Python爬虫(一) 信息系统集成及服务资质网
警告:不要恶意的访问网站,仅供学习使用!
本教程实例只抓取信息系统集成及服务资质网的企业资质查询。
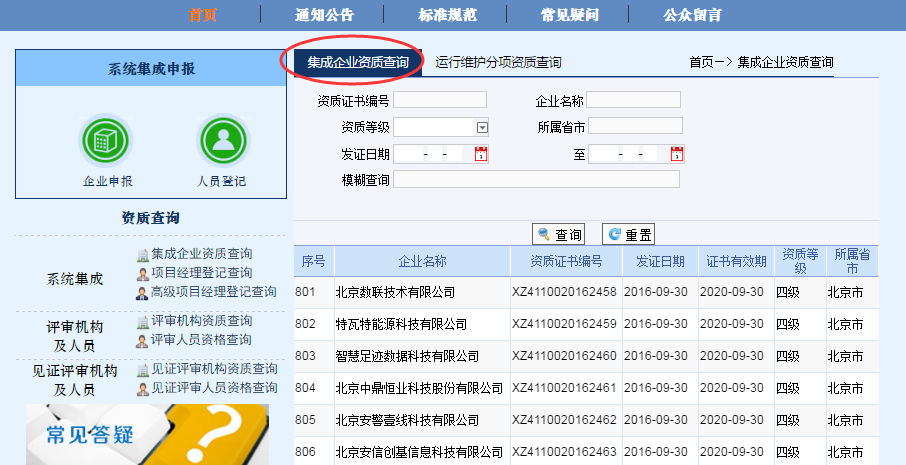
1. 抓包
打开谷歌浏览器的开发者工具并访问该网站,过滤请求后找到请求数据的包。
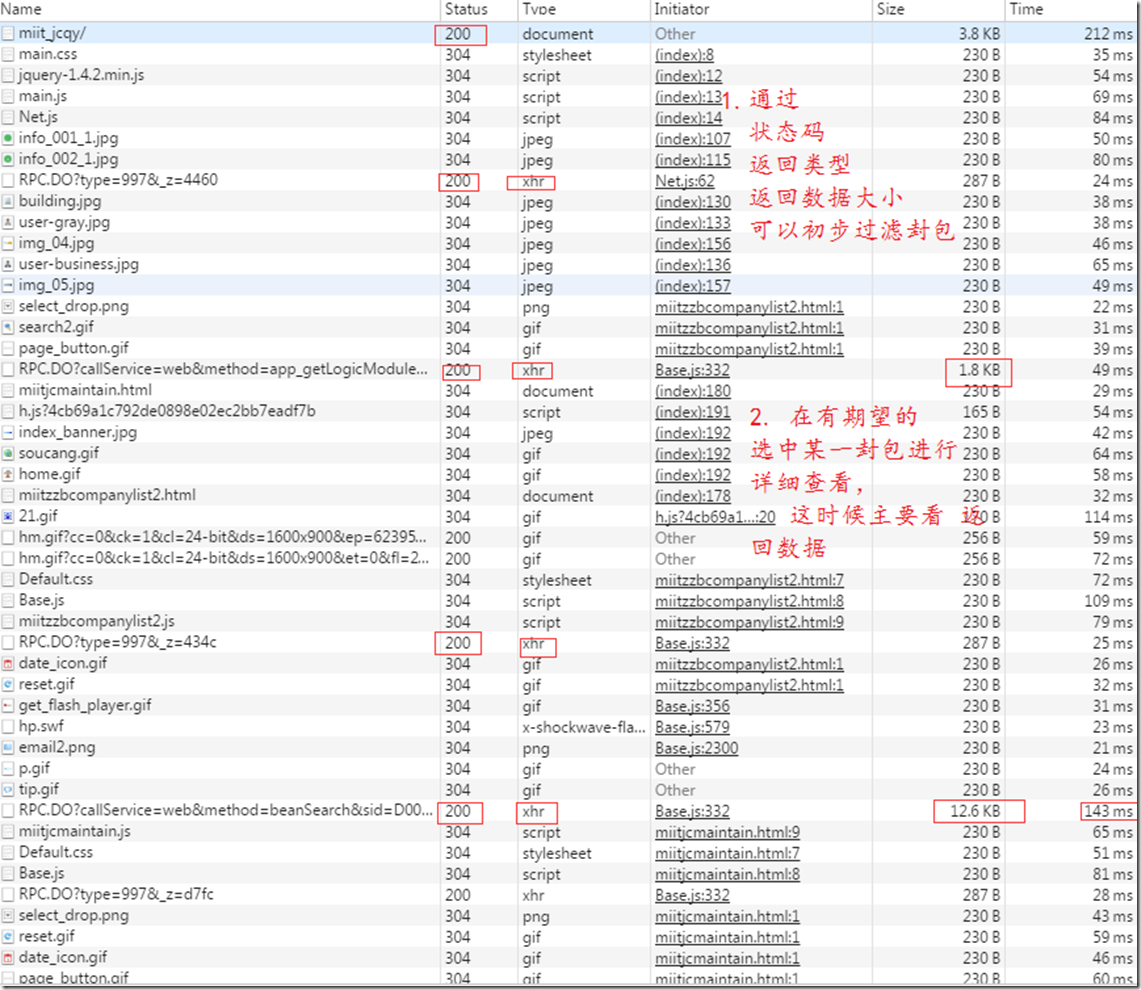
1.1 找到相应封包

1.2 分析(解析)参数a
参数a的值先base64解密,在进行2次url解密得到如下结果:
["{\"parameters\":[{\"name\":\"type\",\"value\":1,\"flag\":11,\"group\":null}],\"order\":\"approvaldate desc,qualificationlevel,createtime\",\"pageNum\":1,\"pageSize\":200,\"name\":\"miitzzbcompany\",\"getCodeValue\":true,\"codetypes\":[{\"name\":\"qualificationlevel\",\"code\":\"MIITTYPE\"}],\"isgis\":false,\"javaClass\":\"com.longrise.LEAP.BLL.Cache.SearchBuilder\"}"]
这里面可以看出是json格式的参数,而控制翻页的参数是pageNum,pageSize:200是代表请求的每页数据200条(网站默认200条/页);
因为字符\为转义字符,故在编程时候需要用\\来替代。
1.2 分析(解析)返回结果
分析结果一般是为了进行处理,存储数据做准备的;
不过现在的这个返回结果的内容过于丰富,除了必要的企业信息,竟然还有很全面的信息概况(提前知道页数、总条数等会变得主动);如下图:

我这里不进行处理存储了,只是进行测试访问。
2. python编程: urllib2, requests
这里只要构造一个post封包请求即可。
我用三种方法(工具)来进行测试;
2.1 urllib2
#-*- coding:utf-8 –*- 定义源代码的编码
#!/usr/bin/env python
'''
Created on 2016年10月15日
@author: baoluo
'''
import sys
import urllib
import urllib2
import cookielib
import base64
import time
import logging
#reload(sys)
#sys.setdefaultencoding("utf-8") #设置默认的string的编码格式
urllib2.socket.setdefaulttimeout(60) #全局:超时时间(s)
class Browser(object):
def __init__(self):
super(Browser, self).__init__()
sys.stdout.flush()
self.cookie = cookielib.CookieJar()
self.handler = urllib2.HTTPCookieProcessor(self.cookie)
self.opener = urllib2.build_opener(self.handler)
urllib2.install_opener(self.opener)
def addHeaders(self, name, value):
self.opener.addheaders.append((name, value))
def doGet(self, url):
req = urllib2.Request(url)
req = self.opener.open(req)
return req
def doPost(self, url, payload = None):
req = urllib2.Request(url, data = payload)
req = self.opener.open(req)
return req
class GetTable(object):
"""docstring for GetTable"""
def __init__(self):
super(GetTable, self).__init__()
self.browser = Browser()
def getParameter(self,page_index):
