Spark Streaming 交互 Kafka的两种方式
Spark Streaming 交互 Kafka的两种方式的更多相关文章
- Spark Streaming连接Kafka的两种方式 direct 跟receiver 方式接收数据的区别
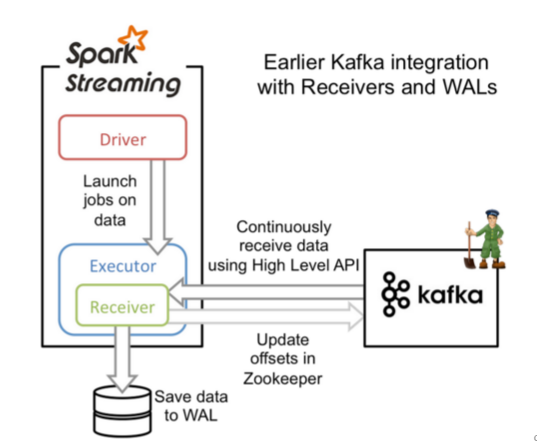
Receiver是使用Kafka的高层次Consumer API来实现的. Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming ...
- sparkStreaming读取kafka的两种方式
概述 Spark Streaming 支持多种实时输入源数据的读取,其中包括Kafka.flume.socket流等等.除了Kafka以外的实时输入源,由于我们的业务场景没有涉及,在此将不会讨论.本篇 ...
- spark streaming集成kafka接收数据的方式
spark streaming是以batch的方式来消费,strom是准实时一条一条的消费.当然也可以使用trident和tick的方式来实现batch消费(官方叫做mini batch).效率嘛,有 ...
- spark-streaming-连接kafka的两种方式
推荐系统的在线部分往往使用spark-streaming实现,这是一个很重要的环节. 在线流程的实时数据一般是从kafka获取消息到spark streaming spark连接kafka两种方式在面 ...
- spark application提交应用的两种方式
bin/spark-submit --help ... ... --deploy-mode DEPLOY_MODE Whether to launch the driver program loc ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
- spark streaming 接收kafka消息之一 -- 两种接收方式
源码分析的spark版本是1.6. 首先,先看一下 org.apache.spark.streaming.dstream.InputDStream 的 类说明: This is the abstrac ...
- Spark Streaming消费Kafka Direct方式数据零丢失实现
使用场景 Spark Streaming实时消费kafka数据的时候,程序停止或者Kafka节点挂掉会导致数据丢失,Spark Streaming也没有设置CheckPoint(据说比较鸡肋,虽然可以 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
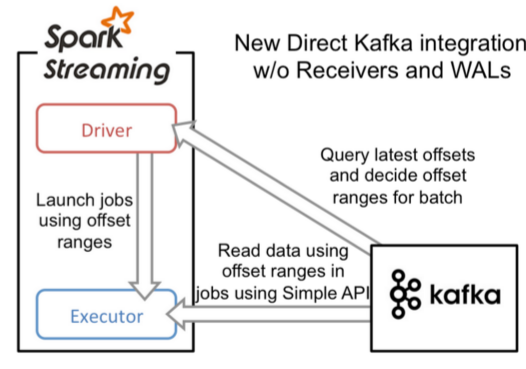
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
随机推荐
- 集成Springboot+MyBatis+JPA
1.前言 Springboot最近可谓是非常的火,本人也在项目中尝到了甜头.之前一直使用Springboot+JPA,用了一段时间发现JPA不是太灵活,也有可能是我不精通JPA,总之为了多学学Spri ...
- .Net程序员学习Linux最简单的方法(转载)
有很多关于Linux的书籍.博客.大多数都会比较“粗暴“的将一大堆的命令塞给读者,从而使很多.NET程序员望而却步.未入其门就路过了. 所以我设想用一种更为平滑的学习方式, 就是在学习命令时,先用纯语 ...
- Python函数(1)
一.Python函数介绍 函数时组织好的,可重复的,用来实现单一,或相关联功能的代码段. 函数的使用原则时先定义,后调用:事先准备工具的过程即函数的定义,遇到应用场景拿来当工具用即函数的调用. 函数的 ...
- BZOJ4245: [ONTAK2015]OR-XOR(前缀和)
题意 题目链接 Sol 又是一道非常interesting的题目 很显然要按位考虑 因为最终答案是xor之后or,所以分开之后之后这样位上1的数量是一定是偶数,否则直接加到答案里面 同时,这里面有些部 ...
- MongoDB之mongodb.cnf配置
# mongodb3.2.1 的主配置文件,将此文件放置于 mongodb3.2.1/bin 目录下 # hapday 2016-01-27-16:55 start # 数据文件存放目录 dbpath ...
- <Android开源库 ~ 1> GitHub Android Libraries Top 100 简介
转载自GitHub Android Libraries Top 100 简介 本项目主要对目前 GitHub 上排名前 100 的 Android 开源库进行简单的介绍, 至于排名完全是根据 GitH ...
- java:数据库操作JDBC
JDBC详解:https://www.cnblogs.com/erbing/p/5805727.html JDBC存储过程,事务管理,数据库连接池,jdbc的封装框架:https://www.cnbl ...
- 01、Spark安装与配置
01.Spark安装与配置 1.hadoop回顾 Hadoop是分布式计算引擎,含有四大模块,common.hdfs.mapreduce和yarn. 2.并发和并行 并发通常指针对单个节点的应对多个请 ...
- 掌握这些技能玩转iOS
近一年来,苹果iOS/OS X频繁被爆出重大安全漏洞,攻击者可以通过漏洞窃取多达上千个应用的密码.这些漏洞一旦被黑客掌握.利用,后果不堪设想. 好在这些漏洞的发现者还是有节操的,他们都将这些漏洞汇报给 ...
- Seafile开源私有云自定义首页Logo图片
Seafile是一个开源.专业.可靠的云存储平台:解决文件集中存储.共享和跨平台访问等问题,由北京海文互知网络有限公司开发,发布于2012年10月:除了一般网盘所提供的云存储以及共享功能外,Seafi ...