汇编学习:float与double速度问题
X86处理器包含两种类型的浮点数寄存器。第一种使用8个浮点寄存器组成浮点寄存器栈,另一种为向量寄存器(XMM,YMM),它们对于单双精度的处理是不同的。本文将讨论两种模式下的浮点数计算速度问题。
一、当我们编译32位程序时,使用的是x87指令集,即使用浮点寄存器堆栈进行浮点计算。此种情况下,单精度与双精度的处理是统一的,故计算速度上没有差异。我们可以做如下验证:
float a,b,c;
c=a*b;
汇编:
fld dword ptr [a] //将a加载到浮点栈顶,即ST(0)=a;
fmul dword ptr [b] //将栈顶元素与b相乘,结果仍存于栈顶,即ST(0)=ST(0)*b
fstp dword ptr [c] //将栈顶元素弹出并保存于c,即c=ST(0),POP();
double a,b,c;
c=a*b;
汇编:
fld qword ptr [a]
fmul qword ptr [b]
fstp qword ptr [c]
可以发现,上述两段代码的汇编代码完全相同.
因此,此种情况下,float与double的计算速度没有差异。在精度满足要求的情况下,可以使用float以便加载更多数据到cache,以提高cache命中率。
二、当编译64 位程序或打开MMX ,SSE,AVX指令集优化时,则使用向量寄存器。在此情况下,float与double的处理使用的是不同汇编指令,关于二者的计算速度,可以参考《Optimizing software in C++》中的一段话:
Single precision division, square root and mathematical functions are calculated faster than double precision when the XMM registers are used, while the speed of addition, subtraction, multiplication, etc. is still the same regardless of precision on most processors (when vector operations are not used).
意思是当使用XMM寄存器时,单精度浮点的除法、开根及一些数学函数的执行要比双精度快,但加法,减法、乘法的计算速度二者没有差异(在没有使用向量操作时)。
此处的向量操作指SIMD,即单指令多数据流。基本思想是将若干个数据加载到一个寄存器内部,一条指令可以同时处理多个数据,一个XMM(128位)可同时装载4个double或8个float,因此在使用SIMD时,一次处理的float数据量为double的两倍。
为了验证64位程序中的float和double的速度差异,下面给出测试程序:
float SqrtfloatV1(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=sqrt(A[i]);
}
return fSum;
} double SqrtdoubleV1(double *A,const int len)
{
double dSum=;
for(int i=;i<len;i++)
{
dSum+=sqrt(A[i]);
}
return dSum;
}
测试结果:
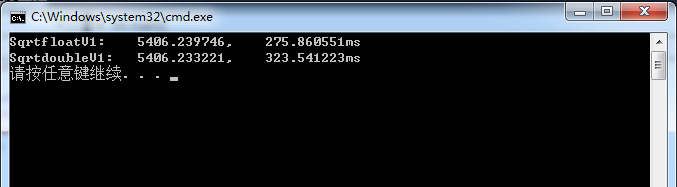
注意事项:
一、浮点数到整数(直接截断)的转换是很低效的,使用浮点堆栈(32位程序)时需要调用函数_ftol2_sse.
double a,b;
int c;
c=a*b;
汇编:
fld qword ptr [a]
fmul qword ptr [b]
call @ILT+(__ftol2_sse) (0EC10CDh) //调用函数_ftol2_sse实现浮点数到整数的转换
mov dword ptr [c],eax
使用XMM寄存器(64位程序)需要指令cvttsd2si:
double a,b;
int c;
c=a*b;
汇编:
movsd xmm0,mmword ptr [a]
mulsd xmm0,mmword ptr [b]
cvttsd2si eax,xmm0 //cvttsd2si指令实现
mov dword ptr [c],eax
下面是测试程序,对一个浮点数组求和:
float AddfloatV1(float *A,const int len)
{
int iSum=;
for (int i=;i<len;i++)
{
iSum+=A[i];//转成整数再求和
}
return (float)iSum;
} float AddfloatV2(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=A[i];
}
return fSum;
}
对于32位程序,测试结果如下:

于64位程序,测试结果如下:
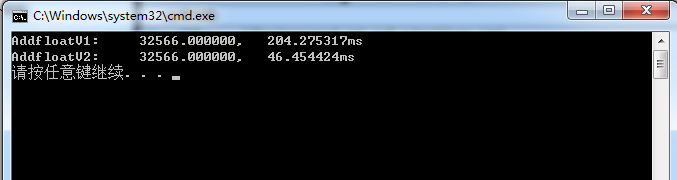
可以看出不管是32位还是64位程序,将浮点数转为整数再求和都会造成效率的大大降低。
关于浮点转整数的优化的讨论,可以参考一篇博文[1].