a = '["{\\"parameters\\":[{\\"name\\":\\"type\\",\\"value\\":1,\\"flag\\":11,\\"group\\":null}],\\"order\\":\\"approvaldate desc,qualificationlevel,createtime\\",\\"pageNum\\":' + str(page_index) + ',\\"pageSize\\":100,\\"name\\":\\"miitzzbcompany\\",\\"getCodeValue\\":true,\\"codetypes\\":[{\\"name\\":\\"qualificationlevel\\",\\"code\\":\\"MIITTYPE\\"}],\\"isgis\\":false,\\"javaClass\\":\\"com.longrise.LEAP.BLL.Cache.SearchBuilder\\"}"]'
encode1 = urllib.quote(a)
encode2 = urllib.quote(encode1)
encode3 = base64.urlsafe_b64encode(encode2)
return encode3
def main(self):
url_list2 = "http://www.csi-s.org.cn/LEAP/Service/RPC/RPC.DO?callService=web&method=beanSearch&sid=D00A7D61E08645F21A2E79CDF5B81B05.03&rup=http://www.csi-s.org.cn/&_website_=*"
self.browser.addHeaders("Cookie","JSESSIONID=D00A7D61E08645F21A2E79CDF5B81B05.03; Hm_lvt_4cb69a1c792de0898e02ec2bb7eadf7b=1476254714; Hm_lpvt_4cb69a1c792de0898e02ec2bb7eadf7b=1476372505")
self.browser.addHeaders('Host', 'www.csi-s.org.cn')
self.browser.addHeaders('Origin', 'http://www.csi-s.org.cn')
self.browser.addHeaders('Data-Type', '4')
self.browser.addHeaders('Post-Type', '1')
self.browser.addHeaders('Referer', 'http://www.csi-s.org.cn/LEAP/MIITModule/SystemBag/miitzzbcompanylist2.html')
self.browser.addHeaders('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
for page_index in range(1, 2):
post_data = "a=" + self.getParameter(3)
#print post_data
try:
req = self.browser.doPost(url_list2, post_data)
if 200 == req.getcode():
res = req.read()
print res
else:
print req.getcode()
except Exception, e:
print logging.exception(e)
finally:
time.sleep(3) #等待时间
if __name__ == '__main__':
GetTable().main()
2.2 requests
# -*- encoding: utf8 -*-
'''
Created on 2016年10月15日
@author: baoluo
'''
import requests
import time
import sys
import os
import urllib
import base64
import logging
import threading
reload(sys)
sys.setdefaultencoding( 'utf-8' )
class Grab_Data(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
super(Grab_Data, self).__init__()
sys.stdout.flush()
self.ses = requests.Session()
def doGet(self, url):
print '-get-header:',header
req = self.ses.get(url, headers=header, timeout=15)
return req
def doPost(self, url, payload):
print '-post-header:',header
req = self.ses.post(url, data=payload, headers=header, timeout=30)
return req
