关于Java序列化和Hadoop的序列化
import java.io.DataInput;
import java.io.DataOutput;
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable; import org.apache.hadoop.io.Writable; public class Test2 {
public static void main(String[] args) throws IOException {
Student stu = new Student(1, "张三");
FileOutputStream fileOutputStream = new FileOutputStream("d:/111");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(stu);
objectOutputStream.close();
fileOutputStream.close();
//我们一般只关注stu对象的id和name两个属性总共12个字节.但是Java的序列化到硬盘上的文件有175个字节.
//Java序列化了很多没有必要的信息.如果要序列化的数据有很多,那么序列化到磁盘上的数据会更多,非常的浪费.
//Hadoop没有使用Java的序列化机制.如果采用会造成集群的网络传输的时间和流量都集聚的增长.
//Hadoop中自己定义了一个序列化的接口Writable.
//Java序列化中之所以信息多是因为把 类之间的的继承多态信息都包含了. StuWritable stu2 = new StuWritable(1, "张三");
FileOutputStream fileOutputStream2 = new FileOutputStream("d:/222");
DataOutputStream dataOutputStream2 = new DataOutputStream(fileOutputStream2);
stu2.write(dataOutputStream2);
fileOutputStream2.close();
dataOutputStream2.close();
}
} class Student implements Serializable{
private Integer id;
private String name; public Student() {
super();
}
public Student(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setNameString(String name) {
this.name = name;
} } class StuWritable implements Writable{
private Integer id;
private String name; public StuWritable() {
super();
}
public StuWritable(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setNameString(String name) {
this.name = name;
} public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(name);
} public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
this.name = in.readUTF();
} }
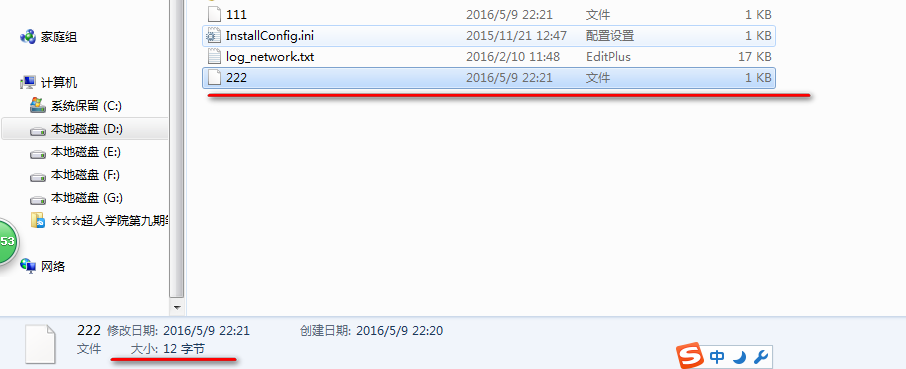
使用Java序列化接口对应的磁盘上的文件: 共175个字节

使用Hadoop序列化机制对应的磁盘文件: 共12字节
如果类中有继承关系:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable; import org.apache.hadoop.io.Writable; public class Test2 {
public static void main(String[] args) throws IOException {
//我们一般只关注stu对象的id和name两个属性总共12个字节.但是Java的序列化到硬盘上的文件有175个字节.
//Java序列化了很多没有必要的信息.如果要序列化的数据有很多,那么序列化到磁盘上的数据会更多,非常的浪费.
//Hadoop没有使用Java的序列化机制.如果采用会造成集群的网络传输的时间和流量都集聚的增长.
//Hadoop中自己定义了一个序列化的接口Writable.
