内存中OLTP(Hekaton)里的事务日志记录
在今天的文章里,我想详细讨论下内存中OLTP里的事务日志如何写入事务日志。我们都知道,对于你的内存优化表(Memory Optimized Tables),内存中OLTP提供你2个持久性(durability)选项:
- SCHEMA_ONLY
- SCHEMA_AND_DATA
今天我不想更多讨论SCHEMA_ONLY,因为使用这个选项,在事务日志里没有发生任何日志(SQL Server 重启后你的数据会丢失)。今天我们会专门讲解下SCHEMA_AND_DATA选项的持久性。
SCHEMA_AND_DATA
使用SCHEMA_AND_DATA持久性选项,SQL Server必须记录你的事务到事务日志,因为每个内存中OLTP事务必须总是持久的。这个和传统基于硬盘表是一样的。但是内存中OLTP里写入事务日志比传统表更优化。内存中OLTP支持多个并发日志流(在SQL Server 2014里当前未实现),内存中OLTP只记录发生的逻辑事务(logical transaction)。
逻辑事务是什么意思呢?假设你有5个非聚集索引定义的聚集表。如果你往表里插入1条记录,SQL Server必须记录插入到聚集索引,还有5个额外的插入非聚集索引。在你表上定义的非聚集索引越多,SQL Server需要的日志越多。而且SQL Server只能和事务日志一样快。
使用内存中OLTP事情就变了。内存中OLTP,SQL Server只记录在你事务里发生的逻辑修改。SQL Server对在你哈希或范围索引里的修改不记录。因此1条日志记录只描述发生的逻辑INSERT/UPDATE/DELETE语句。结果是,内存中OLTP写入更少的数据到你的事务日志,因此你的事务可以更快的提交。
我们来验证它!
我想用1个简单的例子向你展示下,当你首先插入10000条记录到传统基于硬盘表(Disk Based Table),然后插入内存优化表(Memory Optimized Table),SQL Server会有多少的数据写入你的事务日志。下列代码创建1个简单表,在while循环里插入10000条记录。然后我用sys.fn_dblog系统函数(未文档公开)来看事务日志。
-- Create a Disk Based table
CREATE TABLE TestTable_DiskBased
(
Col1 INT NOT NULL PRIMARY KEY,
Col2 VARCHAR(100) NOT NULL INDEX idx_Col2 NONCLUSTERED,
Col3 VARCHAR(100) NOT NULL
)
GO -- Insert 10000 records into the table
DECLARE @i INT = 0 BEGIN TRANSACTION
WHILE (@i < 10000)
BEGIN
INSERT INTO TestTable_DiskBased VALUES (@i, @i, @i) SET @i += 1
END
COMMIT
GO -- SQL Server logged more than 20000 log records, because we have 2 indexes
-- defined on the table (Clustered Index, Non-Clustered Index)
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE PartitionId IN
(
SELECT partition_id FROM sys.partitions
WHERE object_id = OBJECT_ID('TestTable_DiskBased')
)
GO

从系统函数的输出你可以看到,你有比20000多一点的日志记录。这是正确的,因为我们在表上有2个索引定义(1个聚集索引,1个非聚集索引)。
现在我们来看下用内存优化表(Memory Optimized Table)日志记录有啥改变。下列代码展示了为内存中OLTP数据库必备工作:我们只加了1个新的内存优化文件组(Memory Optimized File Group),给它加了个容器:
--Add MEMORY_OPTIMIZED_DATA filegroup to the database.
ALTER DATABASE InMemoryOLTP
ADD FILEGROUP InMemoryOLTPFileGroup CONTAINS MEMORY_OPTIMIZED_DATA
GO USE InMemoryOLTP
GO -- Add a new file to the previously created file group
ALTER DATABASE InMemoryOLTP ADD FILE
(
NAME = N'InMemoryOLTPContainer',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\InMemoryOLTPContainer'
)
TO FILEGROUP [InMemoryOLTPFileGroup]
GO
下一步我创建了1个新的内存优化表(Memory Optimized Table)。这里我在哈希索引上选择了16384的桶数来避免哈希碰撞(hash collisions)的可能。另外我在Col2和Col3列上创建了2个范围索引(Range Indexes)。
-- Creates a Memory Optimized table
CREATE TABLE TestTable_MemoryOptimized
(
Col1 INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 16384),
Col2 VARCHAR(100) COLLATE Latin1_General_100_Bin2 NOT NULL INDEX idx_Col2,
Col3 VARCHAR(100) COLLATE Latin1_General_100_Bin2 NOT NULL INDEX idx_Col3
) WITH
(
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
)
GO
在那个表上合计有3个索引(1个哈希索引(Hash Index)和2个范围索引(Range Indexes))。当你往表里插入10000条记录,传统表会生成近30000的日志记录——每个索引里每个插入1条日志。
-- Copy out the highest 'Current LSN'
SELECT * FROM sys.fn_dblog(NULL, NULL)
GO -- Insert 10000 records into the table
DECLARE @i INT = 0 BEGIN TRANSACTION
WHILE (@i < 10000)
BEGIN
INSERT INTO TestTable_MemoryOptimized VALUES (@i, @i, @i) SET @i += 1
END
COMMIT
GO -- Just a few log records!