二、使用XMM寄存器(即当编译64位程序或打开SSE2指令集时),应避免float与double混用,因为编译器需要在计算过程中进行转换。如下:
(1)float与double混用(默认的浮点常量为double)
float a,b;
a=b*1.2;
汇编
movd xmm0,dword ptr [b]
cvtps2pd xmm0,xmm0
mulsd xmm0,mmword ptr [__real@3ff3333333333333 (13F646790h)]
cvtsd2ss xmm0,xmm0
movss dword ptr [a],xmm0
(2)纯float
float a,b;
a=b*1.2f;
汇编
movss xmm0,dword ptr [b]
mulss xmm0,dword ptr [__real@3f99999a (13F84678Ch)]
movss dword ptr [a],xmm0
可以看到,(1)中多了两个指令,即cvtps2pd,cvtsd2ss,它们分别实现float转double,double转float。
下面是一段测试程序:
float MulfloatV1(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=A[i]*1.2f;
}
return fSum;
} float MulfloatV2(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=A[i]*1.2;//默认的浮点常数是double
}
return fSum;
}
测试结果:
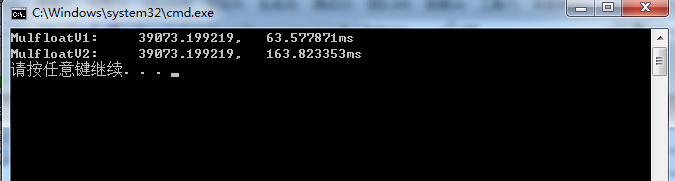
完整的测试程序:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#include <math.h>
#include "Timing.h"
const int BUFSIZE =;
float buf[BUFSIZE];
double buf2[BUFSIZE]; //测试64位下float与double的速度差
float SqrtfloatV1(float *A,const int len);
double SqrtdoubleV1(double *A,const int len); //测试浮点数转整数的速度
float AddfloatV1(float *A,const int len);
float AddfloatV2(float *A,const int len); //测试64位下float与double混用速度
float MulfloatV2(float *A,const int len);
float MulfloatV1(float *A,const int len); int main()
{
const int testloop=;
double interval;
srand( (unsigned)time( NULL ) );
for (int i = ; i < BUFSIZE; i++)
{ buf[i] = (float)(rand() & 0x3f);
buf2[i]= (double)(buf[i]);
}
//*****************************************************************//
//测试64位下float与double的速度差(32位无明显差异)
volatile float result1=;
startTiming();
for(unsigned int i=;i<testloop;i++)
{
result1=SqrtfloatV1(buf,BUFSIZE);
}
interval=stopTiming();
printf("SqrtfloatV1:\t%f,\t%lfms\n",result1,interval); volatile double result2=;
startTiming();
for(unsigned int i=;i<testloop;i++)
{
result2=SqrtdoubleV1(buf2,BUFSIZE);
}
interval=stopTiming();
printf("SqrtdoubleV1:\t%lf,\t%lfms\n",result2,interval);
//*****************************************************************// //*****************************************************************//
//测试浮点数转整数的速度(32为与64位均有明显差异)
volatile float result3=;
startTiming();
for(unsigned int i=;i<testloop;i++)
{
result3=AddfloatV1(buf,BUFSIZE);
}
interval=stopTiming();
printf("AddfloatV1:\t%f,\t%lfms\n",result3,interval); volatile float result4=;
startTiming();
for(unsigned int i=;i<testloop;i++)
{
result4=AddfloatV2(buf,BUFSIZE);
}
interval=stopTiming();
printf("AddfloatV2:\t%f,\t%lfms\n",result4,interval);
//*****************************************************************// //*****************************************************************//
//测试64位下float与double混用速度(32位无差异,因统一处理)
volatile float result5=;
startTiming();
for(unsigned int i=;i<testloop;i++)
{
result5=MulfloatV1(buf,BUFSIZE);
}
interval=stopTiming();
printf("MulfloatV1:\t%f,\t%lfms\n",result5,interval); volatile float result6=;
startTiming();
for(unsigned int i=;i<testloop;i++)
{
result6=MulfloatV2(buf,BUFSIZE);
}
interval=stopTiming();
printf("MulfloatV2:\t%f,\t%lfms\n",result6,interval);
//*****************************************************************//
return ;
} float SqrtfloatV1(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=sqrt(A[i]);
}
return fSum;
} double SqrtdoubleV1(double *A,const int len)
{
double dSum=;
for(int i=;i<len;i++)
{
dSum+=sqrt(A[i]);
}
return dSum;
} float AddfloatV1(float *A,const int len)
{
int iSum=;
for (int i=;i<len;i++)
{
iSum+=A[i];//转成整数再求和
}
return (float)iSum;
} float AddfloatV2(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=A[i];
}
return fSum;
} float MulfloatV1(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=A[i]*1.2f;
}
return fSum;
} float MulfloatV2(float *A,const int len)
{
float fSum=;
for (int i=;i<len;i++)
{
fSum+=A[i]*1.2;//默认的浮点常数是double
}
return fSum;
}
参考:
[1]http://blog.csdn.net/housisong/article/details/1616026
汇编学习:float与double速度问题的更多相关文章
- 从数据表字段 float 和 double 说起
今天在公司讨论项目重构的问题时,公司的 DBA 针对表中的字段大概介绍了一下 float 和 double 的存储方式.然后,我发现这个问题又回到了浮点数类型在内存中的存储方式,即 IEEE 对浮点数 ...