def getParameter(self,page_index):
a = '["{\\"parameters\\":[{\\"name\\":\\"type\\",\\"value\\":1,\\"flag\\":11,\\"group\\":null}],\\"order\\":\\"approvaldate desc,qualificationlevel,createtime\\",\\"pageNum\\":' + str(page_index) + ',\\"pageSize\\":100,\\"name\\":\\"miitzzbcompany\\",\\"getCodeValue\\":true,\\"codetypes\\":[{\\"name\\":\\"qualificationlevel\\",\\"code\\":\\"MIITTYPE\\"}],\\"isgis\\":false,\\"javaClass\\":\\"com.longrise.LEAP.BLL.Cache.SearchBuilder\\"}"]'
encode1 = urllib.quote(a)
encode2 = urllib.quote(encode1)
encode3 = base64.urlsafe_b64encode(encode2)
return encode3
def run(self):
header['Cookie']= "JSESSIONID=D00A7D61E08645F21A2E79CDF5B81B05.03; Hm_lvt_4cb69a1c792de0898e02ec2bb7eadf7b=1476254714; Hm_lpvt_4cb69a1c792de0898e02ec2bb7eadf7b=1476372505"
#header.setdefault('Host', 'www.csi-s.org.cn')
#header.setdefault('Origin', 'http://www.csi-s.org.cn')
header.setdefault('Data-Type', '4')
header.setdefault('Post-Type', '1')
header.setdefault('Referer', 'http://www.csi-s.org.cn/LEAP/MIITModule/SystemBag/miitzzbcompanylist2.html')
url_list2 = "http://www.csi-s.org.cn/LEAP/Service/RPC/RPC.DO?callService=web&method=beanSearch&sid=D00A7D61E08645F21A2E79CDF5B81B05.03&rup=http://www.csi-s.org.cn/&_website_=*"
try:
print "page=",page
data= "a="+ self.getParameter(page)
req = self.doPost(url_list2,data)
if 200==req.status_code:
print req.text
else:
print "HttpError:",req.status_code
except Exception, e:
print "Error" ,sys.exc_info()
if __name__ == '__main__':
header = {'User-Agent':'Mozilla/5.0 (Windows NT 5.1; rv:28.0) Gecko/20100101 Firefox/28.0'}
try:
for page in xrange(5,6):
t = Grab_Data()
t.start()
t.join()
#break
time.sleep(3) #等待时间
except Exception, e:
print logging.exception(e)
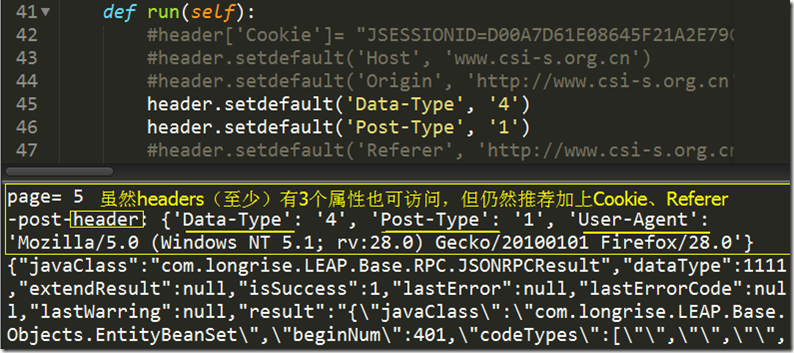
3. python编程: Selenium + openpyxl
#-*- encoding:utf-8 –*-
#!/usr/bin/env python
'''
Created on 2016年10月16日
@author: baoluo
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from openpyxl import Workbook
from openpyxl import load_workbook
from time import sleep,time
from datetime import datetime
import random
import json
import sys,os
import logging
from re import findall
reload(sys)