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Current LSN] > '0000002f:000001c9:0032' -- Highest LSN from above
GO
但现在当你看事务日志时,你会看到10000条插入只生成了很少日志记录——这里是17条!
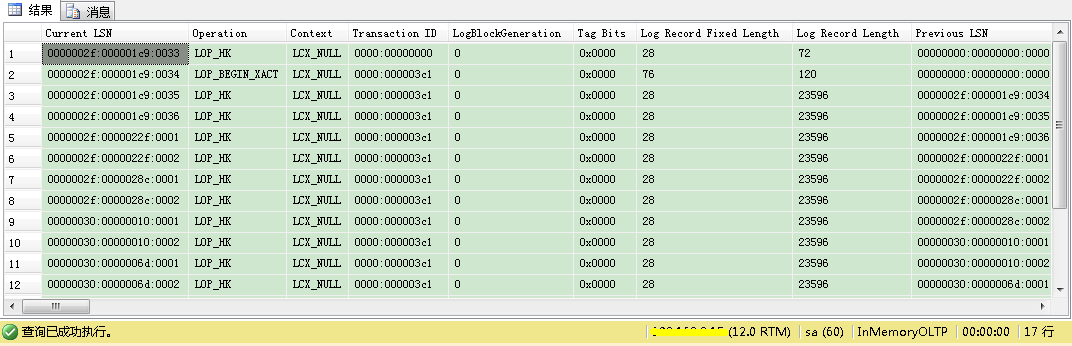
魔法发生在LOP_HK日志记录里。在这个特定日志记录里,内存中OLTP捆绑了多个修改到你的内存优化表(Memory Optimized Table)。你也可以通过使用sys.fn_dblog_xtp系统函数分解LOP_HK日志记录:
-- Let's look into a LOP_HK log record
SELECT * FROM sys.fn_dblog_xtp(NULL, NULL)
WHERE [Current LSN] > '0000002f:000001c9:0032' AND Operation = 'LOP_HK'
GO
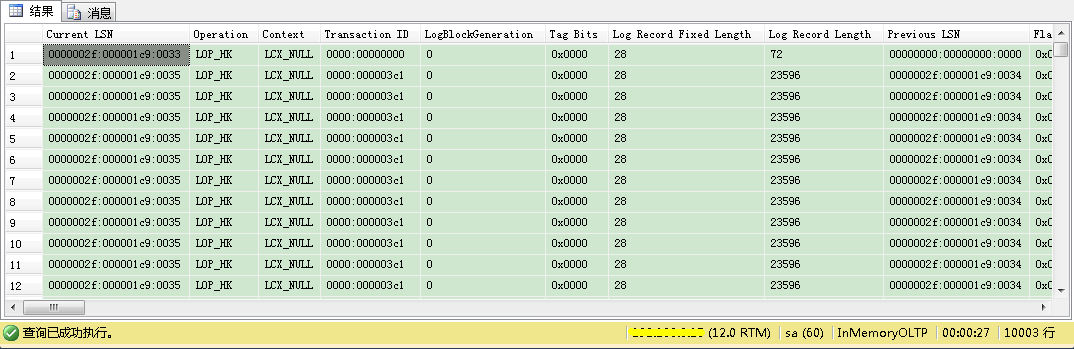
从图中你可以看到,内存中OLTP只生成了近10000条LOP_HK日志记录——在这个表上发生的每个逻辑插入对应1条记录。
小结
内存中OLTP提供你惊艳的性能提升,因为它是基于全新原理,例如MVCC和Lock-Free Data Structrues。另外它只生成少量事务日志记录,因为只有逻辑改变被记录写入事务日志。我希望这个文章已给你更好的理解:内存中OLTP如何提升你的事务日志吞吐量。
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2015/03/09/transaction-logging-memory-oltp-hekaton/
内存中OLTP(Hekaton)里的事务日志记录的更多相关文章
- SQL Server 内存中OLTP内部机制概述(三)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- 为什么我还不推荐内存中OLTP给用户
嗯,有些人在看玩这篇文章后会恨我,但我还是要说.1个月来我在内存中OLTP这个里领域里做了大量的工作,很多用户都请求使用这个惊艳的新技术.遗憾的是,关于内存中OLTP没有一个是真的令人激动的——看完你 ...