//Java序列化中之所以信息多是因为把 类之间的的继承多态信息都包含了.再重新构建的时候可以保持原有的关系. StuWritable stu2 = new StuWritable(1, "张三");
stu2.setSex(true);
FileOutputStream fileOutputStream2 = new FileOutputStream("d:/222");
DataOutputStream dataOutputStream2 = new DataOutputStream(fileOutputStream2);
stu2.write(dataOutputStream2);
fileOutputStream2.close();
dataOutputStream2.close();
}
} class StuWritable extends Person implements Writable{
private Integer id;
private String name; public StuWritable() {
super();
}
public StuWritable(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setNameString(String name) {
this.name = name;
} public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeBoolean(super.isSex());
out.writeUTF(name);
} public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
super.setSex(in.readBoolean());
this.name = in.readUTF();
} } class Person{
private boolean sex; public boolean isSex() {
return sex;
} public void setSex(boolean sex) {
this.sex = sex;
} }
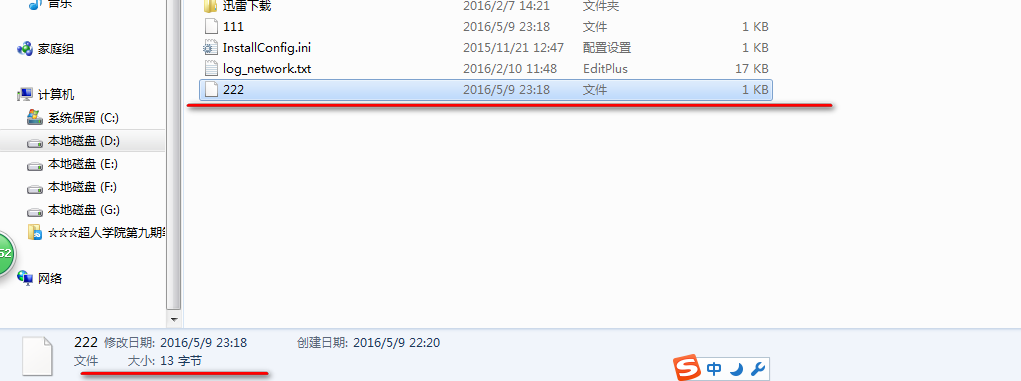
这样序列化到磁盘上的文件: 13个字节 多了一个boolean属性,相比上面多了一个字节.
如果实例化对象中含有类对象.
import java.io.DataInput;
import java.io.DataOutput;
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable; import org.apache.hadoop.io.Writable; public class Test2 {
public static void main(String[] args) throws IOException {
//我们一般只关注stu对象的id和name两个属性总共12个字节.但是Java的序列化到硬盘上的文件有175个字节.
//Java序列化了很多没有必要的信息.如果要序列化的数据有很多,那么序列化到磁盘上的数据会更多,非常的浪费.
//Hadoop没有使用Java的序列化机制.如果采用会造成集群的网络传输的时间和流量都集聚的增长.
//Hadoop中自己定义了一个序列化的接口Writable.
//Java序列化中之所以信息多是因为把 类之间的的继承多态信息都包含了.再重新构建的时候可以保持原有的关系. StuWritable stu2 = new StuWritable(1, "张三");
stu2.setSex(true);
FileOutputStream fileOutputStream2 = new FileOutputStream("d:/222");
DataOutputStream dataOutputStream2 = new DataOutputStream(fileOutputStream2);
stu2.write(dataOutputStream2);
fileOutputStream2.close();
dataOutputStream2.close();
}
} class StuWritable extends Person implements Writable{
private Integer id;
private String name;
private Student student; public StuWritable() {
super();
}
public StuWritable(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setNameString(String name) {
this.name = name;
} public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeBoolean(super.isSex());
out.writeUTF(name);
out.writeInt(student.getId());
out.writeUTF(student.getName());
} public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
super.setSex(in.readBoolean());
this.name = in.readUTF();
this.student = new Student(in.readInt(),in.readUTF());
} } class Person{
private boolean sex; public boolean isSex() {
return sex;
} public void setSex(boolean sex) {
this.sex = sex;
} }
如果我们Student中有个字段是Writable类型的.
怎么样序列化?
关于Java序列化和Hadoop的序列化的更多相关文章
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
- Hadoop 的序列化
1. 序列化 1.1 序列化与反序列化的概念 序列化:是指将结构化对象转化成字节流在网上传输或写到磁盘进行永久存储的过程 反序列化:是指将字节流转回结构化对象的逆过程 1.2 序列化的应用 序列化用于 ...