- 第48条:如果需要精确的答案,请避免使用float和double
float和double主要为了科学计算和工程计算而设计,执行二进制浮点运算,这是为了在广泛的数值范围上提供较为精确的快速近似计算而精心设计的.然而,它们没有提供完全精确的结果,所以不适合用于需要精确 ...
- 【转】JAVA程序中Float和Double精度丢失问题
原文网址:http://blog.sina.com.cn/s/blog_827d041701017ctm.html 问题提出:12.0f-11.9f=0.10000038,"减不尽" ...
- Effective Java 第三版——60. 需要精确的结果时避免使用float和double类型
Tips 书中的源代码地址:https://github.com/jbloch/effective-java-3e-source-code 注意,书中的有些代码里方法是基于Java 9 API中的,所 ...
- Sql的decimal、float、double类型的区别
三者的区别介绍 float:浮点型,含字节数为4,32bit,数值范围为-3.4E38~3.4E38(7个有效位) double:双精度实型,含字节数为8,64bit数值范围-1.7E308~1.7E ...
- float和double的精度
作者: jillzhang 联系方式:jillzhang@126.com 原网址:http://blog.csdn.net/wuna66320/article/details/1691734 1 范围 ...
- float和double精度问题
System.out.println(new BigDecimal(253.90).doubleValue() * 100);25390.0精度正确 System.out.println(new Bi ...
- float和double在内存中的存储方式
本文转载于:http://wenku.baidu.com/link?url=ARfMiXVHCwCZJcqfA1gfeVkMOj9RkLlR9fIexbgs9gDdV8rIS48A1_xe1y6YgX ...
- float、double的有效位数
Java中的浮点类型有两类,分别是float和double类型,其中float取_7__位有效数据,double取_15__位有效数据
随机推荐
- SVO实时全局光照优化(里程碑MK0):Sparse Voxel Octree based Global Illumination (SVO GI)
完全自主实现,bloat-free.再次声明,这不是UE.U3D.CE.KlayGE! 老规矩,先贴图.后面有时间再补充描述. 1. 支持多跳间接全局光照2. 支持vxao/so.vxdiff/spe ...
- 使用visualVM 1.3.8(visualvm_138-ml.zip) 监控远程Tomcat运行情况
服务端CentOS6.4 x64安装的是jdk1.7 下载visualVM1.3.8-ml 也就是多语言版本,包含中文,界面用起来方便.官方下载地址比较慢,百度上搜索的都是csdn,51cto等必须登 ...
- Jquery Data Table插件
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- 十进制转二进制and位运算符
先给大家送个福利! ---------------简单口算-------------------------- 10 >> 1010 除2取余倒写 /* 十进制转二进制规则是:除二取 ...
- 阿里大鱼.net core 发送短信
阿里大鱼还未提供 .net core 版SDK,但提供了相关API,下面是.net core版实现,只是简单发送短信功能: using System; using System.Collections ...
- Centos单网卡配置多个IP的方法
网上好多介绍一个网卡多个IP的方法,都有些问题,下面是实践可行的方法 DEVICE="eth0" TYPE="Ethernet" BOOTPROTO=none ...
- dubbo 2.5.4-SNAPSHOT dubbo-admin 报错
问题描述: RROR context.ContextLoader - Context initialization failed org.springframework.beans.factory.B ...
- iOS开发——高级技术精选&底层开发之越狱开发第二篇
底层开发之越狱开发第二篇 今天项目中要用到检查iPhone是否越狱的方法. Umeng统计的Mobclick.h里面已经包含了越狱检测的代码,可以直接使用 /*方法名: * isJailbroken ...
- redis的主从复制部署和使用
reids一种key-value的缓存数据库目前非常流行的被使用在很多场景,比如在数据库读写遇到瓶颈时缓存且读写分离会大大提升这块的性能,下面我就说说redis的主从复制 首先需要启动多个redis实 ...
- datagrid 动态列
var options={}; $(function(){ var myNj = 9; //初始化 $("#disgrid").datagrid({ type: 'POST', n ...