UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络
1. 主要思路
“UFLDL 卷积神经网络”主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像的每个小的patch矩阵应用相同的权值来计算隐藏层特征,称为卷积特征提取;第二,对计算出来的特征矩阵做“减法”,把特征矩阵纵横等分为多个区域,取每个区域的平均值(或最大值)作为输出特征,称为池化。这样做的原因主要是为了降低数据规模,对于8X8的图像输入层有64个单元,而100X100的图像,输入单元有1E4个,相同特征个数下需要训练的权重参数个数呈平方倍增加。真实图像大到一定程度,将会很难运行训练。所以卷积特征提取步骤中,使用在小尺寸patch上获得的权重参数作为共享的权重对大尺寸图像每个小patch做卷积运算,来达到前向传播的作用,结果中包含大图像每个小邻域的特征。而池化步骤中对过大的特征矩阵做平均、或取最大值更是明显的“下采样”特征矩阵了。
2. 卷积和前向传播的关系

我们知道对于一个典型的神经网络,训练到的权重参数维度表示为\(W^{(1)}_{hiddenSize \times inputSize} , b^{(1)}_{hiddenSize \times 1} ; _{hiddenSize=patchDim \times patchDim}\),在原文“UFLDL 卷积神经网络”中,所描述的过程是 “取\(W^{(1)}\)与大图像的每个 $ patchDim \times patchDim $ 子图像做乘法,对 \(f_{convoled}\) 值做卷积,就可以得到卷积后的矩阵” 。没有解释清楚经典的前向传播为什么变成了图像卷积的,以及谁和谁卷积。 接下来我们来慢慢理解一下这个转变过程。
对于大图像\(X_{r \times c}\)我们设想的是取每一个子矩阵\(X_{patchDim \times patchDim}\)和\(W^{(1)}\)按照小尺寸图像来做前向传播,所以共需要做\((r-patchDim)\times(c-patchDim)\)次前向传播,每一次表示为\(h_{hiddenSize \times 1}=\sigma( W^{(1)}*X_{patchDim \times patchDim} (:)+b^{(1)}_{hiddenSize \times 1})\). 所以说会得到\(hiddenSize \times (r-patchDim)\times(c-patchDim)\)的特征矩阵。接下来需要做一个交换,才能看出来怎么用卷积函数;计算\(h_{hiddenSize \times 1}\)的步骤里\(W^{(1)}\)的每一行和和\(X_{patchDim \times patchDim}\)转成一列向量后进行点积,可以和做\((r-patchDim)\times(c-patchDim)\)次前向传播顺序交换,也就是说取\(W^{(1)}\)的每一行转成\(patchDim\times patchDim\)的矩阵和\(X_{r \times c}\)的每一个子矩阵\(X_{patchDim \times patchDim}\)做点乘求和,这不正好是二维卷积吗!,是的,卷积就是这样来的,本质上是对大图像每个小邻域的前向传播,正好运用了二维矩阵卷积这个工具。
3. 代码实现
有了前面的认识,我们再来看卷积计算的实现代码, 有两点需要注意的:
feature = W(featureNum,:,:,channel);这一行代表取出\(W^{(1)}_{hiddenSize \times inputSize}\)的每一行,然后用二维卷积函数对每张图片im = squeeze(images(:, :, channel, imageNum));做前向传播conv2(im, feature, 'valid')。- 为什么要对每张图片的RGB三个通道的卷积累加呢? 这是因为训练权重时\(W^{(1)}_{hiddenSize \times inputSize}\)的\(inputSize\)是把RGB通道展开变成一维向量后训练出来的,对大图像的小patch做前向传播\(W^{(1)}_{hiddenSize \times inputSize}\)的每一行与\(X_{patchDim \times patchDim}\)做点积是RGB三段的累加,所以需要累加三个通道的特征响应,即
convolvedImage = convolvedImage + conv2(im, feature, 'valid');