sys.setdefaultencoding("utf-8")
def now_time():
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
class GrabDate(object):
"""docstring for GrabDate"""
def __init__(self):
super(GrabDate, self).__init__()
self.browser = webdriver.Chrome()
self.browser.set_window_size(1024,777)
self.browser.implicitly_wait(10) #设置隐式等待时间
def find_element(self, by=By.XPATH, value=None):
try: self.browser.find_element(by=by, value=value)
except NoSuchElementException, e: return False
return True
def parser(self):
try:
if '信息系统集成及服务资质网' in self.browser.title:
#切换到iframe表单(内嵌页面) iframe(id='famebody')
self.browser.switch_to.frame('famebody')
#获取总页数,条数: 1/45页 1/8953条 200条/页
table_page_info = self.browser.find_element_by_xpath(".//*[@id='childbody']/div[2]/div/font").text
print 'table_page_info: ',table_page_info
if '正在查询' in table_page_info:
return
pageNum = findall(r'\d+/(\d+)页',str(table_page_info))
print "pageNum: ", pageNum
#pageNum = 2
ep = int(pageNum[0]) #尾页:ep,默认尾页是最大页数
sp = 22 #开始页:sp
#设置开始页、尾页(适用于中途断网,或者有选择的爬)
if sp != 1:
#输入起始页,点击 跳转
self.browser.find_element_by_xpath(".//*[@id='childbody']/div[2]/div/input[5]").clear()#清空
self.browser.find_element_by_xpath(".//*[@id='childbody']/div[2]/div/input[5]").send_keys(str(sp))
self.browser.find_element_by_xpath(".//*[@id='childbody']/div[2]/div/input[6]").click()
for page in xrange(sp, ep+1):
print str(page)+'/'+str(ep) + "page Time: ",now_time()
#切换到iframe表单(内嵌页面) iframe(id='famebody')
if self.find_element(by=By.ID, value="famebody"):
self.browser.switch_to.frame('famebody')
#查找表格是否加载进来
if self.find_element(value=".//*[@id='childbody']/div[1]/table/tbody"):
#获取当页 数据的条数
table_tbody_tr = self.browser.find_elements_by_xpath(".//*[@id='childbody']/div[1]/table/tbody/tr")
print 'list lengh:',len(table_tbody_tr)
trs = ['']*7
for tr in xrange(1,len(table_tbody_tr)+1):
for td in xrange(1,7+1):
xpath = ".//*[@id='childbody']/div[1]/table/tbody/tr["+str(tr)+"]/td["+str(td)+"]"
trs[td-1] = self.browser.find_element_by_xpath(xpath).text
#print trs
#一行写一次
self.writeLine_xlsx(trs)
# 下一页
self.browser.find_element_by_xpath(".//*[@id='childbody']/div[2]/div/input[3]").click()
#等待页面加载....