- Hadoop基础-序列化与反序列化(实现Writable接口)
Hadoop基础-序列化与反序列化(实现Writable接口) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.序列化简介 1>.什么是序列化 序列化也称串行化,是将结构化 ...
- 大数据框架hadoop的序列化机制
Java内建序列化机制 在Windows系统上序列化的Java对象,可以在UNIX系统上被重建出来,不需要担心不同机器上的数据表示方法,也不需要担心字节排列次序. 在Java中,使一个类的实例可被序列 ...
- java中可定制的序列化过程 writeObject与readObject
来源于:[http://bluepopopo.iteye.com/blog/486548] 什么是writeObject 和readObject?可定制的序列化过程 这篇文章很直接,简单易懂.尝试着翻 ...
- java io系列06之 序列化总结(Serializable 和 Externalizable)
本章,我们对序列化进行深入的学习和探讨.学习内容,包括序列化的作用.用途.用法,以及对实现序列化的2种方式Serializable和Externalizable的深入研究. 转载请注明出处:http: ...
- spring mvc返回json字符串数据,只需要返回一个java bean对象就行,只要这个java bean 对象实现了序列化serializeable
1.spring mvc返回json数据,只需要返回一个java bean对象就行,只要这个java bean 对象实现了序列化serializeable 2. @RequestMapping(val ...
- Java中对文件的序列化和反序列化
public class ObjectSaver { public static void main(String[] args) throws Exception { /*其中的 D:\\objec ...
- Java复习——I/O与序列化
File类 java.io.File只用于表示文件(目录)的信息(名称.大小等),不能用于文件内容的访问,我们可以通过通过给其构造函数传一个路径来构建以文件,传入的路径名有一个小问题,就是Window ...
随机推荐
- Caroline--chochukmo
Caroline--chochukmo 虾米试听 Caroline, Caroline, Caroline, you pulled me into so deep down(内心深处). Caroli ...
- Hibernate之Session缓存以及操作Session缓存的相关方法
1.Session概述 A.Session 接口是 Hibernate 向应用程序提供的操纵数据库的最主要的接口, 它提供了基本的保存, 更新, 删除和加载 Java 对象的方法. B. Sessio ...
- codeforces 624B Making a String
Making a String time limit per test 1 second memory limit per test 256 megabytes input standard inpu ...
- [iOS 多线程 & 网络 - 1.1] - 多线程NSThread
A.NSThread的基本使用 1.创建和启动线程 一个NSThread对象就代表一条线程创建.启动线程NSThread *thread = [[NSThread alloc] initWithTar ...
- [C语言 - 4] 指针
存放变量地址的变量 int a = 1; int *p; p = &a; 在64位系统中,占用8个字节 直接引用 间接引用 *p : 指针指向的变量的值 不要使用未初始化的指针 1 ...
- ajax。表单
JQuery读书笔记--JQuery-Form中的ajaxForm和ajaxSubmit的区别JQuery中的ajaxForm和ajaxSubmit使用差不多功能也差不多.很容易误解. 按照作者的解释 ...
- MES系统的有用存储过程
USE [ChiefmesNEW]GO/****** Object: StoredProcedure [dbo].[st_WMS_ImportStockInBill] Script Date: 10/ ...
- Linq to SQL 绑定 ComboBox
最近学习Linq to SQL,发现Linq是一个开发轻量数据库的好东西,大大简化了数据连接.查询过程.但是在绑定ComBoBox的时间发现了一个问题:Linq查询后得到的数据tolist后,只能实现 ...
- C#中反射的使用(How to use reflect in CSharp)(2)
在上一篇里,我们叨逼了好多如何获取到程序集里的对象,但是对象有了,还不知道怎么调,OK,下面开始干这个对象: 首先,我们对上一篇的对象做了一些修改,以适应多种情况: using System; usi ...
- 教你50招提升ASP.NET性能(二十):7条便利的ViewState技巧
(32)Seven handy ViewState tips 招数32: 7条便利的ViewState技巧 Every time I have to deal with a classic ASP.N ...