型。常用的平方误差代价函数(或者是均方误差函数)如下式,其中1/2是为了求梯度下降方便,对代价函数求导会消掉1/2.
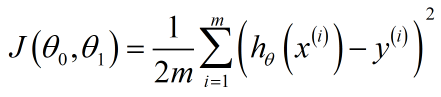 (2-2)
(2-2)
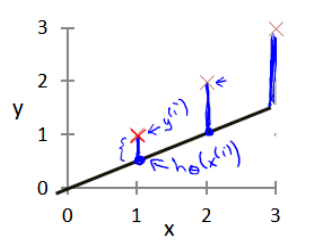
图2.2 建模误差
对于参数的选取,决定了模型的预测值与训练集中实际值的差距。(蓝线就是modeling error)。

图 2.3 代价函数图像
最优解即为代价函数的最小值,如图2.3所示,当θ1=1时,该代价函数有最小值,即最优解。
吴恩达Machine Learning 第一周课堂笔记的更多相关文章
- 吴恩达 Deep learning 第一周 深度学习概论
知识点 1. Relu(Rectified Liner Uints 整流线性单元)激活函数:max(0,z) 神经网络中常用ReLU激活函数,与机器学习课程里面提到的sigmoid激活函数相比有以下优 ...
- 吴恩达 Deep learning 第二周 神经网络基础
逻辑回归代价函数(损失函数)的几个求导特性 1.对于sigmoid函数 2.对于以下函数 3.线性回归与逻辑回归的神经网络图表示 利用Numpy向量化运算与for循环运算的显著差距 import nu ...
- 吴恩达Machine Learning学习笔记(一)
机器学习的定义 A computer program is said to learn from experience E with respect to some class of tasks T ...
- 吴恩达Machine Learning学习笔记(四)--BP神经网络
解决复杂非线性问题 BP神经网络 模型表示 theta->weights sigmoid->activation function input_layer->hidden_layer ...
- 吴恩达Machine Learning学习笔记(三)--逻辑回归+正则化
分类任务 原始方法:通过将线性回归的输出映射到0-1,设定阈值来实现分类任务 改进方法:原始方法的效果在实际应用中表现不好,因为分类任务通常不是线性函数,因此提出了逻辑回归 逻辑回归 假设表示--引入 ...
- 吴恩达Machine Learning学习笔记(二)--多变量线性回归
回归任务 多变量线性回归 公式 h为假设,theta为模型参数(代表了特征的权重),x为特征的值 参数更新 梯度下降算法 影响梯度下降算法的因素 (1)加速梯度下降:通过让每一个输入值大致在相同的范围 ...
- 《Structuring Machine Learning Projects》课堂笔记
Lesson 3 Structuring Machine Learning Projects 这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第三门课程的课程笔记. 参考了其他人的笔 ...
- cousera 吴恩达 深度学习 第一课 第二周 作业 过拟合的表现
上图是课上的编程作业运行10000次迭代后,输出每一百次迭代 训练准确度和测试准确度的走势图,可以看到在600代左右测试准确度为最大的,74%左右, 然后掉到70%左右,再掉到68%左右,然后升到70 ...
- 第一周课堂笔记3th
1.bool值 True正确 False错误 数字为0时的显示 为空值时“” 2. str int bool布尔值 之间的转化 str int ...
随机推荐
- jirba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- 新学了几个python模块,不是很鸡肋。
先说一个模块分类(基本上所有模块都是小写开头,虽然规范的写法是变量的命名规范,但是,都是这样写的) 1,C编写并镶嵌到python解释器中的内置模块 2,包好的一组模块的包 3.已经被编译好的共享库, ...
- LOJ 2551 「JSOI2018」列队——主席树+二分
题目:https://loj.ac/problem/2551 答案是排序后依次走到 K ~ K+r-l . 想维护一个区间排序后的结果,使得可以在上面二分.求和:二分可以知道贡献是正还是负. 于是想用 ...
- layui:数据表格如何合并单元格
layui.use('table', function () { var table = layui.table; table.render({ elem: '#applyTab' , url: '$ ...
- 如何删除Kafka的Topic
在server.properties文件中添加配置:delete.topic.enable=true 创建kafka主题: kafka-topics.sh --create --zookeeper 1 ...
- Nginx reverse proxy NSQAdmin
以下配置只针对nsqadmin v1.1.0 (built w/go1.10.3)版本 ## The default server# server { listen 80 defau ...
- TCP/IP各层对应的协议
应用层: 该层包括所有和应用程序协同工作,利用基础网络交换应用程序专用的数据协议.如: HTTP:超文本传输协议. TELNET:(网络电传),通过一个终端(terminal)登录到网络(运行在TCP ...
- MTSC2018 | 确认过眼神,在这里能遇见Google、阿里、百度......
MTSC2018部分Topic曝光啦 Google,阿里,百度,美团,小米,360,网易等公司是如何将技术转化为现实生产力,提高工作效率的?离开Saucelab的Jonathan又是如何规划Appiu ...
- 激活WINDOWS SERVER 2019
Windows Server 2019 Datacenter WMDGN-G9PQG-XVVXX-R3X43-63DFGWindows Server 2019 Standard N69G4-B89J2 ...
- 转载一份kaggle的特征工程:经纬度、特征构造、转化率
转载:https://www.toutiao.com/i6642477603657613831/ 1 如果训练/测试都来自同一时间线,那么就可以非常巧妙地使用特性.虽然这只是一个kaggle的案例,但 ...