池化部分比较直观,不再展开描述,根据cnnExercise.m步骤,除了复用原来的稀疏自编码、softmax、栈式自编码部分代码,我们要编写cnnConvolve.m,cnnPool.m,整体代码详见https://github.com/codgeek/deeplearning
function convolvedFeatures = cnnConvolve(patchDim, numFeatures, images, W, b, ZCAWhite, meanPatch)
%cnnConvolve Returns the convolution of the features given by W and b with
%the given images
%
% Parameters:
% patchDim - patch (feature) dimension
% numFeatures - number of features
% images - large images to convolve with, matrix in the form
% images(r, c, channel, image number)
% W, b - W, b for features from the sparse autoencoder
% ZCAWhite, meanPatch - ZCAWhitening and meanPatch matrices used for
% preprocessing
%
% Returns:
% convolvedFeatures - matrix of convolved features in the form
% convolvedFeatures(featureNum, imageNum, imageRow, imageCol)
numImages = size(images, 4);
imageDim = size(images, 1);
imageChannels = size(images, 3);
% -------------------- YOUR CODE HERE --------------------
% Precompute the matrices that will be used during the convolution. Recall
% that you need to take into account the whitening and mean subtraction
% steps
W = W * ZCAWhite;% W *(ZCAWhite *(X - meanPatch)) equals to (W *ZCAWhite)*X - (W *ZCAWhite)*meanPatch;
substractMean = W * meanPatch;
W = reshape(W,numFeatures, patchDim, patchDim, imageChannels);
convolvedFeatures = zeros(numFeatures, numImages, imageDim - patchDim + 1, imageDim - patchDim + 1);
for imageNum = 1:numImages
for featureNum = 1:numFeatures
convolvedImage = zeros(imageDim - patchDim + 1, imageDim - patchDim + 1);
for channel = 1:imageChannels
% Obtain the feature (patchDim x patchDim) needed during the convolution
feature = W(featureNum,:,:,channel); % each row of W is one of numFeatures that has learned
% ------------------------
% Flip the feature matrix because of the definition of convolution, as explained later
feature = rot90(squeeze(feature),2);
% Obtain the image
im = squeeze(images(:, :, channel, imageNum));
