Ubuntu16.04 hadoop 伪分布式 的文件配置
首先需要完成java环境的配置,这里就省略了。
完成 hadoop 伪分布(pesudo distribution),只需配置下面 五 个文件即可:
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
这些配置文件都在解压后的hadoop目录中的 etc/hadoop 目录下,下面是它们的具体作用和配置:
1 hadoop-env.sh
这个用来配置 Java 环境的路径,在hadoop-env.sh中找到这一行:
export JAVA_HOME=
并将等号后面的内容替换成自己的java环境路径即可,如果不确定,执行sudo update-alternatives --config java 就能看到了,如果安装了多个java环境,可以从这儿选择某一个,每个条目的路径就是所需的java环境了, 比如我的执行结果是这样的:
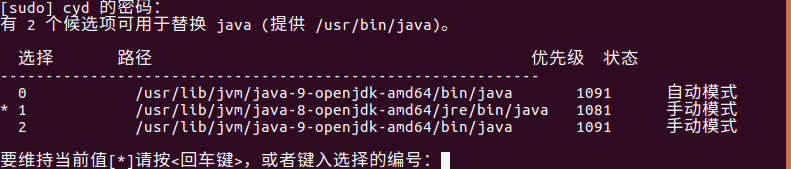
我目前用的是第二个条目的java环境,取bin之前的路径就是: /usr/lib/jvm/java-8-openjdk-amd64/jre
2 core-site.xml
指定HDFS的通信地址和缓存存储的路径:
在core-site.xml的 configure 中分别加入这些片段,如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_installs/tmp</value>
</property>
</configuration>
3 hdfs-site.xml
指定hdfs的副本数量,这里就假设是 1 个:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> </property>
</configuration>
4 yarn-site.xml
yarn 是hadoop的统一资源管理器:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
5 mapred-site.xml
mapred是一种计算模型, 这里就指定 它使用yarn 来管理资源
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
这里要把原来的mapred-site.xml.template 改成 mapred-site.xml 再编辑.
6 参考博客:
https://www.cnblogs.com/gyouxu/p/4183417.html
Ubuntu16.04 hadoop 伪分布式 的文件配置的更多相关文章
- Ubuntu16.04下伪分布式环境搭建之hadoop、jdk、Hbase、phoenix的安装与配置
一.准备工作 安装包链接: https://pan.baidu.com/s/1i6oNmOd 密码: i6nc 环境准备 修改hostname: $ sudo vi /etc/hostname why ...
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Hadoop伪分布式环境搭建+Ubuntu:16.04+hadoop-2.6.0
Hello,大家好 !下面就让我带大家一起来搭建hadoop伪分布式的环境吧!不足的地方请大家多交流.谢谢大家的支持 准备环境: 1, ubuntu系统,(我在16.04测试通过.其他版本请自行测试, ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Linux下配置Hadoop伪分布式环境
1. 准备Linux环境 提示:我用的系统是CentOS 6.4. 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host- ...
- Ubuntu15.10下Hadoop2.6.0伪分布式环境安装配置及Hadoop Streaming的体验
Ubuntu用的是Ubuntu15.10Beta2版本,正式的版本好像要到这个月的22号才发布.参考的资料主要是http://www.powerxing.com/install-hadoop-clus ...
- Hadoop伪分布式模式搭建
title: Hadoop伪分布式模式搭建 Quitters never win and winners never quit. 运行环境: Ubuntu18.10-server版镜像:ubuntu- ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式平台搭建(centos 6.3)
最近要写一个数据量较大的程序,所以想搭建一个hbase平台试试.搭建hbase伪分布式平台,需要先搭建hadoop平台.本文主要介绍伪分布式平台搭建过程. 目录: 一.前言 二.环境搭建 三.命令测试 ...
随机推荐
- CMD当前代码页修改
python3.x在程序开发中统一的编码是 UTF-8,但是进行交互式编程的时候会经常遇到乱码问题,这是因为Window cmd的默认编码是GBK.与程序采用的 UTF-8 不一致造成的中文及特殊字符 ...
- 获取n天后的日期
getDateAfter_n(days){ let date = new Date(); date.setDate(date.getDate() + days); let yearStr = date ...
- Spark 概述
Spark 是什么? ● 官方文档解释:Apache Spark is a fast and general engine for large-scale data processing. 通俗的理解 ...
- shell脚本之前的基础知识
日常的linux系统管理工作中必不可少的就是shell脚本,如果不会写shell脚本,那么你就不算一个合格的管理员.目前很多单位在招聘linux系统管理员时,shell脚本的编写是必考的项目.有的单位 ...
- Docker:安装部署RabbitMQ
前言 今天原本想讲解SpringBoot集成RabbitMQ的,临近开始写时才发现家里的电脑根本没有安装RabbitMQ呀.这下只好利用已有的阿里云服务器,直接Docker安装一下了,顺道记录下,算是 ...
- 学习《CSS选择器Level-4》不完全版
1 概述 1.1 前言 选择器是CSS的核心组件.本文依据W3C的Selectors Level 4规范,概括总结了Level1-Level4中绝大多数的选择器,并做了简单的语法说明及示例演示.希望对 ...
- ArrayList与Vector区别
ArrayList与Vector区别表 ArrayList Vector 1.实现原理:采用动态对象数组实现,默认构造方法创建了一个空数组 1.实现原理:采用动态数组对象实现,默认构造方法创建了一个大 ...
- ubuntu下virtualbox的卸载
本想在ubuntu下virtualbox,可惜出错了,需要卸载后再安装,只能百度拼凑后再安装: 1.首先是执行删除命令:sudo apt-get remove virtualbox*( 这样就不用去查 ...
- pat甲级1016
1016 Phone Bills (25)(25 分) A long-distance telephone company charges its customers by the following ...
- 使用JDBC操作SAP云平台上的HANA数据库
本文假设您对JDBC(Java Database Connectivity)有最基本的了解.您也可以将其同ADBC(ABAP Database Connectivity)做对比,细节请参考我的博客AD ...