sleep(3)
else:
print 'net error'
except Exception, e:
print logging.exception(e)
finally:
print '---end---'
#self.browser.quit
def writeLine_xlsx(self, _list):
fname = u"集成企业资质查询.xlsx"
init = ('序号','企业名称', '资质证书编号','发证日期','证书有效期','资质等级','所属省市')
#文件不存在则创建
if not os.path.isfile('./'+fname):
wb = Workbook()
ws = wb.active
ws.freeze_panes = ws["A2"]
for i in xrange(len(init)):
ws.cell(row=1, column=(i+1), value= init[i])
wb.save(fname)
wrf = load_workbook(filename = fname)
wr = wrf.worksheets[0]
#查看当前行数
rows_len = len(wr.rows)+1
for col in xrange(7):
wr.cell(row=rows_len, column=(col+1), value= str(_list[col]))
wrf.save(fname)
def grab(self):
url = 'http://www.csi-s.org.cn/miit_webmap/miit_jcqy/'
self.browser.get(url)
sleep(5)
self.parser() #解析网站
if __name__ == '__main__':
GrabDate().grab()
我只测试了23页,效率低的很意外。。。
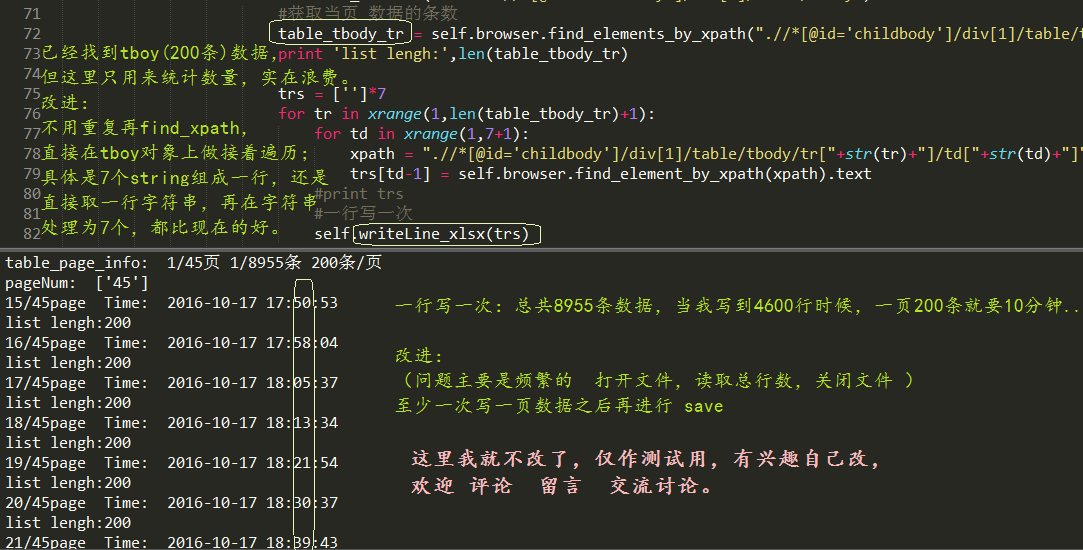
分析了慢的原因主要有2个:解析200条数据和一次写一行。
就这个程序生成的带4600条数据(7列)的文档,我只测试两种情况:
(一行/条数据指的是 1-7 组成的7列)
a)一次写一条数据,这样平均写一条数据就要2.8秒左右(估计大部分时间都花在文件的开闭了)
from openpyxl import Workbook
from openpyxl import load_workbook
from time import time
t0 = time()
print t0
for x in xrange(1,50):
print time()
fname = 't.xlsx'
wrf = load_workbook(filename = fname)
wr = wrf.worksheets[0]
rows_len = len(wr.rows)+1
for col in xrange(7):
wr.cell(row=rows_len, column=(col+1), value= str(col))
wrf.save(fname)
t1=time()
print t1
print t1-t0
b)一次写200条数据,这样只需要20秒左右。
from openpyxl import Workbook
from openpyxl import load_workbook
from time import time
t0 = time()
print t0
for x in xrange(1,2):
print time()
fname = 't.xlsx'
wrf = load_workbook(filename = fname)
wr = wrf.worksheets[0]
for x1 in xrange(200):
rows_len = len(wr.rows)+1
for col in xrange(7):
wr.cell(row=rows_len, column=(col+1), value= str(col))
wrf.save(fname)
t1=time()
print t1
print t1-t0
最后放结果:

参考:
Python爬虫(一) 信息系统集成及服务资质网的更多相关文章
- Python爬虫开发与项目实战pdf电子书|网盘链接带提取码直接提取|
Python爬虫开发与项目实战从基本的爬虫原理开始讲解,通过介绍Pthyon编程语言与HTML基础知识引领读者入门,之后根据当前风起云涌的云计算.大数据热潮,重点讲述了云计算的相关内容及其在爬虫中的应 ...