% Convolve "feature" with "im", adding the result to convolvedImage
% be sure to do a 'valid' convolution
% ---- YOUR CODE HERE ----
convolvedImage = convolvedImage + conv2(im, feature, 'valid');% (imageDim - patchDim + 1) X (imageDim - patchDim + 1)
% ------------------------
end
% Subtract the bias unit (correcting for the mean subtraction as well)
% Then, apply the sigmoid function to get the hidden activation
% ---- YOUR CODE HERE ----
% meanPatch: numFeatures X 1
convolvedImage = sigmoid(convolvedImage + b(featureNum) - substractMean(featureNum));
% ------------------------
% The convolved feature is the sum of the convolved values for all channels
convolvedFeatures(featureNum, imageNum, :, :) = convolvedImage;
end
end
end
function sigm = sigmoid(x)
sigm = 1 ./ (1 + exp(-x));
end
4.图示与结果
数据集来自STL-10 dataset. 以及我们在前一节UFLDL深度学习笔记 (五)自编码线性解码器中训练得到的该数据集下采样的8X8 patch上的特征参数STL10Features.mat,下采样前后图片本身对比如下。



设定与练习说明相同的参数,输入每个图像为64X64X3的彩色图片,共有四个分类 (airplane, car, cat, dog)。运行代码主文件cnnExercise.m 可以看到预测准确率为80.4%。与练习的标准结果吻合。分类的准确其实并不高,一方面原因在于下采样倍率较大,下采样后的图片人眼基本无法分类,而通过特征学习、进一步进行卷积网络学习,仍然可以达到一定的准确率。
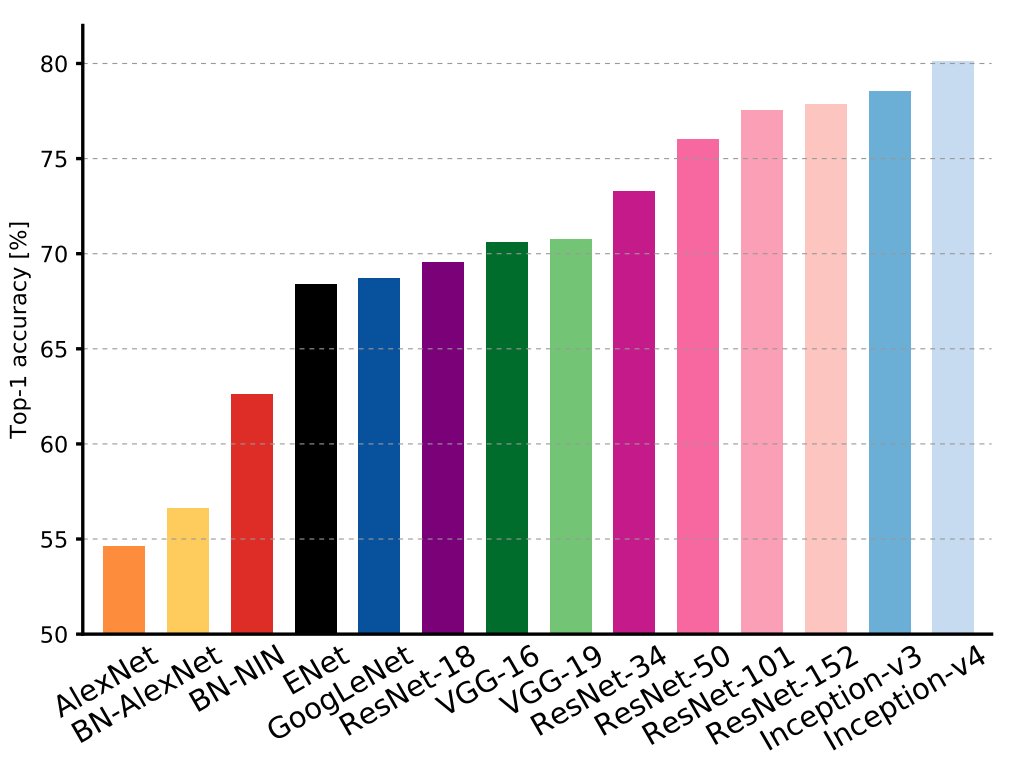
我们看一下在ImageNet 全量数据集上分类准确率数据,统计数据来来自An Analysis of Deep Neural Network Models for Practical Applications. 截止到2017年初的统计,最好的深度神经网络(DNN)算法分类准确率也不过80%,我们怎么轻松就达到80%了,吴恩达老师是不是也太牛了? 不过不要高兴太早了,上述的实验仅仅使用了四个图片类型的数据集,连STL10上面的10种类别还没用完,更不用说ImageNet上更多的种类了~ O(∩_∩)O哈哈~
下一阶段准备用STL10的全量10种图片,以及ImageNet上的数据集进行算法训练。STL10包含100000张未标注图片,500张训练图片、800张测试图片。而ImageNet的数据更大包含14,197,122 张图片,共有21841个同类集合。包含SIFT特征的图片为 1.2 million,可以理解为有标注图片数量。 相信不断增加的海量数据会不断提高分类算法的准确率!
UFLDL深度学习笔记 (六)卷积神经网络的更多相关文章
- 深度学习笔记 (一) 卷积神经网络基础 (Foundation of Convolutional Neural Networks)
一.卷积 卷积神经网络(Convolutional Neural Networks)是一种在空间上共享参数的神经网络.使用数层卷积,而不是数层的矩阵相乘.在图像的处理过程中,每一张图片都可以看成一张“ ...
- UFLDL深度学习笔记 (五)自编码线性解码器
UFLDL深度学习笔记 (五)自编码线性解码器 1. 基本问题 在第一篇 UFLDL深度学习笔记 (一)基本知识与稀疏自编码中讨论了激活函数为\(sigmoid\)函数的系数自编码网络,本文要讨论&q ...