- 内存中OLTP(Hekaton)的排序警告
内存中OLTP是关于内存中的一切.但那只是对了一半.在今天的文章里我想给你展示下,当你从内存读取数据时,即使内存中OLTP也会引起磁盘活动.这里的问题是执行计划里,不正确的统计信息与排序(sort)运 ...
- SQL Server 内存中OLTP内部机制概述(一)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- 配置内存中OLTP文件组提高性能
在今天的文章里,我想谈下使用内存中OLTP的内存优化文件组来获得持久性,还有如何配置它来获得高性能.在进入正题前,我想简单介绍下使用你数据库里这个特定文件组,内存OLTP是如何获得持久性的. 内存中O ...
- 内存中OLTP与内存不足
我已经写了好几次内存中OLTP的文章和”为什么我还不推荐内存中OLTP给用户”.今天我想进一步谈下内存中OLTP背后的内存需求,还有如果你内存不够的话会发生什么. 一切都与内存有关! 我们都知道很久之 ...
- 内存中 OLTP - 常见的工作负荷模式和迁移注意事项(三)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<In-Memory OLTP – Comm ...
- 内存中 OLTP - 常见的工作负荷模式和迁移注意事项(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<In-Memory OLTP – Comm ...
随机推荐
- 搭建windows的solr6服务器(二)
首先搭建solr环境,如:solr6.0学习(一)环境搭建 修改各种配置文件. 1.修改solrhome下的solr.xml文件 注解掉zookeeper搭建集群配置,我们后面会采用master-sl ...
- Java多线程(3) Volatile的实现原理
Volatile变量 在程序设计中,尤其是在C语言.C++.C#和Java语言中,使用volatile关键字声明的变量或对象通常拥有和优化和(或)多线程相关的特殊属性.通常,volatile关键字用来 ...
- 完全图解scrollLeft,scrollWidth,clientWidth,offsetWidth 获取相对途径,滚动图片(网上找的,未经试验,但觉得比较好)
获取元素的位置属性可以通过 HTMLElement.offsetLeft HTMLElement.offsetTop 但是,这两个属性所储存的数值并不是该元素相对整个浏览器画布的绝对位置,而是相对于其 ...
- sqlite 的比较等运算是根据不同的值而不同的,并不是根据的字段类型,因为 sqlite 是弱类型字段
sqlite 的比较等运算是根据不同的值而不同的,并不是根据的字段类型,因为 sqlite 是弱类型字段 --------------------------------------------- ...
- iOS 日期处理 (Swift3.0 NSDate)
处理日期的常见情景 NSDate -> String & String -> NSDate 日期比较 日期计算(基于参考日期 +/- 一定时间) 计算日期间的差异 拆解NSDate ...
- distri.lua重写开源手游服务器框架Survive
Survive之前采用的是C+lua的设计方式,其中网关服务器全部由C编写,其余服务全部是C框架运行lua回调函数的方式编写游戏逻辑. 鉴于一般的手游对服务器端的压力不会太大,便将Survive用di ...
- Mac eclipse找不到source的解决办法
因为要搞hadoop,最终还是逃不过写java的命运... eclipse里想查具体函数源代码时,如果报错说找不到源: 试试ls -l which java,在这个目录周围看看能不能找到src.zip ...
- dbvis MySQL server version for the right syntax to use near 'OPTION SQL_SELECT_LIMIT=DEFAULT' at line 1
转自:http://www.cnblogs.com/_popc/p/4053593.html 今天使用数据库查询工具DBvis链接mysql数据库时, 发现执行如何sql语句, 都报如下错误: 后来想 ...
- 使用 Portable Class Library(可移植类库)开发 Universal Windows App
今天在这里跟大家聊聊关于 Windows Universal 应用夸平台的问题,首先Universal Windows App的定义相信大家已经有所了解了(如果你是一个刚刚接触 Universal A ...
- [英] 推荐 15 个 jQuery 选择框插件
jQuery Selectbox Plugins let you create beautiful and eye catching select box for your websites inst ...