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- Python 爬虫 招聘信息并存入数据库
新学习了selenium,啪一下腾讯招聘 from lxml import etree from selenium import webdriver import pymysql def Geturl ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- Python爬虫库Scrapy入门1--爬取当当网商品数据
1.关于scrapy库的介绍,可以查看其官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/ 2.安装:pip install scrapy 注意这 ...
- python爬虫实战(二)--------千图网高清图
相关代码已经修改调试----2017-3-21 实现:千图网上高清图片的爬取 程序运行20小时,爬取大约162000张图片,一共49G,存入百度云.链接:http://pan.baidu.com/s/ ...
- Python爬虫入门教程 27-100 微医挂号网专家团队数据抓取pyspider
1. 微医挂号网专家团队数据----写在前面 今天尝试使用一个新的爬虫库进行数据的爬取,这个库叫做pyspider,国人开发的,当然支持一下. github地址: https://github.com ...
- Python爬虫入门教程 24-100 微医挂号网医生数据抓取
1. 写在前面 今天要抓取的一个网站叫做微医网站,地址为 https://www.guahao.com ,我们将通过python3爬虫抓取这个网址,然后数据存储到CSV里面,为后面的一些分析类的教程做 ...
- Python爬虫训练:爬取酷燃网视频数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 项目目标 爬取酷燃网视频数据 https://krcom.cn/ 环境 Py ...
随机推荐
- CSS :hover伪类选择定义和用法
伪类选择符E:hover的定义和用法: 设置元素在其鼠标悬停时的样式.E元素可以通过其他选择器进行选择,比如使用类选择符.id选择符.类型选择符等等.特别说明:IE6并非不支持此选择符,但能够支持a元 ...
- winform下自绘提示框风格窗体
昨天分享了一个环形滚动条控件,今天分享一个提示框风格的窗体.代码如下: /// <summary> /// 继承自Form,但将FormBorderStyle设置为None /// < ...
- 关于ImageMagick出现无效参数(invalid parameter)的解决方法
Windows 命令行 运行"convert logo.jpg f:\parseWord\tmp\logo.png" 时显示 “无效参数(Invalid Parameter)” ...
- 移动端自动化环境搭建-JDK的安装
一.安装jdk A.安装依赖 JDK作为JAVA开发的环境,不管是做JAVA开发的学生,还是做安卓开发的同学,都必须在电脑上安装JDK. B.安装过程 安装JDK 选择安装目录 安装过程中会出现两次 ...
- redis 问题解决(MISCONF Redis is configured to save RDB snapshots)
(error) MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on d ...
- 关于new/delete、malloc/free的内存泄漏检测
情况一 new/delete 内存泄漏 1.在MFC中可以每一个cpp文件的头部添加以下一段宏来检测new申请而没用free释放的内存泄漏 #ifdef _DEBUG #define new DEBU ...
- 【译】为什么这样宏定义#define INT_MIN (-2147483647 - 1)?
2的32次方为2147483648*2,0~(2147483648*2-1)这是32位机上无符号整数代表的范围.而32机的int范围为-2147483648~+2147483647 stackover ...
- TIJ读书笔记06-终结清理和垃圾回收
TIJ读书笔记06-终结清理和垃圾回收 finalize()方法 垃圾回收器如何工作 java的垃圾回收是由jvm来控制的.所以需要java程序员参与的部分不是很多. 但是在这里需要明白一点,java ...
- gitlab 配置
一.Gitlab的使用 具体步骤: 1.打开 Git Bash,输入~ssh -keygen 然后一直回车,直至出现图片上的内容 1) 2) 2.然后自动生成.ssh文件夹,双击文件夹 1) 2) ...
- CLR VIA C#事件
事件是类型的一个成员,用来在事情发生的时候通知注册了该事件的成员. 事件和观察者模式十分的相似,所以事件应该提供如下几种能力 1.能让对象的方法登记对他的关注 2.能让对象的方法取消对他的关注 3.能 ...