- CNN学习笔记:卷积神经网络
CNN学习笔记:卷积神经网络 卷积神经网络 基本结构 卷积神经网络是一种层次模型,其输入是原始数据,如RGB图像.音频等.卷积神经网络通过卷积(convolution)操作.汇合(pooling)操作 ...
- UFLDL深度学习笔记 (一)反向传播与稀疏自编码
UFLDL深度学习笔记 (一)基本知识与稀疏自编码 前言 近来正在系统研究一下深度学习,作为新入门者,为了更好地理解.交流,准备把学习过程总结记录下来.最开始的规划是先学习理论推导:然后学习一两种开源 ...
- UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化
UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化 主要思路 前面几篇所讲的都是围绕神经网络展开的,一个标志就是激活函数非线性:在前人的研究中,也存在线性激活函数的稀疏编码,该方法试图直接学习数据的特 ...
- UFLDL深度学习笔记 (四)用于分类的深度网络
UFLDL深度学习笔记 (四)用于分类的深度网络 1. 主要思路 本文要讨论的"UFLDL 建立分类用深度网络"基本原理基于前2节的softmax回归和 无监督特征学习,区别在于使 ...
- UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
UFLDL深度学习笔记 (二)Softmax 回归 本文为学习"UFLDL Softmax回归"的笔记与代码实现,文中略过了对代价函数求偏导的过程,本篇笔记主要补充求偏导步骤的详细 ...
- UFLDL深度学习笔记 (三)无监督特征学习
UFLDL深度学习笔记 (三)无监督特征学习 1. 主题思路 "UFLDL 无监督特征学习"本节全称为自我学习与无监督特征学习,和前一节softmax回归很类似,所以本篇笔记会比较 ...
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
随机推荐
- 在SQL Server中查看对象依赖关系
原文 在SQL Server中查看对象依赖关系 Viewing object dependencies in SQL Server Deleting or changing objects may ...
- 【XStream】xml和java实体的相互转化
1.pom.xml <!-- xstream xml和Java对象转化 --> <dependency> <groupId>xstream</groupId& ...
- 初试百度地图API
第一次使用百度地图API来定位并显示,参照了官网2.1.0版本demo里的DemoApplication和LocationOverlayDemo两个类来写,整了半天显示一片空白(图一),然后郁闷了半天 ...
- 彻底解决DZ大附件上传问题
个. 注意:很多人遇到修改php.ini后重应WEB服务后仍然不能生效.这种情况应该先确认一下所改的php.ini是不是当前PHP所使用的.您可以在WEB目录下建立一个php文件,内容很简单就一句话& ...
- boost/config.hpp文件详解
简要概述 今天突发奇想想看一下boost/config.hpp的内部实现,以及他有哪些功能. 这个头文件都有一个类似的结构,先包含一个头文件,假设为头文件1,然后包含这个头文 件中定义的宏.对于头文件 ...
- How to support both ipv4 and ipv6 address for JAVA code.
IPv6 have colon character, for example FF:00::EEIf concatenate URL String, IPv6 URL will like: http: ...
- 批量删除Redis中的key
bin/redis-cli -h 192.168.46.151 -p 6379 keys "rulelist*" | xargs bin/redis-cli -h 192.168 ...
- JAVA经常使用集合框架使用方法具体解释基础篇二之Colletion子接口List
接着上一篇,接着讲讲集合的知识.上一篇讲了Collection接口.它能够说是集合的祖先了,我们这一篇就说说它的子孙们. 一.Collection的子接口 List:有序(存入和取出的顺序一致).元素 ...
- 微信小程序 - 文字换行问题
css word-break: break-all;
- python——操作符重载(重要)
类可以重载python的操作符 旧认识:__X__的名字 是系统定义的名字:是python特殊方法专用标识. 操作符重载使我们的对象与内置的一样.__X__的名字的方法是特殊的挂钩(hook) ...